GTC 2024 : Nvidia pousse sa stratégie du « tout-en-un »
Lors de la GTC 2024, l’éditeur et spécialiste du GPU a complété son offre logicielle en présentant des « microservices », plus précisément une collection d’images de conteneurs préparées contenant des outils consacrés à l’entraînement, mais surtout à l’inférence de grands modèles de langage.
Outre l’architecture Blackwell, Nvidia a annoncé le lancement de Nvidia AI Enterprise 5.0. Dans la note de sortie, l’on note la prise en charge des GPU H800 SXM5, RTX 5880 Ada et des Nvidia H200 CG1 (96 et 144 Go de VRAM). La plateforme prend en charge l’hyperviseur KVM lié à RHEL 9.3 et l’orchestrateur Kubernetes Charmed 1.28. Par ailleurs, AI Enterprise 5.0 introduit la prise en charge des vGPU pour la gamme H100 en dehors des serveurs DGX (préalablement prise en charge en mode bare-metal).
Surtout, Nvidia a (re) mis en avant sa collection de « microservices ».
Les « microservices » permettent aux entreprises de créer et de déployer des applications personnalisées sur leurs plateformes.
Ils sont construits sur Nvidia CUDA, la véritable raison du succès commercial du géant fabless. C’est une plateforme de calcul et de programmation bas-niveau qui fonctionne sur tous les GPU de Nvidia, et ce, officiellement depuis 2007. Elle a été massivement adoptée par la communauté des data scientists si bien que les plus grands frameworks open source s’appuient majoritairement (initialement ou exclusivement) sur un socle propriétaire.
Dans sa documentation foisonnante, le champion des GPU met en lumière plusieurs collections de « microservices ».
La première se nomme CUDA-X. Cette gamme d’outils prépackagés est virtuellement séparée en deux catégories. CUDA-X AI rassemble un ensemble de librairies propriétaires, open source et tierces consacrées aux opérations de traitements de données, de calcul et de communication entre les GPU pour la data science et l’IA. CUDA-X HPC, lui, propose les mêmes bibliothèques et d’autres pour les charges de travail traditionnelles du HPC (simulation, prévision à large échelle, effets spéciaux à large échelle).
À partir de ces outils « de fondation », Nvdia met au point d’autres « microservices », comme CuOpt. Il s’agit d’un point de terminaison pour un moteur d’optimisation combinatoire s’exécutant sur des GPU et bâti sur des méthodes « heuristiques et métaheuristiques afin de résoudre des problèmes de routage logistiques en prenant en compte de multiples contraintes ». Il est typiquement réservé au monde de la logistique et des services de transport afin d’optimiser des trajets, rerouter des colis, ou encore établir des plans de livraison. L’on peut citer également Riva, un modèle de speech to text, et Earth-2, un outil de simulation climatique.
NIM : des images de conteneurs pour inférer des grands modèles de langage
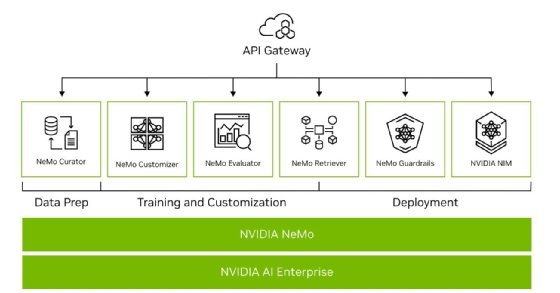
Les différentes briques du framework Nvidia NeMo
Mais c’est Nvidia NIM (NeMo Inference Microservices) que le spécialiste des GPU a largement mis en avant lors de la GTC.
Pour rappel, Nvidia NeMo est un framework introduit l’année dernière qui doit permettre aux développeurs de personnaliser et de déployer l’inférence de grands modèles de langage (LLM).
Techniquement, NIM est moins un microservice qu’une image de conteneur prépackagée incluant des API standards, le moteur d’inférence « optimisé », et le Helm Chart pour déployer le tout.
Les NIM permettent une inférence de deux douzaines de modèles d’IA de Nvidia, AI21 Labs, Getty Images et Shutterstock, ainsi que des modèles ouverts de Google (gemma-7B), Hugging Face, Meta (Llama 2 7B, Llama 2 70B, Code-Llama 70B), Microsoft (kosmos -2), Mistral AI (Mistral 7B, Mixtral 8x7B Instruct) et Stability AI (Stablediffusion XL-Turbo), selon Nvidia.
À l’utilisateur de télécharger le modèle depuis le catalogue NGC ou l’API Catalog avant de lancer le conteneur docker correspondant. À noter que les modèles de fondation sont voués à disparaître du catalogue NGC.
Pour l’inférence, Nvidia a imposé sur le marché son serveur d’inférence Triton et sa version open source TensorRT, plus particulièrement sa variante TensorRT-LLM. L’éditeur ne dit pas s’il laisse ses partenaires fournisseurs de modèles choisir le mode d’implémentation, ou s’il s’appuie sur Triton comme back-end de TensorRT-LLM, une possibilité d’intégration décrite dans la documentation du projet ouvert. Une fois l’image NIM déployé, l’API expose un lien vers un localhost qui abrite une UI afin d’interagir avec le modèle.
« Les conteneurs préconstruits et les Helm charts emballés avec des modèles optimisés, sont rigoureusement validés et comparés sur différentes plateformes matérielles NVIDIA, fournisseurs de services cloud et distributions Kubernetes », avancent les porte-parole de Nvidia dans un billet de blog technique. Concernant les LLMs, l’information est invérifiable, car les descriptions des modèles disponibles dans l’API Catalog semblent avoir été rédigées par les fournisseurs de modèles eux-mêmes. Il n’y a pas d’uniformisation des cartes de modèles et la liste de GPU testés n’est pas encore référencée.
