
echiechi - Fotolia
SQL sur Hadoop : Impala a gagné sa communauté
Le projet, contribué par Cloudera à la Fondation Apache en 2015, sort de l’incubateur pour devenir un projet de premier niveau.

A la fin novembre, Impala, moteur de requête SQLsur Hadoop, né chez Cloudera, est passé au rang de projet de premier niveau au sein de la Fondation Apache. Organisation Open Source qu’il avait rejoint, en 2015, au sein de son précieux incubateur. En devenant un projet de premier niveau, Impala a gagné une communauté de développeurs et d’utilisateurs, symbole d’un premier degré de maturité. Outre Cloudera, qui a bâti ce projet en 2011, Caterpillar, Cox Automotive, Jobrapido, Marketing Associates, the New York Stock Exchange, phData et Quest Diagnostics sont listés parmi les utilisateurs en production d’Impala. Du côté de l’écosystème IT, MapR et Oracle revendent la solution.
Depuis son arrivée au sein de l’incubateur, la communauté a contribué à faire progresser le projet en termes de performances et de stabilité, confirme d’ailleurs Jim Apple, vice-président du projet, dans un billet de blog de la Fondation Apache. Une communauté pourtant confrontée à une kyrielle d’outils ayant le même objectif : greffer à HDFS et au monde Hadoop les caractéristiques bien connues des développeurs.
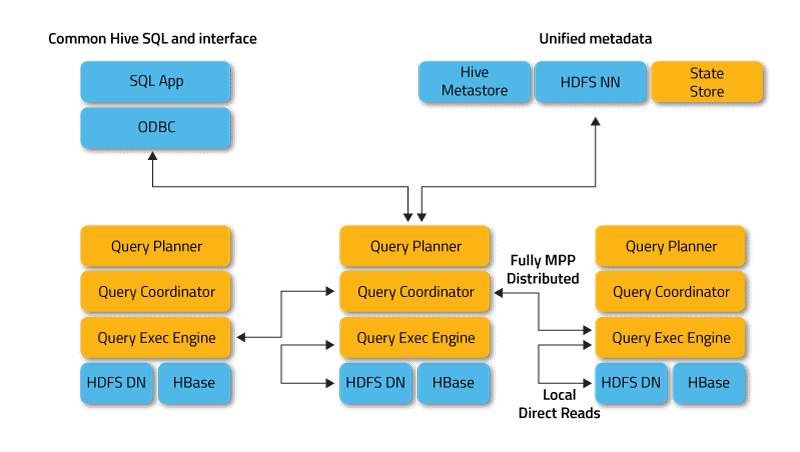
Parmi les plus connus, citons Hive, Spark SQL, Drill et Presto. Tous permettent d’interroger des données stockées dans Hadoop via un moteur SQL distribué. De son côté, Impala s’adosse à une architecture MPP (Massive Parallel Processing) qui dissocie le traitement des requêtes de la partie stockage. Cela vise à améliorer les performances en matière de latence, tout en accélérant le traitement de requêtes concurrentes en volume.
Avec cette approche, Cloudera souhaitait notamment s’attaquer à la problématique du dimensionnement des traitements analytiques sur un cluster. Interrogé par nos confrères de SearchDataManagement, Brock Nolan, architecte en chef et co-fondateur de phData, explique que « les requêtes s’exécutent plus rapidement et les data scientists n’ont pas à ramener leur travaux analytiques chez eux », note-t-il. D’autant que selon lui, Impala bénéficie d’une forte proximité avec les autres composants de l’écosystème Hadoop. C’est notamment le cas avec Kudu, un autre projet né chez Cloudera. Kudu est un data store orienté colonne qui, utilisé avec Impala explique Brock Nolan, accélère le traitement de données issues par exemple de l’Internet des objets – mais tout en conservant SQL.
« Nous pensons que l’adoption d’Impala va grossir », ajoute-t-il, tout en rappelant qu’il utilise également Spark et son module Spark SQL pour des cas d’usage différents. « Spark SQL est très bon pour les opérations d’ETL. En même temps, Impala est notre passerelle SQL vers Hadoop pour présenter les résultats des data scientists et des analystes. Nous utilisons les deux outils, mais Impala est bien celui qui étend la base d’utilisateurs des données. »
Pour approfondir sur Big Data et Data lake
-
![]()
Les principales distributions Hadoop sur le marché
Par: Linda Rosencrance
-
![]()
Presto se loge dans une fondation open source
Par: Jack Vaughan
-
![]()
Flink se pare d’un client SQL : un clin d’œil aux data scientists
Par: Cyrille Chausson
-
![]()
Trois méthodes pour bien préparer ses fichiers mainframe à Hadoop
Par: David Loshin


