Machine Learning vs Deep Learning ? La même différence qu'entre un ULM et un Airbus A380
Le Deep Learning partage certaines caractéristiques avec l'apprentissage statistique traditionnel. Mais les utilisateurs expérimentés le considèrent comme une catégorie à part entière avec une conception de modèles prédictifs et des résultats bien différents.
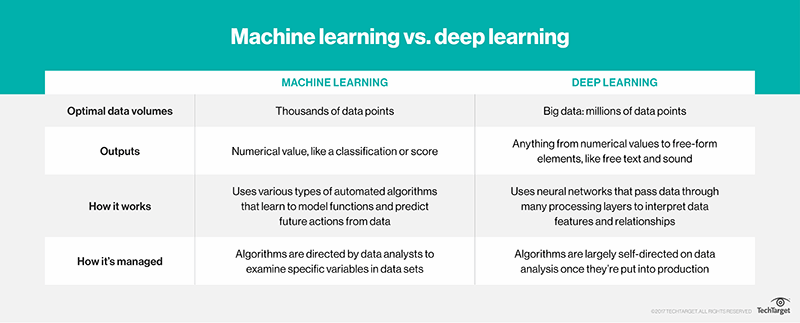
Ce qui différencie le Deep Learning du Machine Learning traditionnel dans les applications d'analyse prédictive ? Et quand choisir lequel plutôt que l'autre ? Pour faire court, la réponse a beaucoup à voir avec la masse de données que vous aurez à disposition.
« Lorsque vous commencez à travailler sur des quantités de données vraiment grandes, c'est là que vous commencer à faire du vrai Deep Learning », résume Alfred Essa, vice-président de la recherche et des données chez McGraw-Hill Education, une maison d'édition new-yorkaise qui est l'un des leaders mondiaux de l'édition universitaire et scientifique.
Sous l'impulsion des progrès des technologies, les processus « d'apprentissage profond » sont devenus un sujet plus largement discuté. Depuis l'année dernière, la différence conceptuelle et pratique entre le Deep Learning et le Machine Learning (apprentissage statistique) a fait l'objet de beaucoup débats. Après tout, ils font appel à un large éventail d'outils et de techniques de modélisation prédictive communs.
Le Deep Learning s'améliore avec la quantité
Mais en dépit de ces similitudes, « chaque discipline est unique », expliquait Alfred Essa lors d'une présentation au Business Analytics Innovation Summit de Chicago en mai dernier.
Par exemple, soulignait-il, les algorithmes conventionnels d'apprentissage plafonnent souvent après le traitement d'une certaine quantité d'informations. La raison, dit-il, est que lorsqu'un algorithme de Machine Learning est destiné à rechercher des corrélations entre des variables spécifiques, ces corrélations deviennent assez rapidement apparentes. Il n'y a dès lors pas grand-chose à apprendre de plus.
Il y a autant de différences entre les deux qu'entre un avion à hélices et un avion à réaction
Alfred Essa, McGraw-Hill Education
La performance des algorithmes de Deep Learning, en revanche, tend à s'améliorer de façon exponentielle lorsqu'on leur donne plus de données pour "s'entraîner" puis à analyser. Cette caractéristique tient en partie au fait que ces algorithmes sont moins dirigés que ceux du Machine Learning. Ils adoptent une approche de réseau neuronal pour rechercher des modèles et des corrélations - qui peuvent être plus subtiles que ce que l'apprentissage statistique révèle - modèles qui se révèlent plus clairement avec l'injection de plus de données.
Il existe également des différences dans le résultat final.
Alfred Essa souligne que les algorithmes de type Machine Learning produisent toujours un résultat numérique, comme une classification ou un score. Les résultats du Deep Learning, eux, peuvent être n'importe quoi, y compris du texte en langage naturel pour sous-titrer une image ou un son ajouté à un film muet.
« De loin, les deux se ressemblent souvent beaucoup », prévient Alfred Essa, « mais en réalité, il y a autant de différences qu'entre un avion à hélices et un avion à réaction ».
ML's not Dead !
Cela ne signifie pas pour autant que le Machine Learning est mort. Bien au contraire.
La plupart des entreprises n'ont pas assez de données pour faire du Deep Learning
Alfred Essa parie que les Data Scientists continueront à développer des algorithmes d'apprentissage statistiques pendant encore de longues années. La plupart des entreprises n'ont en effet pas d'ensembles de données assez grands pour tirer parti du Deep Learning. C'est typiquement le cas de McGraw-Hill. L'équipe de Alfred Essa teste certes le Deep Learning, mais « pour voir », et elle ne l'a pas encore mis en production.
« L'apprentissage statistique traditionnel ne disparaît pas. Il résout encore beaucoup de problèmes », analyse Alfred Essa. « La plupart du Machine Learning que nous faisons n'est pas du Deep Learning. Nous travaillons avec des ensembles de données relativement petits. Diverses techniques de Machine Learning peuvent être essayées et appliquées de manière pertinente. C'est d'ailleurs ce que font les bons Data Scientists ».
