Big Data

Qu'est-ce que le big data ?
Les big data sont une combinaison de données structurées, semi-structurées et non structurées que les organisations collectent, analysent et exploitent pour en tirer des informations et des idées. Elles sont utilisées dans les projets d'apprentissage automatique, la modélisation prédictive et d'autres applications analytiques avancées.
Les systèmes qui traitent et stockent les données volumineuses sont devenus un élément courant des architectures de gestion des données dans les organisations. Ils sont associés à des outils qui soutiennent les utilisations analytiques des big data. Les big data sont souvent caractérisées par les trois V :
- Le grand volume de données dans de nombreux environnements.
- La grande variété de types de données fréquemment stockées dans les systèmes de big data.
- La vitesse à laquelle les données sont générées, collectées et traitées.
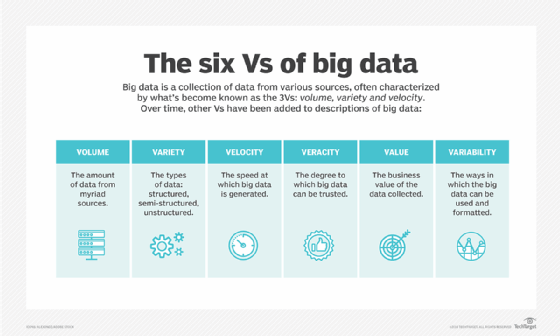
Doug Lany a identifié pour la première fois ces trois V du big data en 2001, alors qu'il était analyste au sein de la société de conseil Meta Group Inc. Gartner les a popularisés après avoir acquis Meta Group en 2005. Plus récemment, plusieurs autres V ont été ajoutés à différentes descriptions du big data, notamment la véracité, la valeur et la variabilité.
Bien que les big data ne correspondent pas à un volume spécifique de données, les déploiements de big data impliquent souvent des téraoctets, des pétaoctets, voire des exaoctets de points de données créés et collectés au fil du temps.
Pourquoi les big data sont-elles importantes et comment sont-elles utilisées ?
Les entreprises utilisent le big data dans leurs systèmes pour améliorer l'efficacité opérationnelle, fournir un meilleur service clients, créer des campagnes de marketing personnalisées et prendre d'autres mesures susceptibles d'augmenter les revenus et les bénéfices. Les entreprises qui utilisent efficacement le big data détiennent un avantage concurrentiel potentiel sur celles qui ne le font pas, car elles sont en mesure de prendre des décisions plus rapides et mieux informées.
Par exemple, le big data fournit des informations précieuses sur les clients que les entreprises peuvent utiliser pour affiner leur marketing, leur publicité et leurs promotions afin d'augmenter l'engagement des clients et les taux de conversion. Les données historiques et en temps réel peuvent être analysées pour évaluer l'évolution des préférences des consommateurs ou des acheteurs professionnels, ce qui permet aux entreprises de mieux répondre aux souhaits et aux besoins des clients.
Les chercheurs médicaux utilisent le big data pour identifier les signes de maladie et les facteurs de risque. Les médecins s'en servent pour diagnostiquer les maladies et les états pathologiques des patients. En outre, une combinaison de données provenant de dossiers médicaux électroniques, de sites de médias sociaux, du web et d'autres sources permet aux organismes de santé et aux agences gouvernementales de disposer d'informations actualisées sur les menaces et les épidémies de maladies infectieuses.

Voici d'autres exemples de l'utilisation des big data par des organisations de différents secteurs :
- Le big data aide les compagnies pétrolières et gazières à identifier les sites de forage potentiels et à surveiller le fonctionnement des pipelines. De même, les services publics s'en servent pour surveiller les réseaux électriques.
- Les entreprises de services financiers utilisent les systèmes de big data pour la gestion des risques et l'analyse en temps réel des données du marché.
- Les fabricants et les entreprises de transport s'appuient sur le big data pour gérer leurs chaînes d'approvisionnement et optimiser les itinéraires de livraison.
- Les agences gouvernementales utilisent les données des bugs pour les interventions d'urgence, la prévention de la criminalité et les initiatives de villes intelligentes.
Quels sont les exemples de big data ?