Lors de la conférence d’ouverture de la GTC, Jensen Huang, CEO de Nvidia a décrit la vision d’une architecture qui rassemble plusieurs NIM, afin de constituer des applications ou des systèmes plus complexes. L’éditeur en aurait déjà déployé en interne et l’architecture sera commercialisée sous le nom de NIM Microservices.
« Dans ce que nous faisons, il y a trois piliers », avance Jensen Huang. « Le premier est le fait d’inventer les technologies pour exécuter les modèles d’IA et les compiler pour vous. Le deuxième est de créer des outils pour vous aider à les modifier et le troisième est l’infrastructure pour les fine tuner et les déployer sur notre architecture DGX Cloud, sur site ou dans le cloud », décrit-il. « Nous sommes une fonderie dédiée à l’IA. Nous ferons pour vous ce que fait pour nous TSMC en fabriquant nos puces ».
« Nous sommes une fonderie dédiée à l’IA. Nous ferons pour vous ce que fait pour nous TSMC en fabriquant nos puces ».
Jensen HuangCEO, Nvidia
« [NIM] est la pièce manquante du puzzle de la GenAI », avance Charlie Dai, analyste chez Forrester Research.
« Ce type d’offre, les microservices, alimentera à la fois les développeurs et l’équipe d’exploitation, ainsi que les ingénieurs de données du monde entier », poursuit-il.
Avant la GTC, Nvidia avait déjà commencé à proposer des modèles accessibles sous forme prépackagée. Il n’avait tout simplement pas encore trouvé l’appellation NIM.
D’autant que NIM n’est que la coquille (l’image prépackagée) réservée à l’inférence des LLM. L’éditeur avait déjà présenté en août dernier NeMo Data Curator, devenu simplement Curator et qui est réservé à la préparation de données (OpenMPI, Dask, Redis, etc.). Toujours pour l’entraînement de grands modèles de langage, Nvidia développe également NeMo Customizer, une suite d’outils réservée au fine tuning léger (LoRA et PEFT), puis à l’avenir à l’apprentissage supervisé et au RLHF. Evaluator est un outil d’évaluation semi-automatisé sur différents parangonnages « standards ».
NeMo, une collection d’outils open source… toujours en accès anticipé
Pour mettre en place des architectures RAG (Retrieval Augmented Generation), l’éditeur développe NeMo Retriever, présenté en novembre 2023, une librairie qui s’appuie sur les outils LangChain, LlamaIndex, la base de données vectorielle Milvus ou encore ses propres modèles d’embedding fine-tunés. En parlant de LangChain, Nvidia avait aussi présenté Guardrails, un outil pour filtrer les interactions avec un LLM s’appuyant sur ce même outil.
L’analyste de Forrester se montre particulièrement enthousiaste pour un ensemble de briques open source assemblées, puis conteneurisées, accessibles en préversion ou sur liste d’attente, après avoir signé un accord de non-divulgation. D’autant qu’il n’est pas certain que les paquets constitués par Nvidia conviennent à toutes les entreprises. Et d’autant qu’il faut pouvoir s’offrir Nvidia AI Enterprise et/ou les GPU qui vont avec.
À chaque étage, des projets open source et des offres commerciales existent. Le fait que l’éditeur ait annoncé un ensemble de partenariats avec des éditeurs de bases de données, de spécialistes du datawarehouse et autres, prouve qu’il a bien conscience des limites de son offre et qu’il ne pourra pas vendre des GPU si les charges de travail associées ne sont pas supportées par des acteurs historiquement peu habitués à exploiter des GPU.
Il y a toutefois l’argument de la simplicité relative, note Chirag Dekate, analyste chez Gartner.
« Si vous essayez d’exploiter les NIM, vous avez tout intérêt à utiliser les équipements Nvidia à l’entraînement et à l’inférence », souligne-t-il. « C’est un coup de génie, quel que soit l’endroit où vous l’exécutez, que ce soit sur site, dans le cloud ou en Edge ».
Les fournisseurs de cloud tels que Google, Microsoft et AWS proposent déjà un service similaire pour l’entraînement et l’inférence de l’IA, mais les célèbres GPU H100 de Nvidia sont désormais synonymes de l’écosystème d’entraînement.
« Si vous développez des applications cloud-natives ou des applications sur site ou des applications Edge, vous allez trouver Nvidia partout – pas seulement du point de vue du matériel, mais aussi du point de vue des microservices et des logiciels ».
Chirag DekateAnalyste, Gartner
« Si vous développez des applications cloud-natives ou des applications sur site ou des applications Edge, vous allez trouver Nvidia partout – pas seulement du point de vue du matériel, mais aussi du point de vue des microservices et des logiciels », poursuit Chirag Dekate. « On ne peut pas en dire autant de tous les concurrents de Nvidia. C’est l’avantage sur lequel Nvidia essaie de s’appuyer ».
Les autres logiciels présentés lors de la GTC
De manière plus anecdotique, l’éditeur a aussi présenté Nvidia Edify, une architecture multimodale pour appeler des modèles de diffusion (de génération d’images).
Shutterstock va déployer un accès anticipé à une API construite sur Edify qui permet aux utilisateurs d’utiliser des prompts ou des images pour générer des objets 3D pour des scènes virtuelles.
Enfin, Nvidia a révélé que sa plateforme de métavers, Nvidia Omniverse Cloud, sera disponible sous forme d’API. Les API sont USD Render, USD Write, USD Query, USD Notify et Omniverse Channel. Les API d’Omniverse Cloud seront disponibles sur Microsoft Azure dans le courant de l’année.
Image de la une : capture d’écran de la conférence d’ouverture GTC 2024. DR : Nvidia
Pour approfondir sur Intelligence Artificielle et Data Science