
jules - Fotolia
AWS Glue Data Pipeline ou BATCH : quel ETL cloud native choisir ?
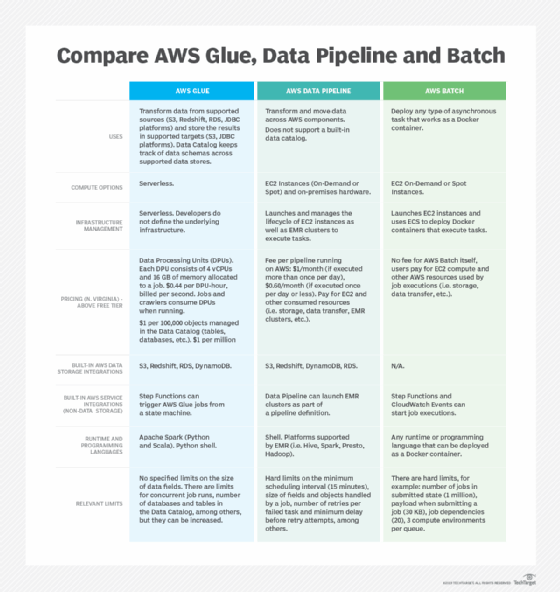
Il existe trois solutions ETL phares pour les applications cloud natives hébergées sur AWS. Voici les critères pour faire son choix entre le service managé AWS Glue, les sources de données supportées par Data Pipeline et les opérations asynchrones permises par Batch.

À un moment T, la plupart des applications cloud natives doivent déplacer, transformer ou analyser des données à travers différents composants ou exécuter plusieurs opérations asynchrones de longue durée. Pour cela, les développeurs peuvent compter sur des services mis à leur disposition par les fournisseurs cloud.
Ils proposent ainsi des solutions ETL adaptées à leurs offres. Chez AWS, Glue, Amazon Data Pipeline et BATCH sont conçus pour déployer et gérer ces charges de travail. Reste à choisir correctement l’un de ces trois outils suivant des besoins particuliers. Pour cela, il faut prendre en compte la facilité d’utilisation, la flexibilité et le coût d’un scénario particulier. Un tableau comparatif complète les éléments exposés dans cet article.
AWS Glue : un service entièrement managé
AWS Glue est un service ETL entièrement géré. Les développeurs définissent et orchestrent les tâches de transformation des données selon une approche serverless. Celles-ci, connues sous le nom de « jobs », peuvent s’exécuter depuis Apache Spark Shell ou Python Shell. Glue met à disposition des scripts prédéfinis pour les fonctions les plus courantes. Les développeurs peuvent aussi utiliser leurs propres scénarios s’ils ont besoin davantage de flexibilité. Par ailleurs, cet ETL profite d’une suite d’algorithmes d’apprentissage statistique. Elle trouve ainsi des correspondances et labélise les données.
AWS Glue conserve un Data Catalog pour les sources associées. Il est possible de le maintenir à jour manuellement ou de configurer des robots d’indexation afin de détecter automatiquement la structure des données stockées dans Amazon S3, DynamoDB, RedShift, Relational Database Service (RDS) ou dans toute base qui supporte l’API Java Database Connectivity (JDBC). Concrètement, Glue lit les données d’une source définie dans le Data Catalog, applique les transformations nécessaires, puis enregistre le résultat dans S3 ou une base de données compatible avec JDBC.
Les capacités de gestion de l’ETL s’étendent à l’orchestration basique de flux d'événements. Dans ce cadre, les utilisateurs définissent des déclencheurs et des opérations. Pour des flux de transformation de données plus complexes, ils peuvent compter sur AWS Step Functions, un outil FaaS intégré dans Glue. Ce dernier les coordonne à travers plusieurs couches technologiques du fournisseur.
AWS Data Pipeline dépend des instances EC2
Les clients d’AWS devraient comparer Glue et Data Pipeline à l’aune de leurs besoins en ETL. Cette deuxième solution s’intègre nativement avec S3, DynamoDB, RDS et Redshift. Ils peuvent configurer l’outil pour accéder à des données stockées dans Amazon Elastic File System ou sur site.
Data Pipeline offre également des templates pour les tâches les plus communes comme copier des fichiers depuis RDS vers S3 ou de DynamoDB vers Redshift. Il supporte lui aussi l’exécution de commandes shell afin de faciliter les opérations personnalisées.
Data Pipeline gère des flux de travail plus complexes que Glue. Cependant, la combinaison de Glue et de Step Fuctions offre un haut degré de flexibilité pour les orchestrer et configurer des déclencheurs.
La différence clé tient dans la manière d’exécuter les « jobs ». Les tâches liées à Data Pipeline se font obligatoirement depuis des instances EC2, ce qui n’est pas le cas avec Glue. Data Pipeline gère leur cycle de vie, les lance, puis les ferme quand une opération est terminée. Les « jobs » peuvent être planifiés manuellement ou automatiquement grâce à AWS API. Le service permet également d’activer des clusters sur Elastic MapReduce. Cette intégration native de la plateforme donne accès à Spark, Hadoop, Hbase, Hive et Presto, entre autres. De plus, les utilisateurs configurent à leur guise des équipements sur site afin d’exécuter des tâches basées sur Java.
AWS Batch : ETL et au-delà
AWS Batch propose les mêmes fonctionnalités que Glue et Data Pipeline. À la différence près qu’il n’est pas seulement un ETL. Le service est optimisé pour la prise en charge de nombreuses opérations asynchrones lancées en parallèle, qui réclament une puissance de calcul importante.
Outre leur planification, Batch facilite la gestion des tâches interdépendantes. L’orchestration des flux passe encore une fois par Step Functions. Cependant, les « jobs » sont définis comme des containers Docker déployés à l’aide d’Elastic Container Service. Cette architecture offre une plus grande flexibilité aux développeurs. Ils définissent tout le code de l’application et prépare les commandes nécessaires à l’intérieur de ces conteneurs, une approche bien distincte des deux autres services.
Pour approfondir sur Middleware et intégration de données
-
![]()
Data Platform en mode produit : mode d’emploi et bénéfices en industrialisation
Par: Christophe Auffray
-
![]()
Databricks aiguise ses outils de migration, d’ingestion et de transformation de données
Par: Gaétan Raoul
-
![]()
Qlik lance un Lakehouse ouvert dédié à l’intégration de données
Par: Gaétan Raoul
-
![]()
BigQuery : les efforts de GCP pour ne pas se faire distancer
Par: Gaétan Raoul