Les big data proviennent de nombreuses sources, notamment des systèmes de traitement des transactions, des bases de données clients, des documents, des courriels, des dossiers médicaux, des journaux de navigation sur internet, des applications mobiles et des réseaux sociaux. Elles comprennent également les données générées par les machines, telles que les fichiers journaux des réseaux et des serveurs et les données des capteurs des machines de production, des équipements industriels et des appareils de l'internet des objets.
Outre les données provenant des systèmes internes, les environnements big data intègrent souvent des données externes sur les consommateurs, les marchés financiers, les conditions météorologiques et de circulation, les informations géographiques, la recherche scientifique, etc. Les images, les vidéos et les fichiers audio sont également des formes de big data, et de nombreuses applications de big data impliquent des données en continu qui sont traitées et collectées en permanence.
Décomposer les V du big data : Volume, variété et vitesse
Le volume est la caractéristique la plus citée du big data. Un environnement big data ne doit pas nécessairement contenir une grande quantité de données, mais la plupart le font en raison de la nature des données qui y sont collectées et stockées. Les flux de clics, les journaux système et les systèmes de traitement des flux font partie des sources qui produisent généralement des volumes massifs de données sur une base continue.
En termes de variété, le big data englobe plusieurs types de données, dont les suivants :
- Données structurées, telles que les transactions et les dossiers financiers.
- Données non structurées, telles que du texte, des documents et des fichiers multimédias.
- Les données semi-structurées, telles que les journaux de serveurs web et les données en continu provenant de capteurs.
Différents types de données doivent être stockés et gérés dans les systèmes de big data. En outre, les applications de big data comprennent souvent de multiples ensembles de données qui ne peuvent pas être intégrés d'emblée. Par exemple, un projet d'analyse de big data peut tenter de prévoir les ventes d'un produit en corrélant les données sur les ventes passées, les retours, les commentaires en ligne et les appels au service clientèle.
La vélocité fait référence à la vitesse à laquelle les données sont générées et doivent être traitées et analysées. Dans de nombreux cas, les ensembles de big data sont mis à jour en temps réel ou quasi réel, au lieu des mises à jour quotidiennes, hebdomadaires ou mensuelles effectuées dans de nombreux entrepôts de données traditionnels. La gestion de la vitesse des données devient de plus en plus importante à mesure que l'analyse des big data s'étend à l'apprentissage automatique et à l'intelligence artificielle (IA), où les processus analytiques trouvent automatiquement des modèles dans les données et les utilisent pour générer des idées.
Autres caractéristiques du big data : Véracité, valeur et variabilité
Au-delà des trois V initiaux, d'autres sont souvent associés au big data. Il s'agit notamment des suivants :
- La véracité. La véracité fait référence au degré d'exactitude des ensembles de données et à leur fiabilité. Les données brutes collectées à partir de diverses sources peuvent entraîner des problèmes de qualité des données qui peuvent être difficiles à mettre en évidence. Si elles ne sont pas corrigées par des processus de nettoyage des données, les mauvaises données entraînent des erreurs d'analyse qui peuvent saper la valeur des initiatives d'analyse commerciale. Les équipes chargées de la gestion des données et de l'analyse doivent également s'assurer qu'elles disposent de suffisamment de données exactes pour produire des résultats valables.
- Valeur. Certains data scientists et consultants ajoutent également de la valeur à la liste des caractéristiques du big data. Toutes les données collectées n'ont pas une valeur ou des avantages réels pour l'entreprise. Par conséquent, les entreprises doivent s'assurer que les données sont liées à des questions commerciales pertinentes avant de les utiliser dans des projets d'analyse de big data.
- Variabilité. La variabilité s'applique souvent à des ensembles de big data, qui peuvent avoir des significations multiples ou être formatés différemment dans des sources de données distinctes. Ces facteurs peuvent compliquer la gestion et l'analyse des big data.
Certains attribuent encore plus de V aux big data ; plusieurs listes ont été créées, allant de sept à dix.
Comment les big data sont-elles stockées et traitées ?
Les big data sont souvent stockées dans un datalake. Alors que les entrepôts de données (datawarehouse) sont généralement construits sur des bases de données relationnelles et ne contiennent que des données structurées, les lacs de données peuvent prendre en charge différents types de données et sont généralement basés sur des clusters Hadoop, des services de stockage d'objets dans le cloud, des bases de données NoSQL ou d'autres plateformes de big data.
