
sdecoret - stock.adobe.com
Avec Cortex, Snowflake part à la conquête de l’IA générative
Dans sa volonté de proposer une PaaS consacrée aux traitements de données, lors de son événement Snowday, Snowflake a détaillé sa feuille de route en matière d’IA générative. Les analystes déplorent le trop grand nombre d’annonces par rapport aux fonctionnalités réellement disponibles.
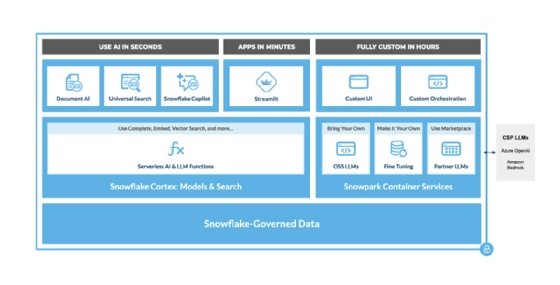
Évoquée lors de sa conférence annuelle Snowflake Summit, le spécialiste du datawarehousing précise sa stratégie en matière d'IA générative. Celle-ci repose principalement sur Snowflake Cortex qui elle-même s’appuie sur Snowpark Container Services.
Container Services est la solution CaaS interne à Snowflake. « Vous pouvez même exécuter PostgreSQL sur Snowflake si vous le voulez », s’amusait Franck Slootman, Président de Snowflake, lors d’un événement parisien au début du mois d’octobre.
Dans le contexte de Cortex, Container Services doit permettre de déployer des modèles d’IA, de petits modèles d’IA générative maison, ceux de partenaires à travers la marketplace et d’en fine-tuner d’autres.
Cortex et Snowpark Container Services : deux piliers pour Snowflake
Pour l’heure, Snowflake héberge lui-même l’ensemble de la collection Llama 2-Chat (7, 13 et 70 milliards de paramètres) pour des usages généraux, mais l’éditeur a légèrement réduit la fenêtre de contexte à 3 000 tokens, contre 4 000 normalement. Une version fine tuné de Llama 2-Chat 7B doté de 400 millions de paramètres et d’une fenêtre de contexte de 780 tokens vise à produire des résumés.
Pour des flux de traduction, Snowflake fournit MBart-50, un autre modèle développé par Meta sous licence MIT, dont la fenêtre de contexte est pareillement fixée à 780 tokens pour 610 millions de paramètres.
Les entreprises pourront également accéder aux modèles disponibles depuis Azure OpenAI et Amazon Bedrock.
Cortex porte, par ailleurs, la capacité de prise en charge des vecteurs dans Snowflake.
Plus spécifiquement, Snowflake a acquis il y a cinq mois Neeva, une startup qui vendait un moteur de recherche privé dont les performances étaient légèrement en deçà de ce que propose Google, dixit Benoît Dageville, cofondateur et chef du produit chez Snowflake.
« Cortex apporte des fonctions LLM avancées ainsi que de la recherche hybride, une combinaison d’indexation vectorielle et d’indexation traditionnelle dans Snowflake », avance Sridhar Ramaswamy, vice-président senior de l’IA chez Snowflake et cofondateur de Neeva.
Cette notion de recherche hybride est également mise en avant par Elastic, qu’il considère comme un atout par rapport aux bases de données vectorielles « pur jus ».
Pour vectoriser les données non structurées, Snowflake s’appuie sur le modèle open source E5-base-v2. Une fois ces vecteurs stockés dans Snowflake, il est possible de déployer des applications de Retrieval Augmented Generation (RAG).
L’éditeur se penche sur une autre technique complémentaire à l'aide du projet electra-base-squad2, développé par Deepset, une startup allemande. Ce modèle permet de concevoir des systèmes d’extraction de questions-réponses.
« Les documents sont traités par un modèle en mode lecture qui identifie et met en évidence les réponses pertinentes », explique Deepset sur son site Web. « Contrairement aux systèmes génératifs, les systèmes extractifs ne génèrent pas de nouveau texte. Ils se concentrent plutôt sur l’extraction d’informations à partir des documents que vous fournissez ».
Ces fonctionnalités ne seraient pas intéressantes si elles n’étaient pas intégrées au reste de la plateforme, estiment les porte-parole de Snowflake. Ainsi, Snowflake développe dans Cortex des « fonctions générales et spéciales ».
Les fonctions spéciales sont des commandes SQL/Python permettant d’appeler des modèles de machine learning et d’IA générative depuis l’interface utilisateur de Snowflake. Une série de fonctions « serverless » ou FaaS (Translate, Summarize, Extract Answer, Sentiment Detect) sont propulsées par des LLMs et des modèles NLP pour traiter des données non structurées. D’autres (Forecast, Anomaly Detection, Top insights, Classification) sont des fonctions de machine learning dédiées aux données structurées.
Les fonctions générales, elles aussi, sont des commandes SQL/Python consacrées à l’inférence des LLM et l’exécution de la recherche vectorielle.
Dans les deux cas, celles-ci pourront être enclenchées depuis Streamlit, un framework pour développer et déployer des applications écrites en Python.
Snowflake s’appuie lui-même sur ces briques pour proposer trois applications : Document AI, Universal Search et Snowflake Copilot.
