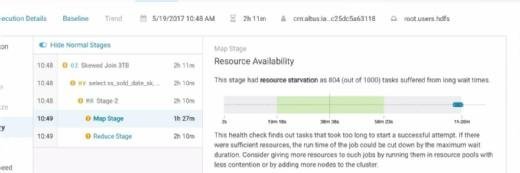
Altus : un Paas Cloudera pour faciliter l’utilisation d’Hadoop dans le Cloud
La spécialiste du monde Hadoop a présenté un premier service destiné aux ingénieurs de la donnée. Altus sert avant tout à faciltier la création de clusters sur AWS et la soumission de jobs Spark et MapReduce dans le Cloud public.

Dans le monde du Big Data, il est une constante : la mise en place et la configuration d’environnements Hadoop et/ou Spark, Cloud ou sur site, est une opération douloureuse et chronophage qui n’est pas toujours à la portée des utilisateurs des données. Pour tous ceux-là, Cloudera a présenté Altus. Dévoilé lors de l’édition londonienne de la conférence Strata Data, Altus apparait comme un Paas dont la vocation première est d’accélérer la mise en place, et l’arrêt, d’environnements Hadoop installés dans un Cloud public. Gommant ainsi toute forme de complexité liée à la configuration de l’infrastructure sous-jacente – là est l’idée de Paas.
Techniquement, Altus est – du moins lors de son lancement – un raccourci « fast-track » de provisioning de clusters sur AWS pour motoriser CDH, la distribution Hadoop de Cloudera, ainsi que les moteurs de Spark, Hive et MapReduce2, Hive on Spark et Hive ur MR2. Le tout adapté, dans le cadre d’un premier service défini au dessus d’Altus, à des tâches propres aux ingénieurs de la donnée ( data engineers, ceux qui préparent, agrègent, intègrent et nettoient les données avant leur usage analytique par les data scientists, par exemple). Ce service Data Engineer d’Altus s’appuie donc sur AWS, exploite S3 en lecture et écriture, et reprend les principaux moteurs d’execution et outils adaptés à ce type de workloads.
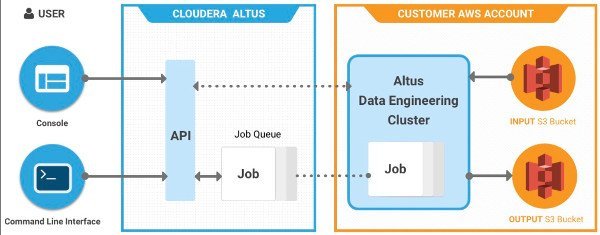
Interface utilisateur ou ligne de commande
Avec Altus, l’idée est ainsi de fournir des opérations fondamentales, indispensables à cette typologies d’utilisateurs, sans avoir à re-configurer systématiquement leur environnement. Si déployer des systèmes Hadoop, Spark et MapReduce était déjà possible sur AWS, leur configuration nécessitait une attention particulière dans le tuning. Altus veut faciliter cette configuration d’environnements dédiés et reproductibles et d’en permettre l’usage de façon flexible. Il s’agit ainsi de permettre à cette cible de créer et de provisioner un ou des clusters, de les stopper et de pourvoir y exposer leurs opérations et jobs, à la demande.
L’utilisateur s’appuie pour cela sur un portail, doué d’une interface utilisateur avec laquelle les opérations de configuration du cluster sont réalisées. L’ensemble des mécanismes effectués sur l’infrastructure d’AWS est ainsi camouflé derrière cet UI. Les API d’Altus, qui télécommandent donc AWS, pourront également être manipulées par des lignes de commandes afin de faciliter la mise en place automatique de clusters.
Via de portail, l’utilisateur crée les clusters et les gère, effectue ses opérations et peut également analyser et identifier les jobs défaillants. Ceux-ci sont aussi journalisés pour mieux les soumettre au cluster dans le cas où un job n’aurait pas été finalisé.
Si aujourd’hui, Altus s’appuie sur AWS, Cloudera compte étendre sa plateforme vers d’autres fournisseurs et liste Azure comme la prochaine étape. D’autres scenarii, au-delà du service dédié à l’ingénieur de la donnée, sont également à l’étude.
Pour approfondir sur Big Data et Data lake
-
![]()
Les principales distributions Hadoop sur le marché
Par: Linda Rosencrance
-
![]()
AWS Glue Data Pipeline ou BATCH : quel ETL cloud native choisir ?
Par: Ernesto Marquez
-
![]()
Cloudera et Hortonworks font désormais front commun dans une fusion de 5,2 Md de dollars
Par: Cyrille Chausson
-
![]()
Big Data Paris : Indexima, qui arrive sur AWS, accélère aussi les requêtes sur S3
Par: Cyrille Chausson