L'équipe Data de LinkedIn tire la même leçon
Dans une autre présentation à la même conférence, Wenrong Zeng, experte en analytique et en statistiques chez LinkedIn, a révélé qu'elle aussi avait essayé d'utiliser des techniques de Deep Learning dans le cadre d'un projet dont le but était d'évaluer les prospects les plus pertinents pour le service commercial du réseau social professionnel (qui appartient désormais à Microsoft).
Concrètement, LinkedIn voulait savoir quelles entreprises clientes avaient le plus grand potentiel pour acheter ses nouveaux services liés aux processus d'aide au recrutement de talents.
Mais les Data Scientists n'ont pas obtenu les performances prédictives qu'ils espéraient du Deep Learning. La raison, selon Wenrong Zeng, était tout simplement que même LinkedIn n'avait pas assez de données.
Pour faire du Deep Learning, quelques centaines de milliers d'échantillons, ce n'est pas assez
Wenrong Zeng, LinkedIn (Microsoft)
« Pour faire du Deep Learning, il faut disposer d'une grande quantité d'informations », analyse-t-elle. « Or nous n'avons que quelques centaines de milliers d'échantillons. Ce n'est pas assez. »
Résultat, son équipe de Data Scientists s'est rabattue sur des méthodes plus conventionnelles. Elle a combiné plusieurs modèles (« ensemble modeling ») en mélangeant des forêts d'arbres décisionnels avec des techniques de « Gradient Boosting » (des modèles itératifs dont un des buts est d'éviter le sur-apprentissage). Ce « mix » de pur Machine Learning a, selon Wenrong Zeng, beaucoup mieux fonctionné dans ce cas précis que les modèles de Deep Learning.
Des applications plus pointues pour le Deep Learning
Même si les techniques traditionnelles de Machine Learning ne disparaissent pas, les entreprises pourraient néanmoins bientôt découvrir qu'elles tirent une plus grande valeur ajoutée du Deep Learning.
Le Machine Learning est de plus en plus automatisé dans et par les logiciels. Les compétences requises pour le mettre en place - ou en bénéficier - ne sont plus aussi importantes qu'auparavant. Passer au Deep Learning semble donc, pour de plus en plus d'entreprise, l'étape naturelle suivante.
Toujours lors du Business Analytics Innovation Summit de Chicago, Jan Neumann, directeur du Labs de Comcast, expliquait comment sa société de télévision et de cinéma utilise le Deep Learning pour développer de nouveaux produits. Par exemple, Comcast propose maintenant une télécommande vocale qui exploite ces modèles pour traduire et interpréter les ordres, exprimés en langage naturel, et donner des résultats pertinents aux requêtes des utilisateurs.
Comcast utilise également la reconnaissance visuelle, l'analyse audio et l'analyse de texte (des sous-titres pour malentendants) pour découper les films et les émissions en « chapitres » et générer automatiquement des résumés pour chacun de ces chapitres.
« Cela permet aux téléspectateurs de retrouver facilement les bouts d'émissions qui les intéressent le plus », explique Jan Neumann. « Des algorithmes similaires sont appliqués aux foots américains de la NFL et au soccer pour repérer et souligner automatiquement les moments clefs des matchs ».
Pour lui, ces techniques de Deep Learning permettent à Comcast d'aller au-delà du modèle traditionnel qui consistait à proposer passivement des chaînes de télévision aux téléspectateurs. « Nous avons aujourd'hui beaucoup plus de données à notre disposition. Nous disposons d'une puissance de calcul beaucoup plus importante que par la passé. Et nous disposons à présent d'algorithmes plus complexes pour créer de nouvelles expériences [pour nos clients] ».
Amazon utilise le même mélange d'informatique cognitive et de Deep Learning pour son service de streaming Prime Video. Grâce à ces technologies, l'identification des personnages présents à l'écran dans un film ou une émission est automatisée. Le spectateur peut par exemple demander la fiche de chaque acteur ou de chaque présentateur sans qu'Amazon ait besoin auparavant de taguer la séquence avec des méta-données.
Disruption vs Optimisation
Alfred Essa pense que les entreprises qui trouveront les moyens de tirer parti de "l'apprentissage profond" (terminologie préférée par les canadiens) le feront pour élaborer de nouveaux produits et de nouveaux business modèles. Le Machine Learning traditionnel, lui, se verrait essentiellement relégué aux taches d'optimisation des opérations existantes.
D'après lui, c'est d'ailleurs un autre facteur clef de différenciation entre les deux disciplines analytiques.
En conclusion, le Deep Learning peut répondre (du moins en théorie) à des questions beaucoup plus importantes et complexes que celles que l'on pensait, il y a peu, pouvoir confier à des machines. « Son potentielle business est considérable », se réjouit Alfred Essa qui constate que « les entreprises avant-gardistes investissent dans ces algorithmes ». Elles le font, d'après lui, pour une raison simple : « ces entreprises pionnières parient que le Deep Learning sera à terme différenciant et très disruptif ».
Pour approfondir sur Outils décisionnels et analytiques