Universal Search exploite les technologies de Neeva et sera déployée à l’échelle de la plateforme pour « simplifier la recherche de documents et de données dans l’ensemble du data cloud ».
DocumentAI mêle des capacités d’OCR et d’IA générative pour extraire des informations depuis des documents textuels, dont les PDF, afin de les stocker dans Snowflake.
Snowflake Copilot n’est autre qu’un assistant au développement de requêtes SQL en langage naturel. L’outil doit « tirer parti de la recherche universelle, de la capacité de Snowflake à comprendre les données au format colonnaires et des modèles de langage pour offrir une interface à partir de laquelle les analystes peuvent générer des requêtes SQL », relate Sridhar Ramaswamy. Il ne s’agit pas de remplacer les analystes, mais de les « rendre plus productif ».
Cortex, un plan sur la comète ? Une vision plutôt, considèrent les analystes
« Comme tous les éditeurs de logiciels, Snowflake essaie de jouer un rôle plus actif dans le monde de l’intelligence artificielle et du machine learning », avance David Menninger, analyste chez Ventana Research. « Cortex fournit une base permettant aux clients de Snowflake d’utiliser plus facilement les LLM et l’IA générative ».
Pour d’autres, Snowflake présente là une vision.
« Snowflake a tendance à faire des annonces du type “attention, ça arrive” pendant Snowday et d’affirmer “c’est maintenant en préversion publique ou en disponibilité générale” lors de Snowflake Summit en juin », rappelle Doug Henschen, vice-président et analyste chez Constellation Reasearch. « Je n’ai pas tendance à m’enthousiasmer pour des fonctionnalités en préversion privée qui ne seront pas disponibles pour les clients avant six à douze mois ».
« Cortex est entièrement en préversion privée, mais nous voyons comment l’IA générative et l’IA/ML plus conventionnelle seront mises à disposition sur la plateforme Snowflake », constate-t-il.
Des fonctions de MLOps plus tangibles
Avant cela, les utilisateurs de Snowflake auront accès en disponibilité générale à Snowpark ML Modeling, un framework de préparation de données et d’entraînement de modèles de machine learning « sans sortir les données de Snowflake ». La suite d’API est compatible avec des bibliothèques scikit-learn, xgboost et lightbgm.
« Nous donnons aux développeurs et aux data scientists des fonctions Python simples par l’intermédiaire d’une librairie Snowpark qui reprend des capacités courantes », résume Jeff Hollan, directeur de la gestion produit chez Snowflake. « La seule différence réside dans l’exécution de ces bibliothèques. Nous nous occupons d’exécuter ces tâches de prétraitement et d’entraînement à large échelle ».
Snowpark Model Registry est une autre solution bientôt disponible en préversion publique. Celle-ci permet d’enregistrer, puis de déployer des modèles de machine learning développés depuis la plateforme Snowflake ou non, ainsi que leurs métadonnées sur le warehouse (data cloud) ou dans Snowpark Container Services. Les outils tels qu’Azure Machine Learning, Dataiku, mlflow, Huggingface, TensorFlow et Pytorch seront compatibles.
« N’importe qui au sein d’un compte Snowflake disposant des bonnes autorisations peut découvrir ces modèles et les déployer, qu’il s’agisse d’un analyste souhaitant déployer une fonction de prévision ou d’un data scientist qui les exploite dans le cadre d’un projet plus large », affirme Jeff Hollan.
En sus de passer par la librairie Snowflake Conda et PyPI, il sera possible de déployer les modèles depuis des notebooks spécifiques à Snowflake, une autre capacité en préversion privée qui sera accessible depuis l’interface SnowSight. Encore en préversion privée, l’éditeur développe un feature store pour gérer les paramètres et les versions des modèles.
Ce laps de temps entre les annonces et la disponibilité des fonctionnalités seraient un avantage pour les concurrents, selon Doug Henschen.
« C’est une bonne série d’annonces », conclut-il. « Mais avec autant d’éléments en préversion privée, j’ai l’impression que Databricks et Google Cloud sont en avance sur [Snowflake] en ce qui concerne les capacités d’IA, de machine learning et d’IA générative au sein de la plateforme et le soutien aux clients qui souhaitent développer leurs propres modèles ».
« Les aperçus sont très utiles pour développer des fonctionnalités robustes, mais ils peuvent être un peu déroutants pour les clients qui essaient de comprendre quelles fonctionnalités sont à quel stade de développement », renchérit Dave Menninger de Vantana Research.
Ce n’est pas la première fois que l’éditeur procède de la sorte. Snowflake avait presque pris deux ans à déployer les fonctionnalités annoncées lors de Data Cloud Summit en 2020.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
Horizon : Snowflake étoffe sa couche de gouvernance pour l’IA
Par: Gaétan Raoul
-
![]()
CoCo et CoWork : Snowflake dope sa plateforme à l’IA agentique
Par: Gaétan Raoul
-
![]()
Machine learning : à l’ère de l’IA agentique, Snowflake termine (enfin) ses fondations
Par: Gaétan Raoul
-
![]()
« GenAI & Data » : Gemini 3 de Google s’invite dans Cortex AI de Snowflake
Par: Eric Avidon



