
Splunk : le point sur l’architecture et le langage SPL
Cet article revient sur la mécanique qui se cache derrière Splunk, la plateforme analytique spécialisée dans les données « machines » et sur son langage propre, SPL.

Dans sa vision la plus simplifiée, Splunk se résume à trois composantes. Un CLI, une interface Web super intuitive écrite en Python et Ajax et un daemon en C++ qui réalise la collection de données, l’indexation, la recherche et fournit des API accessibles en REST qui permet son intégration avec n’importe quel framework Web. L’ensemble s’appuie sur un « data store » distribué et propriétaire (bien qu’inspiré à l’origine de GFS ‘Google File System’).
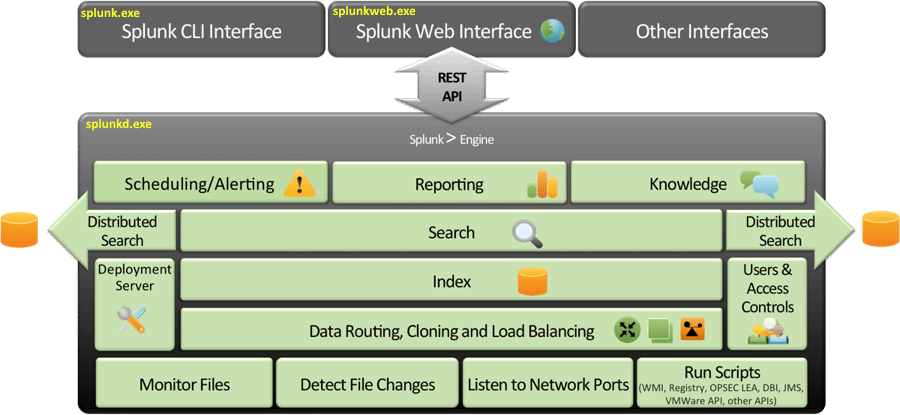
Architecture de Splunk
Une étude plus détaillée de l’architecture met en évidence trois composantes fondamentales destinées à simplifier une implémentation très distribuée dans un pur esprit « Big Data » :
* Les « Splunk Search Heads » jouent le rôle de Master Nodes et concrétisent les recherches à travers tous les « Data Store ». Les Search Heads savent quel nœud « Splunk Indexer » appeler et quel index interroger. Les serveurs « Search Heads » exécutent le CLI et l’interface Web.
* Les « Splunk Indexers » sont les « slave nodes » typiques d’une architecture BigData. Typiquement, ils sont dédiés à l’exécution du Daemon Splunk. Ils analysent la donnée reçue, ils l’indexent selon une syntaxe spécifique (transformant le flux de caractère en « évènements »), et ils la préparent pour le stockage.
* Les « Splunk Forwarders » sont les agents collecteurs de logs. Installés au plus proche des sources de données, ils sont chargés de transférer les données vers les « Indexers ». Splunk dispose de quelques Forwarders atypiques qui, plutôt que de balayer les journaux, permettent de directement capturer des données sur un flux réseau par exemple. Dans un même ordre d’idées, depuis la version 6.3, Splunk propose des API HTTP/JSON pensées pour l’IoT et les processus DevOps afin d’ingérer directement des données à raison de millions d’évènements par seconde sans passer par des agents.
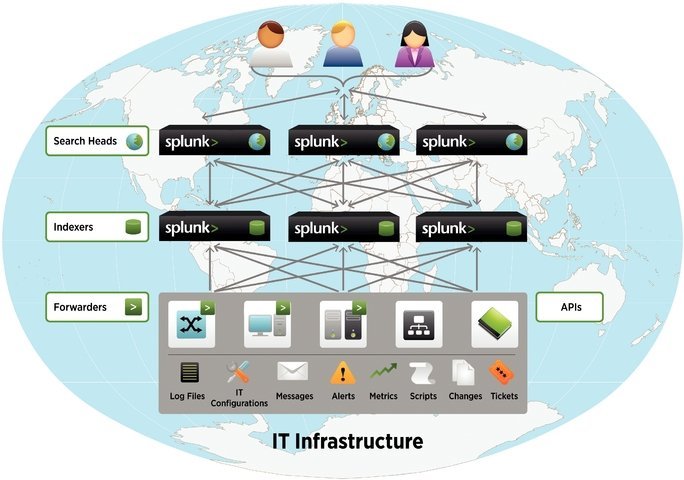
L’implémentation distribuée de Splunk permet ainsi à certaines entreprises d’ingurgiter et indexer quelques 1,2 Peta-octets de logs par jour.
