
Getty Images
IA générative : comment atténuer les hallucinations
Les hallucinations des modèles IA générative peuvent engendrer des problèmes majeurs en entreprise. Des stratégies d’atténuation telles que la génération augmentée par récupération, la validation des données, la mise en place de filtres de résultats et la surveillance continue peuvent être utiles.
Les systèmes d’IA générative produisent parfois des informations fausses ou trompeuses, un phénomène connu sous le nom d’hallucination. Ce problème est de nature à freiner l’usage de cette technologie par les entreprises qui espèrent pouvoir traiter certaines de leurs données et tâches.
De plus, cela peut éroder l’intégrité d’une organisation et entraîner des réparations coûteuses et fastidieuses.
Pour réduire le risque de désinformation générée par l’IA et améliorer la fiabilité du système, les praticiens doivent comprendre, identifier et atténuer les problèmes d’hallucinations potentielles.
Qu’est-ce qu’une hallucination ?
Les hallucinations se produisent lorsque le modèle d’IA produit des informations incorrectes, trompeuses ou inventées de toutes pièces. Ce phénomène peut survenir dans divers systèmes d’IA générative, notamment les générateurs de texte, les créateurs d’images, etc.
Les hallucinations sont généralement involontaires. Elles découlent du fait que l’IA générative s’appuie sur des patterns appris à partir de ses données d’apprentissage plutôt que sur l’accès à des bases de données factuelles externes ou à des informations en temps réel. Le traitement de ces hallucinations constitue un défi important pour le développement de l’IA, d’autant que cette capacité à inventer est également souhaitable.
Une hallucination typique d’un modèle d’IA générative implique la création de faits historiques ou scientifiques. Par exemple, un IDE assisté par un modèle d’IA peut générer du code qui ne s’exécute pas.
Avec un assistant de type ChatGPT, les hallucinations peuvent se manifester sous la forme d’un contenu factuellement inexact, de fausses attributions et de citations inexistantes. Dans l’IA génératrice d’images, ce comportement implique la création d’images avec des éléments déformés, irréalistes ou toxiques.
Les stratégies pour atténuer les hallucinations de l’IA
L’atténuation des hallucinations peut améliorer la fiabilité et la précision des modèles d’IA générative. Les entreprises peuvent mettre en œuvre un certain nombre de stratégies pour aider à prévenir les hallucinations de l’IA.
La base : régler la température du modèle
C’est souvent un élément méconnu par les néophytes, car généralement inaccessible à travers les interfaces comme ChatGPT. Les chercheurs en IA qui développent les LLM ont mis en place un mécanisme pour inhiber ou exacerber leur créativité, et donc leur propension à halluciner : la température. Ce paramètre, souvent accessible depuis l’API d’un modèle, est généralement compris entre 0 et 1. Si le curseur est placé proche de zéro (par exemple entre 0,2 et 0,5), le modèle fournira les prédictions les plus déterministes et souvent les plus précises. Or, il se peut que le réglage ne convienne pas aux questions plus ouvertes ou aux tâches de création. Dans ce deuxième cas, il convient de choisir une température plus proche de 1, mais l’exposition aux hallucinations est statistiquement plus importante. Un réglage permet généralement de sélectionner automatiquement cette valeur en fonction de la recherche de l’utilisateur.
La température peut être combinée avec la valeur « top-p », comprise entre 0,1 et 1. Cet outil permet de restreindre la réponse aux mots les plus probables de se retrouver les uns à la suite des autres, cumulant un pourcentage déterminé par la valeur « top-p ». Une fois combinés, ces deux mécanismes doivent permettre d’obtenir un équilibre entre précision et créativité.
Prompt Engineering
Il est difficile de maîtriser le prompt écrit par les utilisateurs. Il peut donc être utile de les former aux bonnes pratiques de rédaction de ces messages. S’il s’avère impossible de former les usagers ou que les résultats de l’application sont trop aléatoires, il convient de rédiger le ou les bons system prompts.
Un system prompt est une suite d’instructions qui guide le comportement du modèle en back-office/end.
Par exemple, avant d’appeler l’API d’un modèle, il peut être intéressant de rédiger un message du type :
« Tu es un assistant bienveillant chargé de fournir les réponses les plus précises possibles. Tu réponds uniquement au sujet du marketing » ou « voici la liste des sujets interdits :… ». Bien évidemment, un system prompt correctement constitué est plus volumineux que cet exemple et sûrement plus subtil. Si elle est peu coûteuse, cette approche n’empêche pas les hallucinations.
Génération augmentée par récupération (Retrieval Augmented Generation)
Voilà la méthode la plus populaire pour atténuer les hallucinations. La génération augmentée par récupération (RAG) est une technique puissante de traitement du langage naturel. Elle améliore les performances d’un modèle d’IA générative lorsqu’il est confronté à une requête ou à une tâche en incorporant une composante de recherche.
Une architecture RAG implique l’enrichissement des réponses d’un LLM en lui fournissant un contexte et des informations spécifiques directement liées à la requête. Le modèle d’IA peut alors générer une réponse basée non seulement sur ses connaissances préentraînées et la requête d’entrée, mais aussi sur les informations qu’il a récupérées.
