
arthead - stock.adobe.com
Données synthétiques ou réelles : quel choix pour l'analytique prédictive ?
Les données synthétiques permettent de simuler des événements rares et de respecter les réglementations, tandis que les données réelles préservent la variabilité naturelle nécessaire pour évaluer les modèles dans des conditions imprévisibles.

Les données synthétiques permettent de simuler des événements rares et de respecter les réglementations, tandis que les données réelles préservent la variabilité naturelle nécessaire pour évaluer les modèles dans des conditions imprévisibles.
Les ingénieurs de données sont confrontés à un paradoxe. Entraîner des algorithmes prédictifs efficaces réclame plus de données, mais l’accès aux données réelles s’avère de plus en plus limité par des contraintes de confidentialité, de sécurité et réglementaires.
Que sont les données synthétiques ?
Contrairement aux événements et enregistrements existants dans les systèmes en production, les données synthétiques sont créées artificiellement pour reproduire les caractéristiques de véritables données.
Pour les data scientists et les ingénieurs en IA, c’est un outil qui peut améliorer considérablement les performances et la robustesse de leurs modèles et de leurs pipelines de données.
Cependant, une telle approche n’est pas sans risques. Des enjeux d’éthiques, de gouvernance et de qualité de données sont toujours présents, même si les données sont « fausses ».
Quels sont les types de données synthétiques ?
Il y a deux grands types de données synthétiques :
- Les données entièrement synthétiques. Créées à partir de zéro à l’aide d’algorithmes ou de modèles d’IA génératives tels que les réseaux antagonistes génératifs (GAN), ou les auto-encodeurs variationnels.
- Les données partiellement synthétiques. Elles sont engendrées en remplaçant uniquement les attributs sensibles dans des ensembles de données réels.
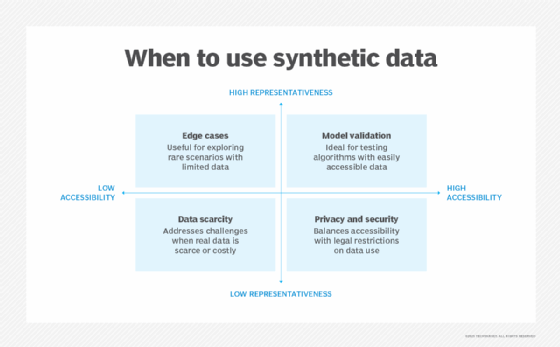
Générer des données synthétiques
Les techniques de génération de données synthétiques ont considérablement évolué. Les premiers modèles reposaient sur des systèmes basés sur des règles et des procédés statistiques élémentaires. Les jeux de données « échantillons » provenant de données ou d’éditeurs de solutions BI, elles découlaient souvent des règles basiques qui définissent les plages de valeurs et les modèles de valeurs de données dans une colonne spécifique.
Les ingénieurs modernes utilisent diverses méthodes de génération qui s’appuient sur ces premières approches. Les méthodes les plus simples comprennent l’échantillonnage aléatoire à partir de distributions statistiques. Elles reflètent les caractéristiques des données d’origine. Les méthodes plus complexes, telles que la modélisation basée sur des agents, simulent des agents individuels se comportant comme des clients et engendrant des données dans le système.
La véritable innovation provient des techniques de deep learning. Les GAN fonctionnent en mettant en concurrence deux réseaux neuronaux. L’un génère des données synthétiques, tandis que l’autre tente de les distinguer des données réelles. Au fil du temps, les résultats synthétiques commencent à imiter la distribution statistique de l’ensemble de données réelles. Cette méthode permet de reproduire des modèles complexes tels que la perte de clientèle, le comportement de navigation, les séquences de transactions et les cas marginaux rares. Grâce à ce processus antagoniste, le générateur devient capable de constituer des données synthétiques réalistes.
Les données originales sont supposément représentatives d’un environnement réel. Cela est important, car le modèle génératif ne fait pas la distinction entre les signaux utiles et le bruit intégré, sauf s’il est activement guidé. La validation de la qualité des échantillons originaux est donc une étape essentielle dans la création de ce type de données synthétiques.
En revanche, le nettoyage des données originales sélectionnées (suppression des doublons, des enregistrements incomplets ou des erreurs de saisie) peut convenir pour modéliser les données démographiques des clients, mais elles ne refléteront pas la réalité complexe du comportement des clients qui a donné lieu au jeu de données original.
