
MapR-XD : l’arme de MapR pour le marché du stockage
Du monde Hadoop au stockage il n’y a qu’un pas que MapR franchit avec MapR-XD. Cette évolution naturelle de MapR-FS, qui supporte les API de S3, permet de cibler les entreprises souhaitant utiliser MapR uniquement pour des scenarii liés au stockage de fichiers et de conteneurs.

« On évite de créer des clusters pour différents types de technologies, Hadoop, Stream ou NoSQL », avait indiqué Yann Aubry, en charge des activités de MapR pour l’Europe du nord et du sud, lors d’un entretien avec la rédaction. MapR continue donc de jouer sa partition. Cet acteur historique du monde Hadoop a ajouté un composant de stockage distribué, Cloud ou pas, à son catalogue d’offres, l’écartant un peu plus du marché pur d’Hadoop et de l’analytique et le faisant entrer de plain-pied dans celui du stockage logiciel (Software-Defined Storage).
MapR-XD, nom de cette offre, est en fait une évolution de MapR-FS, un système de fichiers compatible NFS/POSIX et HDFS, placé au cœur de la distribution Hadoop de la société depuis sa création. Ce système de fichiers constitue l’une des particularités de MapR, face à ses concurrents directs (du monde Hadoop) que sont Cloudera ou Hortonworks. Surtout, MapR-FS constituait jusqu’alors une brique indéboulonnable de la Converged Data Platform de MapR. Une plateforme dont la vocation est d’associer plusieurs technologies au-dessus d’Hadoop pour répondre à différents cas d’usage en entreprise : stockage de fichiers, analytique et Machine Learning, gestion de flux de données, et base de données NoSQL (MapR-DB, bâtie sur HBase).
Mais jusqu’alors, MapR-FS faisait partie de cet édifice. Avec MapR-XD, MapR compte désormais bâtir une offre résolument stockage à laquelle, éventuellement, on pourra greffer la Converged Data Platform si les processus analytiques sont nécessaires. Le tout sur une unique plateforme, avec la même technologie d’accès.
Un MapR-FS sous stéroïdes, dopé à S3 et au tiering
« Jusqu’alors, on ne pouvait pas acheter MapR-FS sans Hadoop », commente Tugdual Grall, évangéliste technique chez MapR. Alors que justement, certaines entreprises utilisaient MapR uniquement comme une plateforme de stockage. « Nos clients existants ont de plus en plus de besoin de stockage en volume. Les entreprises utilisaient MapR que pour du stockage », ajoute-t-il, citant l’exemple de certaines banques. Toutefois, ces entreprises qui travaillent avec de la donnée « n’ont pas forcément besoin de fonctions analytiques ». On entre bien dans le stockage pur.
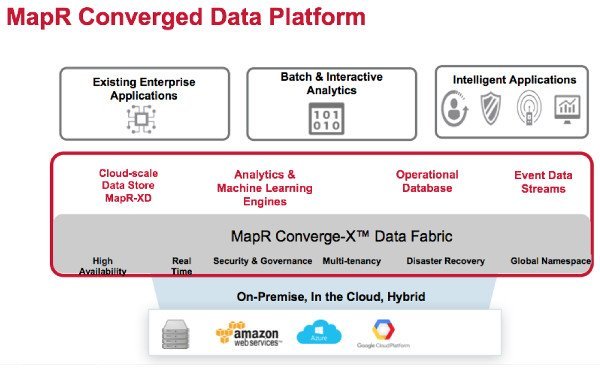
Avec MapR-XD, l’intérêt est de pouvoir disposer d’un système de stockage distribué, multi-datacenter, et multi-cloud (Azure, AWS) et, surtout, doué de capacités de tiering qui exploitent cet environnement distribué. MapR-XD a donc pour vocation de rapprocher le cycle de vie du stockage (de l’infrastructure) de celui de la donnée. Ce qui peut paraître logique, mais pas une évidence car les équipes infrastructure échangent rarement avec celles en charge des données, constate en substance Tugdual Grall.
Dans ce contexte MapR-XD inclut également le support de S3 aux autres API (HDFS, Posix et NFS, pour rappel) permettant donc d’inclure le stockage objet Cloud d’AWS à son système de stockage et à sa politique de tiering. Cela est également accentué par le fait que MapR-XD supporte à la fois le stockage sur disque ou sur Flash. Ce qui permet « d’avoir une infrastructure flexible », explique le responsable. « Flash est par exemple pratique pour les architectures multi-conteneurs et les microservices », où la vitesse de démarrage/arrêt/suppression est clé. Car outre les fichiers, MapR-XD cible également le stockage pour conteneurs – il intègre en fait l’outil de stockage persistant pour conteneurs de la marque (Persistent Application Client Containers – PACC).
Pour l’heure, MapR s’est associé avec Cisco et ses serveurs UCS, mais la société confirme également travailler avec la plupart des fournisseurs dont HP.
Pour approfondir sur Stockage en Cloud
-
![]()
MapR se vend à HPE : vers l’hiver des pure-players du Big Data
Par: Brian McKenna
-
![]()
MapR dote sa base NoSQL d’index secondaires
Par: Cyrille Chausson
-
![]()
Orbit Cloud Suite : MapR propose le tiering automatisé multi-Cloud et hybride
Par: Cyrille Chausson
-
![]()
L’essentiel sur MapR et sa déclinaison d'Hadoop
Par: Abie Reifer



