Bien comprendre l’architecture RAG et ses fondamentaux
Désormais perçue comme le moyen idéal pour infuser l’IA générative dans le contexte d’une entreprise, l’architecture RAG implique la mise en œuvre de différentes briques technologiques et pratiques spécifiques. Tous demandent d’effectuer des compromis.
Tous les éditeurs et les fournisseurs de LLM semblent se concentrer sur l’avènement des agents IA et de l’IA agentique. Ces termes entraînent une forme de confusion. D’autant que les acteurs ne s’entendent pas encore sur la manière de les développer et les déployer.
C’est beaucoup moins vrai pour les architectures RAG (Retrieval Augmented Generation). Dès 2023, elles ont suscité un consensus dans l’industrie IT.
Qu’est-ce qu’une architecture RAG ?
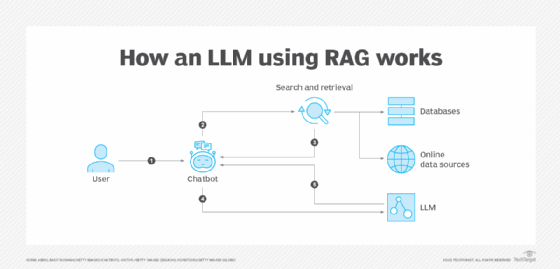
Les premières représentations des architectures RAG ne font pas la lumière sur les rouages, pourtant essentiels, de ces systèmes.
La génération augmentée par récupération permet d’ancrer les résultats d’un modèle d’IA générative dans une vérité terrain. Si elle n’empêche pas les hallucinations, la méthode vise à obtenir des réponses pertinentes, basées sur les données internes de l’entreprise ou sur des informations issues d’une base de connaissances vérifiée.
Elle pourrait être résumée au croisement de l’IA générative et d’un moteur de recherche d’entreprise.
À gros trait, le processus d’un système RAG est simple à comprendre. Celui-ci démarre par l’envoi d’un prompt – une question ou une demande – par l’utilisateur. Ce prompt en langage naturel et la requête associée sont comparés par le processus au contenu de la base de connaissances. Les résultats les plus proches de la demande sont classés par ordre de pertinence, puis le tout est envoyé à un LLM afin qu’il produise la réponse renvoyée à l’utilisateur.
Les entreprises qui ont tenté de la déployer se sont rendu compte des spécificités d’une telle approche. À commencer par la prise en charge des différentes pièces qui animent ce mécanisme RAG. Ces composants sont associés à des étapes nécessaires pour transformer les données, de leur ingestion dans un système source à la génération d’une réponse par un grand modèle de langage (LLM).
Préparer les données, une nécessité même avec un système RAG
La première étape consiste à rassembler les documents que l’on souhaite interroger. S’il est tentant d’ingérer tous les documents à disposition, c’est une mauvaise stratégie. D’autant qu’il faut décider de mettre à jour le système en batch ou en continu.
« L’on oublie souvent cette notion de raffinage qui était pourtant bien comprise dans le cadre du machine learning. L’IA générative, ça ne fait pas des Chocapic ».
Bruno MaillotDirecteur Practice AI for Business, Sopra Steria Next
« Les échecs viennent de la qualité en entrée. Certains clients me disent : “j’ai deux millions de documents, tu as trois semaines, fais-moi un RAG”. Évidemment, ça ne fonctionne pas », lance Bruno Maillot, directeur Practice AI for Business chez Sopra Steria Next. « L’on oublie souvent cette notion de raffinage qui était pourtant bien comprise dans le cadre du machine learning. L’IA générative, ça ne fait pas des Chocapic ».
Un LLM n’est pas « de facto » un outil de préparation de données. Il convient de retirer les doublons, les versions intermédiaires des documents et d’appliquer des stratégies de sélection des articles ou items à jour. Cette présélection évite de surcharger le système d’informations potentiellement inutiles et d’éviter les problèmes de performances.
Une fois les documents sélectionnés, il s’agit de convertir les données brutes (pages HTML, documents PDF, images, fichiers docs, etc.) dans un format exploitable, c’est-à-dire du texte et des métadonnées associées (exprimés dans un fichier JSON, par exemple). Ces métadonnées peuvent à la fois documenter la structure du document, mais aussi ses auteurs, sa provenance, sa date de création, etc. Ces données formatées sont ensuite transformées en tokens, puis en vecteurs.