Gouvernance et données synthétiques
Les données entièrement synthétiques peuvent être précieuses quand certaines réglementations s’appliquent. Elles réduisent le risque de réidentification, car elles ne correspondent pas à une personne réelle.
Outre les techniques entièrement synthétiques, les méthodes partiellement synthétiques, telles que la confidentialité différentielle, ajoutent un bruit soigneusement calibré, afin de protéger les enregistrements individuels tout en conservant les propriétés statistiques.
Par exemple, la confidentialité différentielle peut modifier une date de naissance en ajoutant ou en soustrayant un nombre aléatoire de jours dans une plage donnée. Le résultat n’est plus identifiable par cette date, qui est désormais partiellement synthétique. Elle reste suffisamment proche pour la plupart des modèles analytiques et prédictifs. Cette mécanique est encore complexe à maîtriser : Snowflake qui s’était lancé dans son déploiement considère que l’obfuscation ou l’usage de données entièrement synthétiques sont plus appropriés.
Néanmoins, ces techniques nécessitent une surveillance rigoureuse et ne doivent pas être considérées comme un passe-droit en matière de conformité. Même si les données sont synthétiques, elles sont soumises à des contrôles organisationnels, notamment la gestion des accès et le suivi de la traçabilité des données. Si les analystes BI intègrent des données synthétiques dans des tableaux de bord, les métadonnées doivent clairement indiquer ce qui est réel, ce qui est synthétique et comment cela a été produit.
Quand les données synthétiques sont a priori préférables aux données réelles
Bien que la confidentialité différentielle limite la probabilité qu’un point de données soit relié à une personne réelle, les équipes vérifient rarement les données après leur synthèse. Une piste d’audit reproductible devrait faire partie de chaque pipeline de données synthétiques.
Les données réelles reflètent la complexité du monde, comme les irrégularités, la saisonnalité et l’imprévisibilité. Bien que la collecte de données réelles soit un concept plus simple à comprendre, elle est souvent plus complexe dans la pratique.
Elle est généralement coûteuse et chronophage, particulièrement dans des nouveaux cas d’usage ou des expériences. Obtenir l’autorisation de collecter des données réelles dans certaines industries réglementées peut prendre des semaines en raison d’importantes préoccupations liées à la confidentialité et à l’éthique. L’obtention du consentement approprié, la garantie de la sécurité des données et la conformité aux réglementations, telles que le RGPD ou HIPAA, renforcent cette complexité.
La notion de biais est une autre préoccupation dans la collecte de données réelles. Les données réelles peuvent refléter des modèles existants qui ne sont plus appropriés ou représentatifs. Par exemple, les femmes ou les minorités pourraient être sous-représentées dans certains ensembles de données d’assurance remontant à plusieurs années. Moins controversées, mais tout aussi problématiques, les données collectées auprès d’un fournisseur de téléphonie mobile réverbéreront les habitudes d’utilisation d’anciens forfaits et appareils, moins pertinents aujourd’hui. Les modèles entraînés sur ces données risquent de perpétuer, voire d’amplifier ces distorsions.
Cependant, dans certains cas, les données réelles peuvent être si uniformes que les événements rares ou les cas limites peuvent être difficiles à modéliser statistiquement. Par exemple, un modèle d’alerte de fraude pour un système de traitement des transactions peut ne pas inclure suffisamment d’exemples pour entraîner efficacement l’algorithme.
Pour ces scénarios, les données synthétiques offrent un contrôle total sur le processus, permettant la création d’ensembles de données de test qui incluent des événements absents des données réelles.
Quelles sont les limites des données synthétiques ?
Dans la pratique, la fiabilité des données synthétiques dépend de celle des modèles et des hypothèses utilisés pour les générer. Si la compréhension sous-jacente des phénomènes cibles est incomplète ou erronée, ces limites se retrouveront dans les données synthétiques et les systèmes qui en découlent. De plus, les données synthétiques risquent de ne pas refléter certaines corrélations inattendues ou certaines tendances subtiles observées dans le monde réel.
Parfois, les modèles entraînés avec des données synthétiques fonctionnent bien dans des environnements contrôlés, mais rencontrent des difficultés lorsqu’ils sont confrontés à des usages en production. Pour les prévisions, les données réelles sont préférables si elles sont suffisantes, facilement accessibles, conformes à la réglementation et toujours adéquates.