Pour aider un LLM à comprendre le contexte qui lui est fourni, il faut « encoder » le texte. Ce procédé se nomme la vectorisation. Un autre modèle de GenAI ou un transformer NLP a la tâche de convertir les documents fournis en vecteurs ; il s’agit de séries de décimales comprises entre -1 et 1. Elles seront comparées avec la requête de l’utilisateur du LLM. Pour ce faire, ces vecteurs sont stockés dans une base de données, puis indexés. Quand l’application qui cache le LLM est utilisée, une mécanique s’enclenche pour poser la question à un moteur de recherche qui trie les résultats les plus pertinents de l’index, puis envoie les éléments au LLM qui compose sa réponse et renvoie le résultat vers l’interface.
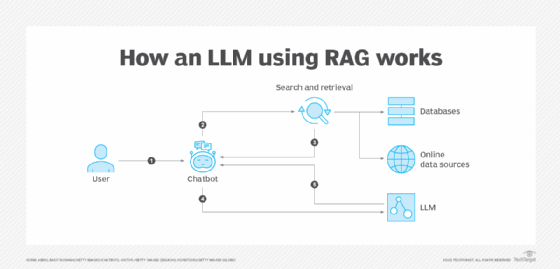
Étant donné leur conception, les architectures RAG ancrent leurs réponses dans des sources connues. Cet ancrage contextuel permet de récupérer des données préexistantes pertinentes ou en temps réel avant de générer une réponse, ce qui contribue à empêcher le modèle d’halluciner ou de générer de fausses informations.
Les résultats sont généralement plus précis, car les réponses des modèles RAG utilisent des sources crédibles (par exemple, Google Search) ou des sources primaires vérifiées. Les entreprises qui conçoivent des applications d’IA dans des domaines où la précision est primordiale, comme la médecine, le droit ou la science, devraient envisager de faire de la RAG une exigence de leur projet.
De plus, les bases de données sur lesquelles s’appuie l’architecture RAG peuvent être mises à jour indépendamment des modules de recherche, d’embedding ou du LLM lui-même.
Un nettoyage rigoureux des données s’impose
L’architecture RAG a déjà fait ses preuves, mais pour maximiser la qualité des résultats et éviter les hallucinations, une validation et un nettoyage des données s’imposent.
L’effort à faire à ce niveau dépend fortement du cas d’usage. Si l’architecture RAG doit aider un collaborateur à trouver une information utile à l’accomplissement d’une tâche (par exemple le déroulé d’un processus et les informations nécessaires à son application), alors l’on s’attend à ce que l’ensemble des documents soient vérifiés.
Dans certains cas, ce travail a déjà été effectué : par exemple, un agent humain peut être interrogé sur une condition spécifique de son contrat. Cette information résidera selon toute vraisemblance dans les conditions générales de ventes, un document souvent public, approuvé par une équipe juridique.
Dans d’autres, il se peut que ce travail soit plus complexe. C’est généralement le cas lorsque l’information est moins structurée ou que la question demande de compiler les éléments en provenance de plusieurs parties du document ou de nombreux documents. Certains documents ne sont peut-être plus valables, n’ont pas été vérifiés ou existent en plusieurs versions.
Il se peut aussi que la diversité des formats de documents ou des langues dans lesquelles ils sont rédigés perturbe le processus de recherche.
Dès lors, de bonnes pratiques s’imposent. En voici quelques-unes :
- La normalisation des formats de données ;
- Idéalement, leur étiquetage ;
- La suppression ou correction des données inexactes ou corrompues ;
- La mise en place de mécanismes pour s’assurer que les données assimilées par le système RAG sont intègres ou qu’elles ne peuvent pas être modifiées en cas d’intrusion dans le système.
En clair, un marécage de PDF non vérifiés est un environnement propice aux hallucinations.
Mécanismes de post-validation et d’oubli contextuel
Si le moteur de recherche de la base documentaire a fait ses preuves, il peut être utilisé pour vérifier le résultat du LLM. Un algorithme distinct ou un module du même moteur peut être utilisé pour établir un score de certitude concernant la réponse du LLM. Un score qu’il convient d’afficher à l’utilisateur. Ce même moteur ou un moteur de règles peut être utilisé pour établir une liste noire de termes improbables ou interdits.
Une Gateway API, comme celles proposées par MuleSoft ou Nvidia, peut aider à interdire l’usage de certains termes ou à filtrer les réponses en fonction du rôle dans une entreprise de l’usager. Autre intérêt, la requête n’a même pas besoin d’être envoyée au moteur de recherche et au LLM. La même API peut être utilisée pour demander au modèle de régénérer une réponse en cas d’hallucinations ou de tout simplement ne pas l’afficher à l’utilisateur.