Les éditeurs ont rapidement compris qu’avec des volumes de documents importants et de longs textes, il est peu efficace de vectoriser l’ensemble du document.
Le chunking et ses stratégies
D’où l’intérêt de mettre en place une stratégie de « chunking ». Cette étape consiste à subdiviser un document en courts extraits. Une étape cruciale, selon Mistral AI. « Cela facilite l’identification et la récupération des informations les plus pertinentes lors du processus de recherche ».
Ici, il faut prendre en compte deux considérations : la taille des fragments et la manière de les obtenir.
La taille d’un chunk est souvent exprimée en nombre de caractères ou de tokens. Un plus grand nombre de chunks améliore la précision des résultats, mais la multiplication de vecteurs augmente la quantité de ressources et le temps nécessaire pour les traiter.
Pour diviser un texte en « chunks », il existe plusieurs méthodes.
La première est de découper en fonction de fragments de taille fixe : des caractères, des mots ou des tokens. « Cette méthode est simple, ce qui en fait un choix populaire pour les phases initiales de traitement des données où il est nécessaire de parcourir rapidement les données », indique Ziliz, un éditeur de base de données vectorielle.
Une deuxième approche consiste en un découpage sémantique, c’est-à-dire en s’appuyant sur un découpage « naturel » : par phrase, par section (défini par un Header HTML par exemple), sujet ou par paragraphe. Plus complexe à implémenter, cette méthode est cependant plus précise. Elle dépend souvent d’une approche « récursive », puisqu’il est question d’utiliser des séparateurs logiques (espace, virgule, point, titraille, etc.).
La troisième approche consiste en une combinaison des deux précédentes. Le chunking hybride permet d’associer un premier découpage fixe avec une méthode sémantique quand il convient d’obtenir une réponse très précise.
En complément de ces techniques, il est possible de « chaîner » les fragments entre eux, en prenant en compte qu’une partie du contenu des chunks peut se chevaucher. « Le chevauchement garantit qu’il y a toujours une certaine marge entre les segments, ce qui augmente les chances de capturer une information importante même si elle est divisée selon la stratégie de découpage initiale », explique Cohere, dans sa documentation. « L’inconvénient de cette méthode est qu’elle génère de la redondance ».
La solution la plus populaire semble de conserver des fragments fixes de 100 à 200 mots avec un chevauchement de 20 à 25 % du contenu entre les chunks.
Ce découpage est souvent réalisé à l’aide de librairies Python, dont SpaCy ou NTLK, ou encore avec les outils « Text splitters » du framework LangChain.
La bonne approche dépend généralement de la précision exigée par les usagers. Par exemple, un découpage sémantique semble plus adéquat quand il s’agit de retrouver une information spécifique, par exemple l’article d’un texte de loi.
La taille des chunks doit correspondre aux capacités du modèle d’embeddings. C’était justement la raison première pour laquelle le chunking est nécessaire. Cela « permet de rester en deçà de la limite de tokens en entrée du modèle d’embeddings », explique Microsoft dans sa documentation. « Par exemple, la longueur maximale du texte en entrée pour le modèle Azure OpenAI text-embedding-ada-002 est de 8 191 tokens. Étant donné qu’un token correspond en moyenne à environ quatre caractères avec les modèles OpenAI courants, cette limite maximale équivaut à environ 6 000 mots ».
La vectorisation et les modèles d’embeddings
Un modèle d’embeddings est chargé de convertir les chunks ou les documents en vecteurs. Ces vecteurs sont stockés dans une base de données.
Là encore, il existe plusieurs sortes de modèles d’embeddings, principalement des modèles denses et des modèles épars (sparse). Les premiers produisent généralement des vecteurs de taille fixe, exprimés en x nombres de dimensions. Les seconds génèrent des vecteurs dont la taille dépend de la longueur du texte en entrée. Une troisième voie mêle les deux approches pour vectoriser de courts extraits ou des commentaires (Splade, ColBERT, IBM sparse-embedding-30M).
Le choix du nombre de dimensions déterminera la précision et la vitesse des résultats. Un vecteur avec beaucoup de dimensions capture davantage de contexte et de nuances, mais peut réclamer plus de ressources pour le créer et le retrouver. Un vecteur doté d’un plus petit nombre de dimensions sera moins riche, mais plus rapide à rechercher.