La simulation de scénarios hypothétiques, tels qu’un nouveau segment de marché, manque souvent de données historiques de référence pertinentes. C’est là que les données synthétiques prennent tout leur sens. Une approche efficace consiste à entraîner les modèles sur des données réelles, puis à les soumettre à des tests de résistance à l’aide de données synthétiques. De cette manière, vous pouvez émuler un événement tel qu’une crise financière, une catastrophe météorologique ou un phénotype rare chez un patient.
Certains critiques soulignent que le recours excessif aux données synthétiques crée un faux sentiment de sécurité. Si des décisions qui affectent la vie des gens sont prises sur la base de modèles entraînés à partir de données synthétiques, comment peut-on être sûr que ces décisions sont justes et fiables ?
C’est une préoccupation légitime. Les données réelles offrent une authenticité et reflètent la complexité et les nuances du monde réel, y compris les relations et les schémas difficiles à anticiper. Mais les données réelles posent également des défis. Elles sont souvent incomplètes, biaisées ou comportent des risques importants en matière de confidentialité et des contraintes réglementaires que les données synthétiques peuvent aider à atténuer.
Cas d’usage et patterns industriels
Plusieurs secteurs utilisent déjà les données synthétiques de manière pratique et spécifique à leur domaine.
Dans le secteur financier, les données transactionnelles synthétiques favorisent une collaboration sécurisée entre les institutions en permettant l’échange de variantes sans exposer l’identité des clients. Cela permet d’améliorer les modèles de détection des fraudes sans avoir recours à des données sensibles.
Il n’est pas toujours facile d’employer les données de cette manière. Les données synthétiques peuvent reproduire des modèles de fraude connus, mais il est difficile de générer des nouveaux comportements. Néanmoins, les équipes trouvent cela utile pour tester la sensibilité des modèles aux changements de seuil ou aux conditions défavorables.
Dans le domaine de la santé, les données synthétiques ont considérablement fait progresser le développement de l’IA. L’entraînement de modèles à partir de dossiers synthétiques de patients permet de concevoir des algorithmes sans exposer les informations médicales personnelles. Cette approche accélère l’innovation tout en préservant la confidentialité des patients. Des chercheurs ont créé des scanners CT et des résultats de laboratoire synthétiques pour des maladies rares afin de soutenir en toute sécurité la R&D pharmaceutique.
Dans le domaine du développement des véhicules autonomes, les données de simulation synthétiques sont précieuses pour tester les situations dangereuses telles que les accidents ou le comportement imprudent des piétons. C’est essentiel pour la sécurité des systèmes de conduite autonome, mais elles sont rares et il serait néfaste de les recréer avec des êtres vivants. Les simulations synthétiques, complétées par des tests en conditions réelles, garantissent la sécurité dans divers environnements et conditions.
Quand utiliser quoi ?
Ce tableau résume certains critères courants permettant de choisir quand utiliser des données réelles et des données synthétiques :
| Scénario |
Données Synthétiques |
Données réelles |
Notes |
| Événements rares/cas limites |
Recommandé : Générer rapidement des milliers de cas limites |
Limite : Cela peut prendre des années pour collecter suffisament d’échantillons |
Utilisez des données synthétiques pour enrichir les données réelles. Vérifiez leur validité sur des échantillons réels lorsque ceux-ci sont disponibles. |
| Applications sensibles |
Recommandé : Conformité réglementaire, minimisation des données |
Haut risque : exposition de données personnelles, contraintes réglementaires |
Documentez le processus de génération de données synthétiques à des fins d’audit. |
| Tests de systèmes et de pipelines |
Recommandé : scénarios de tests contrôlés et répétables |
Risqué : peut exposer des données de production à travers les environnements de tests |
Les données synthétiques permettent d’effectuer la très grande majorité des tests sans accéder aux données de production |
| Entraînement de modèles (Initial) |
Bon : itération rapide, labélisation automatisée |
Essentiel : vérité terrain, distributions réelles |
Commencez avec la compréhension des données réelles, poursuivez avec des données synthétiques. |
| Validation de modèles (Final) |
Insuffisant : pourrait manquer la complexité du monde réel |
Requis : la seule manière de vérifier les performances des modèles |
Ne jamais déployer un modèle sans une validation sur des données réelles. |
| Prototypage de tableaux de bord |
Recommandé : Pas d’accès à la production |
Contraintes d’accès : peut ralentir le développement |
Utilisez des éléments synthétiques pour la conception, puis passez à des éléments réels pour la mise en service. |
| Demandes d’autorisation réglementaire |
Dépendance au contexte : Documentez précisément votre méthodologie |
Recommandé : Plus grande confiance de la part des autorités |
Les approches hybrides sont souvent les plus efficaces en matière de conformité. |
Combiner des données synthétiques et réelles
Une méthode efficace pour utiliser conjointement les données synthétiques et réelles consiste à respecter un processus itératif. Commencez par un ensemble réduit de données réelles pour générer des enregistrements synthétiques et entraîner les modèles initiaux. Validez en second lieu ces modèles sur des données réelles et affinez la génération synthétique à l’aide des résultats améliorés. Cela permet de tirer parti des atouts des deux types de données tout en atténuant leurs faiblesses.
