Comment déboguer le plantage d’un serveur Linux
Cet article est un guide pratique pour trouver la cause d’un Kernel panic sur une machine Linux, et éviter que ses plantages ne se répètent à l’avenir.
Sous Linux, Le « Kernel panic » est un problème critique qui se manifeste par un gel du système. Si vous ne savez pas ce qu’est un kernel, sachez qu’il s’agit du noyau d’un système d’exploitation, ce module central qui gère l’exécution tâches, les sessions des utilisateurs et les pilotes du matériel. Le Kernel Panic est un événement provoqué par une erreur suffisamment grave au niveau du noyau. Sous Windows, il s’agit du fameux « écran bleu de la mort ». Sous Linux, on voit simplement un journal de bord sur un écran noir.
Si cette situation arrive sur l’une de vos machines, la redémarrer simplement pour remettre en route son application ne servira pas à résoudre le problème dont elle souffre et ses plantages continueront de se répéter. Le Kernel panic peut se produire à cause d’une barrette mémoire défaillante, du plantage d’un pilote, de logiciels malveillants ou de bugs logiciels. Cet article a pour but de vous montrer comment déterminer la cause du problème. Lorsque vous aurez identifié le coupable, un composant logiciel ou matériel, il vous suffira de l’éliminer ou de le remplacer.
La mise en place : une victime et un serveur NFS pour l’analyser
Les outils que nous allons utiliser sont le service kdump pour collecter les données du plantage et le programme crash pour investiguer les causes profondes qui permettront de déterminer comment dépanner le système.
Pour commencer, vous devez avoir deux machines virtuelles qui exécutent CentOS. Ce guide pratique met en scène deux machines, un serveur NFS et une machine cliente, qui fonctionnent tous deux sous la distribution Linux CentOS 8.
Le scénario consiste à configurer notre client pour qu’il envoie les relevés de ses plantages système vers le partage en NFS, de sorte à pouvoir analyser le plantage, sans devoir utiliser la machine victime d’un Kernel panic.
Le serveur NFS a l’adresse IP 192.168.99.1 et le client l’adresse IP 192.168.99.71. Vos adresses peuvent différer en fonction de la configuration de votre sous-réseau, mais retenez-les, car ces deux adresses sont nécessaires pour cet exercice.
Autre élément à retenir, le numéro de version du noyau que nous allons faire planter. Au moment de l’écriture initiale de cet article, la version du noyau sur CentOS 8 était la 4.18.0-147.5.1.el8_1.x86_64. Pour trouver la version du noyau Linux de votre distribution, utilisez la commande uname-r.
Installez NFS
Une fois que vous avez configuré vos machines virtuelles et que vous avez relevé leurs adresses IP, il convient de tout installer en suivant les étapes suivantes :
1/ Connectez-vous au serveur NFS et utilisez la commande yum install -y nfs-utils pour installer le paquet NFS.
2/ Créez un répertoire qui sera utilisé pour le partage en NFS avec la commande mkdir /nfs-share.
3/ Modifiez le fichier /etc/exports pour permettre au client de se connecter au partage NFS. Pour éditer un fichier vous utiliserez idéalement l’éditeur nano : nano /etc/exports.
Entrez la ligne suivante, sachant que l’adresse IP indiquée ici est celle du client :
/nfs-share 192.168.99.71(rw,sync,no_root_squash)
4/ Connectez-vous au client et créez un répertoire pour stocker les fichiers des relevés du plantage. Le répertoire que kdump utilise par défaut est /var/crash. Nous allons plutôt utiliser un répertoire /crash-dump à la racine du disque. Créez-le avec la commande :
mkdir /crash-dump
5/ Montez dans ce répertoire le répertoire partagé par le serveur NFS. L’adresse IP indiquée ici est celle du serveur NFS :
mount -t nfs 192.168.99.1:/nfs-share /crash-dump
Nous avons à présent sur le client, un chemin /crash-dump qui ne conduit pas à un répertoire local, mais qui va rediriger tous ses accès, en particulier les écritures que kdump voudra y faire, via le réseau, via le protocole NFS, vers le répertoire /nfs-share du serveur NFS.
Mettez en place les outils
6/ Kdump est automatiquement installé sur CentOS 7 et 8. Sur le client, lancez la commande systemctl kdump status pour vérifier que c’est bien le cas. L’affichage suivant devrait apparaître :
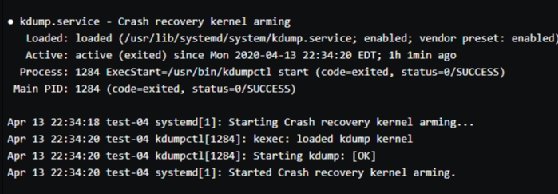
7/ Nous analyserons les relevés produits par kdump avec un outil de débogage intégré à Linux qui s’appelle tout simplement crash. Toutefois, pour que crash puisse interpréter les relevés issus d’un plantage du noyau, nous devons lui fournir un dictionnaire spécifique : le paquet kernel-debuginfo. Pour installer ce paquet, éditez sur le client et sur le serveur le fichier texte /etc/yum.repos.d/CentOS-Debuginfo.repo et assurez-vous qu’il contienne la ligne : enabled=1.
Puis, installez le paquet avec la commande :
yum install -y kernel-debuginfo
8/ À présent, modifiez l’emplacement par défaut où kdump enregistre ses fichiers. Pour ce faire, éditez /etc/kdump.conf, et remplacez-y le chemin par défaut path /var/crash par path /crash-dump.