Le choix du modèle d’embeddings dépend aussi de la base de données dans laquelle les vecteurs seront enregistrés, du grand modèle de langage avec lequel il sera associé et de la tâche à accomplir. Les benchmarks comme le classement MTEB sont d’une aide précieuse. Il est parfois possible d’utiliser un modèle d’embeddings qui ne provient pas de la même collection du LLM, mais il est nécessaire d’utiliser le même modèle d’embeddings pour vectoriser la base documentaire et les questions des usagers.
Notons qu’il est parfois utile de fine-tuner le modèle d’embeddings quand celui-ci ne contient pas suffisamment de connaissances sur le langage lié à un domaine spécifique (au hasard, la médecine oncologique ou l’ingénierie des systèmes).
La base de données vectorielle et son algorithme « retriever »
La base de données vectorielle ne fait pas que stocker les vecteurs : elle intègre généralement un algorithme de recherche sémantique basée sur la technique des plus proches voisins pour indexer et retrouver les informations qui correspondent à la question. La plupart des éditeurs ont implémenté l’algorithme Hierarchical Navigable Small Worlds (HNSW). Microsoft est également influent avec DiskANN, un algorithme open source conçu pour obtenir un ratio performance-coût idéal avec de gros volume de vecteurs, au détriment de la précision. Google a choisi de développer un modèle propriétaire, ScANN, également conçu pour d’importants volumes de données. Le processus de recherche consiste à traverser les dimensions du graphe vectoriel à la recherche du plus proche voisin approximatif et est fonction d’un calcul de distance cosinus ou euclidienne.
La distance cosinus est plus efficace pour identifier la similarité sémantique, tandis que la méthode euclidienne est plus simple, mais moins gourmande en ressources de calcul.
Puisque la plupart des bases de données s’appuient sur la recherche approximative des plus proches voisins, le système renverra plusieurs vecteurs correspondant potentiellement à la réponse. Il est possible de limiter le nombre de résultats (top_k cutoff). C’est même nécessaire, puisque l’on veut que la requête de l’usager et les informations pour constituer la réponse tiennent dans la fenêtre de contexte du LLM. Or si la base contient beaucoup de vecteurs, la précision peut en pâtir ou le résultat que l’on cherche peut se trouver au-delà de la limite imposée.
L’association d’un modèle de recherche classique comme BM25 avec un « retriever » de type HNSW peut être utile pour obtenir un bon ratio coût-performance, mais il sera également limité à un nombre restreint de résultats. D’autant que toutes les bases de données vectorielles ne prennent pas en charge la combinaison de modèles HNSW avec BM25 (aussi appelé recherche hybride).
Un modèle de reranking peut alors aider à trouver davantage de contenus jugés utiles pour la réponse. Cela implique d’augmenter la limite de résultats renvoyée par le modèle « retriever ». Ensuite, comme son nom l’indique, le reranker réordonne les chunks en fonction de leur pertinence avec la question. Parmi les rerankers, l’on peut citer Cohere Rerank, BGE, Janus AI ou encore Elastic Rerank. En contrepartie, un tel système peut augmenter la latence des résultats renvoyés à l’utilisateur. Aussi, il peut être nécessaire de réentraîner ce modèle si le vocabulaire utilisé dans la base de documents est spécifique. Pour autant, certains le jugent utile : les scores de pertinence sont des données utiles pour superviser les performances d’un système RAG.
Reranker ou pas, il est nécessaire d’envoyer les réponses aux LLM. Là encore, tous les LLM ne sont pas égaux : la taille de leur fenêtre de contexte, leur vitesse de réponse, leur capacité à répondre factuellement (même sans avoir accès à des documents) sont autant de critères qu’il faut évaluer. En cela, Google DeepMind, OpenAI, Mistral AI, Meta et Anthropic ont entraîné leur LLM pour prendre en charge ce cas d’usage.
Évaluer et observer
En plus du reranker, un LLM as-a-judge peut être utilisé pour évaluer les résultats et identifier les potentielles sorties de route du LLM censé générer la réponse. Certaines API s’appuient plutôt sur des règles afin de bloquer les contenus nocifs ou les demandes d’accès à des documents confidentiels pour certains des usagers. L’on peut également utiliser des frameworks de collecte d’avis afin d’affiner l’architecture RAG. Ici, il s’agit d’inviter les usagers à noter les résultats pour identifier les points positifs et négatifs du système RAG. Enfin, l’observabilité de chacune des briques est nécessaire afin d’éviter les problèmes de coûts, de sécurité et de performances...