Pour Philippe Bourrel, ancien développeur Splunk chez Umanis aujourd’hui chez Tisséo, la souplesse de cette architecture est l’une des grandes qualités du logiciel : « Splunk peut facilement être décliné dans un contexte d'architecture modeste en ayant une entité de l'outil qui assure toutes les fonctions de collecte, indexation, recherche et restitution. Mais il peut aussi être décliné en architecture ultra distribuée comme nous la connaissons au sein notre environnement de travail qui nous impose de respecter des normes de cloisonnements architecturaux stricts par respect pour les normes de sécurité. Splunk s’y conforme aisément en se déclinant en autant de versions déployables au travers de ses entités spécialisées : agents collecteurs (très peu gourmands en ressource), renvoyant eux-mêmes vers des indexeurs en cluster qui finalement mettent la donnée à disposition d'entités spécialisées dans la recherche / restitution des données ».
Le langage SPL (Search Processing Language)
L’une des particularités de Splunk, c’est qu’au final toute opération se concrétise par une requête sur le moteur de recherche sous-jacent, véritable cœur du logiciel, dans le langage propre au logiciel : SPL.
Avec le temps, SPL s’est considérablement enrichi et demeure l’un des grands atouts du produit. C’est un langage particulièrement adapté à l’exploration d’une immense collection de données non structurées offrant des opérations statistiques et analytiques avancées (y compris du Machine Learning) applicables à des contextes donnés. Certes, il est aussi possible de se contenter de saisir un mot clé (comme un nom d’utilisateur, un code erreur ou un nom de programme) et découvrir combien de fois il apparaît sur une période donnée. Mais SPL aspire à des requêtes à la fois plus élaborée et plus parlante notamment lorsqu’on combine les instructions capables de mettre en exergue d’éventuelles corrélations entre des données de sources aussi variées qu’indépendantes.
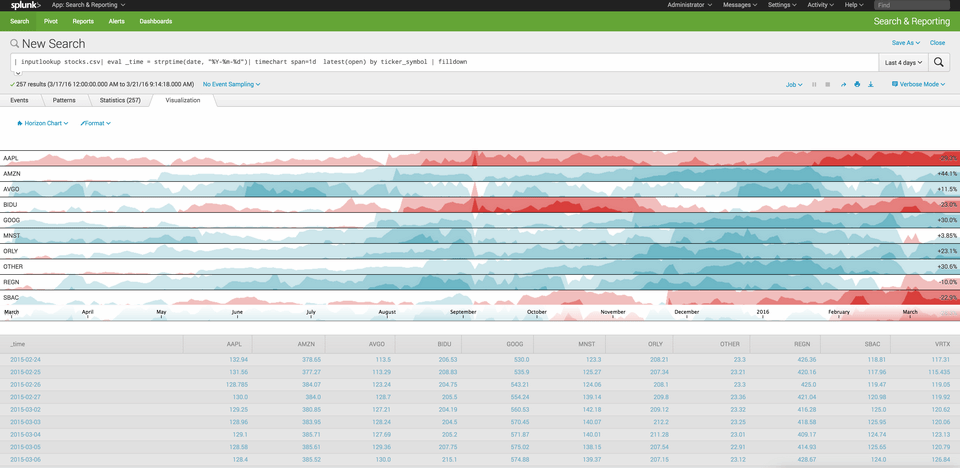
En pratique, demander à Splunk d’afficher une vue distribuée au fil du temps des applications qui prennent le plus de temps à démarrer, en évaluant la moyenne des temps de démarrage de chaque application, s’exprime simplement par une commande :
« index=agent_myapp sourcetype=agent_myapp:Process:ProcessStartup | timechart avg(StartupTimeMs) by Name »
Splunk retourne alors un graphique dynamique et interactif qui permettra de zoomer, à l’aide de la souris, sur certaines applications ou certaines périodes temporelles et de réaliser du Drill down jusqu’au contenu des Logs.
Pour approfondir sur Administration de systèmes
-
![]()
Lakewatch : à son tour, Databricks s’invite sur le marché du SIEM
Par: Gaétan Raoul
-
![]()
AgenticOps et SOC agentique, les concepts inédits de Splunk
Par: Yann Serra
-
![]()
Observabilité : Datadog pousse une stratégie hybride dans un marché en mutation
Par: Gaétan Raoul
-
![]()
Elastic automatise la migration vers son SIEM à coup d’IA générative
Par: Gaétan Raoul