Faites planter le noyau Linux
Voici maintenant la partie amusante : vous devez faire planter le noyau sur le client.
9/ Entrez les deux commandes echo ci-dessous sur le client :
echo 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
echo 1 > /proc/sys/kernel/sysrq autorise toutes les fonctions de SysRq, en particulier le fait de pouvoir envoyer des commandes directement au noyau.
echo c > /proc/sysrq-trigger envoie au noyau une commande sysrq qui déclenche un plantage.
À ce moment, kdump devrait envoyer ses relevés de plantage dans /crash-dump, c’est-à-dire le nom local du partage qui se trouve sur le serveur NFS.
10/ Connectez-vous à nouveau au serveur NFS et vérifiez si les fichiers de relevés lui ont bien été envoyés.
Dans le répertoire /nfs-share, vous devriez voir un nouveau répertoire lorsque vous utilisez la commande ls -lh. Dans notre exemple, il s’appelle 192.168.99.71-2020-04-14-12:20:47. Ce répertoire est donc celui que kdump vient de créer depuis le client, au moment du crash.
À l’intérieur de ce répertoire, localisez les deux fichiers suivants : vmcore et vmcore-dmesg.text. Vmcore-dmesg.txt est le fichier de log, en texte clair, du service dmesg au moment du crash. Vmcore sera pour sa part utilisé dans l’utilitaire de débogage pour rechercher les processus et les fichiers qui ont potentiellement causé le plantage.
11/ Inspectez le fichier vmcore-dmesg.txt. Vous pouvez visualiser rapidement son contenu en l’ouvrant dans un éditeur de texte, mais le plus efficace est de n’afficher dans notre terminal que les seules lignes de ce fichier qui contiennent le mot crash. Pour ce faire, il suffit de saisir l’enchaînement de commandes suivant :
cat vmcore-dmesg.txt | grep -i crash
Sans équivoque, vous verrez apparaître la mention de la commande coupable : SysRq.
Investiguez avec l’outil de débogage
L’outil qui sert à analyser un relevé de crash s’appelle tout simplement crash. Il est préinstallé sur CentOS 8. Il s’accompagne de commandes pour exécuter et déterminer quels processus et quels fichiers étaient actifs au moment du crash.
12/ Sur le serveur NFS, lancez l’utilitaire crash en lui fournissant le fichier vmcore et en lui indiquant le dictionnaire propre à notre noyau avec la commande suivante :
crash /nfs-share/vmcore /usr/lib/debug/lib/modules/4.18.0-147.5.1.el8_1.x86_64/vmlinux
Cela change l’invite du Shell en un nouvel invite « crash ». Crash est en effet lui-même un programme interactif qui attend que vous entriez des commandes correspondant au type de rapport que vous souhaitez consulter.
13/ Utilisez par exemple la commande ps pour afficher tous les processus qui étaient en cours de fonctionnement au moment du plantage. L’affichage pourrait ressembler à ceci :
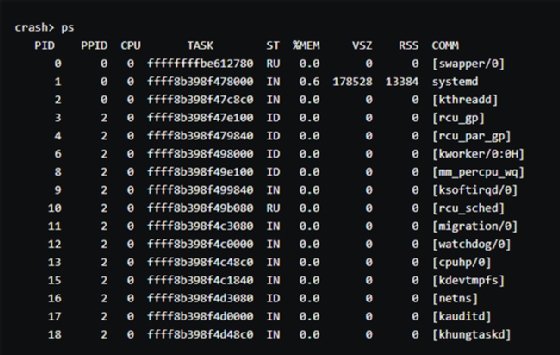
14/ La commande vm liste tout ce qui était chargé dans la mémoire virtuelle au moment du plantage :
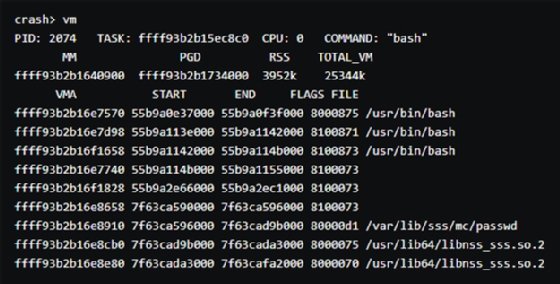
15/ La commande files indique tous les fichiers ouverts au moment du plantage :
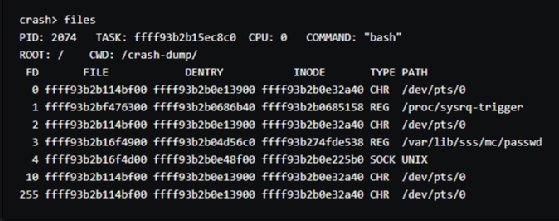
16/ Enfin, la commande log permet de voir les logs. Cela dit, les informations affichées sont les mêmes que celles contenues dans le fichier vmcore-dmesg.txt.
Pour approfondir sur Administration de systèmes
-
![]()
Gérez l’espace de stockage avec les commandes du et df de Linux
Par: Damon Garn
-
![]()
Sauvegarde Linux : comment utiliser les commandes dump et restore
Par: Damon Garn
-
![]()
26 commandes Linux pour administrer le stockage
Par: Damon Garn
-
![]()
Linux : Comment sauvegarder et restaurer des fichiers avec tar
Par: Damon Garn