Une documentation claire est essentielle pour suivre où et comment les données synthétiques sont utilisées. C’est particulièrement vrai pour les applications à haut risque dans les domaines de la finance ou de la santé. Une provenance solide des données et une transparence quant à leur origine favorisent le respect des normes éthiques et la conformité réglementaire.
Il est tout aussi important de procéder à une évaluation rigoureuse afin de déterminer dans quelle mesure les données synthétiques préservent les propriétés statistiques des données sources et si elles introduisent des distorsions.
Les experts du domaine doivent jouer un rôle central dans l’appréciation de leur qualité. La similitude statistique n’est pas suffisante : les données doivent avoir un sens pour un expert métier.
En fin de compte, le choix entre des données synthétiques ou réelles dépend du scénario modélisé et de la phase de développement du modèle ou du système. Ce tableau clarifie les moments où certains choix doivent être faits.
| Phase |
Source primaire |
Source secondaire |
Approche de validation |
| Recherche/exploration |
Données réelles |
Données synthétiques pour combler les manques |
Comparaison statistique des distributions |
| Développement initial |
Données synthétiques |
Échantillons réels pour référence |
Validation périodique sur des données réelles |
| Test de systèmes |
Données synthétiques |
- |
Génération de tests de cas contrôlés |
| Entraînement de modèles |
Hybride (réelles + synthétiques) |
- |
Validation croisée sur les deux sources |
| Validation de la préproduction |
Données réelles (sous-ensemble ou ensemble de validation) |
- |
Métriques de performance uniquement sur des données réelles |
| Supervision de la production |
Données réelles |
- |
Suivi continu des performances en conditions réelles |
Les données synthétiques, une affaire de stratégie
Avec l’émergence de l’IA, les données synthétiques sont passées d’une technique d’ingénierie des données à un atout stratégique. Elles reflètent la manière dont les équipes gèrent leur confidentialité, leur temps, leur budget et leurs contraintes réglementaires.
Des compromis restent à faire. Les données synthétiques ne constituent pas une approche parfaite, mais elles ont souvent été écartées en raison de préoccupations liées à leur authenticité. Les données synthétiques sont avant tout un outil. Et comme tout outil, il s’agit de l’utiliser à bon escient et au bon moment.
L’avenir des données dans l’analyse prédictive n’est ni synthétique ni réel ; il est à la fois synthétique et réel, fonctionnant intelligemment de manière conjointe.
Donald Farmer est un stratège en données avec plus de 30 ans d’expérience, notamment en tant que chef d’équipe produit chez Microsoft et Qlik. Il conseille des clients internationaux sur les données, l’analytique, l’IA et la stratégie d’innovation, avec une expertise qui s’étend des géants de la technologie aux start-ups. Il vit dans une maison expérimentale en pleine forêt près de Seattle.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
Jumeaux numériques hybrides : quand l’IA corrige la physique en temps réel
Par: Gaétan Raoul
-
![]()
Que sont les données synthétiques ? Exemples, cas d'utilisation et avantages
Par: Nicole Laskowski
-
![]()
Fara-7B : Microsoft explore l’IA agentique pour manipuler les interfaces PC
Par: Gaétan Raoul
-
![]()
Claude Opus 4.5 : Anthropic répond (encore) à OpenAI et à Google
Par: Gaétan Raoul