Or des règles ne suffisent pas à cartographier le comportement du modèle. L’on peut envisager l’usage d’un LLM as a judge. Cela consiste à confier la tâche de juger les résultats d’un LLM à un autre LLM plus expert d’un domaine, ou qui est entraîné à repérer des contenus toxiques afin de contrôler la réponse. Comme un grand modèle de langage dispose d’une plus grande compréhension sémantique qu’un modèle NLP ou un moteur de recherche, il sera plus à même de détecter des biais ou des hallucinations liés au contexte. Or, comme ce LLM as a judge peut avoir assimilé le même jeu de données de base que celui qu’il juge et qui est potentiellement entraîné par la même équipe, l’on n’est pas à l’abri de biais de sur-validation.
Une méthode moins coûteuse et plus fiable consiste à appliquer la technique de l’oubli contextuel. En clair, il s’agit de réduire la fenêtre de contexte afin que le modèle ne soit pas influencé par les précédents échanges.
Mise en cache des réponses les plus pertinentes
Là encore peu coûteuse, une autre technique consiste à mettre les questions et les plus pertinentes en cache. En clair, quand le système d’IA reçoit une question relative à un sujet connu, il renverra une réponse présente dans un système de type Redis. Il est également possible de suggérer ces questions dans l’interface afin d’orienter le comportement des utilisateurs.
Fine-tuning du modèle d’embedding et du LLM
Cela ne peut pas suffire. De fait, un modèle d’IA générative conserve la mémoire de distributions statistiques lui permettant de comprendre une phrase et de prédire le prochain mot dans une phrase. Or du fait qu’une entreprise peut employer un lexique spécifique – ce qui implique souvent qu’un mot d’usage courant n’ait pas le même sens dans cette entreprise –, le modèle produira des erreurs.
Pour pallier ce problème, l’on ne cherchera pas immédiatement à entraîner le LLM avec les données de l’entreprise, mais d’abord le modèle d’embedding. La méthode la moins coûteuse consiste à appliquer un fine-tuning léger afin que ce modèle de création de vecteurs ait lui-même la connaissance du vocabulaire spécifique. Cela améliorera principalement la précision des recherches et, dans le meilleur des cas, la performance du système. Pour ce faire, plusieurs notebooks sont disponibles depuis la documentation de Hugging Face ou de LlamaIndex, par exemple.
Par ailleurs, une autre technique d’oubli contextuel consiste à utiliser des modèles d’embedding qui sélectionne uniquement les passages les plus pertinents
Malgré cela, la machine à halluciner peut perdurer. Les LLM peuvent avoir été entraînés avec des données biaisées concernant la race, l’affiliation politique, le sexe, le statut socio-économique et d’autres facteurs qui peuvent fausser les systèmes d’IA et créer des résultats erronés et trompeurs qui nuisent encore plus à certaines catégories de la population.
Cette situation est d’autant plus préoccupante que l’IA est utilisée dans des domaines importants comme l’embauche, l’application de la loi et les transactions financières telles que l’approbation de prêts.
Parce qu’ils sont entraînés avec des données en provenance du Web et que la majorité des équipes qui les créent sont internationales, majoritairement employée par des entreprises américaines, la « lingua franca » est l’anglais, la culture anglo-saxonne.
Si le modèle n’inclut pas la connaissance nécessaire aux cas d’usage, il peut être intéressant d’affiner le LLM. Peu importe la méthodologie choisie – apprentissage par renforcement d’un LLM de base, souvent cher, ou fine-tuning léger, bien moins coûteux –, le processus est itératif et réclame d’appliquer les méthodes de normalisation des données citées plus haut. Il est conseillé d’éviter une trop grande quantité de données synthétiques – générées par un LLM – qui sont réputées pour nuire à la qualité des réponses quand elles sont présentes en trop grandes proportions. Des modèles spécifiques à des domaines commencent à faire leur apparition, comme c’est le cas chez Microsoft Azure ou sur Hugging Face.
Contrôle et test continus des résultats
Pour surveiller et tester en continu les résultats de l’IA, il convient de mettre en œuvre des frameworks automatisés pour les tests unitaires et d’intégration dans les pipelines DevOps. Il est souhaitable de combiner les tests automatisés avec des humains dans la boucle. Les annotateurs fournissent des commentaires, identifient les erreurs et recommandent des pratiques de recyclage des données/résultats pour augmenter la précision du système. Ensuite, les techniques évoquées plus haut peuvent être de nouveau appliquées.
Boucles de retour itératives
Qu’il s’agisse de lancer un chatbot ou un agent, cette boucle d’informations est essentielle.
Dans le cas d’un assistant IA personnalisé, il est assez simple de demander aux utilisateurs d’envoyer leurs commentaires par l’intermédiaire d’un canal Slack de l’équipe ou d’un autre groupe de discussion. Il est également utile de nommer un responsable de l’application dans l’équipe pour répondre aux questions des utilisateurs.
Les applications d’IA bénéficient des mêmes pratiques d’observabilité et de surveillance qui devraient déjà être en place, dont :
- Le traçage distribué pour suivre les requêtes à travers les microservices.
- La journalisation et la surveillance complètes pour consigner les mesures critiques et surveiller la santé et les performances.
- La surveillance des performances des modèles, y compris le suivi de la précision et des mesures de performance des modèles d’IA en production
- La détection de dérive des modèles pour garantir la précision au fil du temps.