De nombreux environnements big data combinent plusieurs systèmes dans une architecture distribuée. Par exemple, un lac de données central peut être intégré à d'autres plateformes, notamment des bases de données relationnelles ou un entrepôt de données. Les données des systèmes de big data peuvent être laissées à l'état brut, puis filtrées et organisées selon les besoins pour des utilisations analytiques particulières, telles que la veille stratégique (BI). Dans d'autres cas, elles sont prétraitées à l'aide d'outils d'exploration de données et de logiciels de préparation des données afin d'être prêtes pour les applications qui sont exécutées régulièrement.
Le traitement des données volumineuses (big data) impose de lourdes exigences à l'infrastructure informatique sous-jacente. Les systèmes en grappe fournissent souvent la puissance de calcul nécessaire. Ils gèrent les flux de données en utilisant des technologies telles que Hadoop et le moteur de traitement Spark pour répartir les charges de travail sur des centaines ou des milliers de serveurs de base.
Obtenir une telle capacité de traitement de manière rentable est un défi. C'est pourquoi l'informatique dématérialisée est un lieu de prédilection pour les systèmes de big data. Les organisations peuvent déployer leurs propres systèmes basés sur le cloud ou utiliser les offres de big data en tant que service gérées par les fournisseurs de cloud. Les utilisateurs de cloud peuvent augmenter le nombre de serveurs requis juste assez longtemps pour mener à bien les projets d'analyse des données de grande envergure. L'entreprise ne paie que pour le stockage des données et le temps de calcul qu'elle utilise, et les instances cloud peuvent être désactivées lorsqu'elles ne sont pas nécessaires.
Comment fonctionne l'analyse des données massives (big data)
Pour obtenir des résultats valables et pertinents à partir des applications d'analyse des big data, les data scientists et autres analystes de données doivent avoir une compréhension détaillée des données disponibles et une idée de ce qu'ils y recherchent. La préparation des données est donc une première étape cruciale du processus d'analyse. Elle comprend le profilage, le nettoyage, la validation et la transformation des ensembles de données,
Une fois les données collectées et préparées pour l'analyse, diverses disciplines de science des données et d'analyse avancée peuvent être appliquées pour exécuter différentes applications, à l'aide d'outils qui offrent des fonctions et des capacités d'analyse des big data. Ces disciplines comprennent l'apprentissage automatique et son sous-ensemble d'apprentissage profond, la modélisation prédictive, l'exploration de données, l'analyse statistique, l'analyse de flux et l'exploration de texte.
Si l'on prend l'exemple des données sur les clients, les différentes branches de l'analyse qui peuvent être réalisées à partir d'ensembles de données volumineuses sont les suivantes :
- L'analyse comparative. Il s'agit d'examiner les mesures du comportement des clients et l'engagement des clients en temps réel afin de comparer les produits, les services et la marque d'une entreprise avec ceux de ses concurrents.
- L'écoute des médias sociaux. Il s'agit d'analyser ce que les gens disent sur les médias sociaux à propos d'une entreprise ou d'un produit, ce qui peut aider à identifier des problèmes potentiels et à cibler des publics pour des campagnes de marketing.
- Analyse marketing. Elle fournit des informations qui peuvent être utilisées pour améliorer les campagnes de marketing et les offres promotionnelles pour les produits, les services et les initiatives commerciales.
- Analyse des sentiments. Toutes les données recueillies sur l'expérience des clients peuvent être analysées pour révéler ce qu'ils pensent d'une entreprise ou d'une marque, les niveaux de satisfaction des clients, les problèmes potentiels et la manière dont le service à la clientèle pourrait être amélioré.
Technologies de gestion des données massives (big data)
Hadoop, un cadre de traitement distribué open source lancé en 2006, était initialement au centre de la plupart des architectures big data. Le développement de Spark et d'autres moteurs de traitement a relégué MapReduce, le moteur intégré à Hadoop, au second plan. Il en résulte un écosystème de technologies big data qui peuvent être utilisées pour différentes applications mais qui sont souvent déployées ensemble.
Les fournisseurs de technologies de l'information proposent des plateformes de big data et des services gérés qui combinent plusieurs de ces technologies en un seul paquet, principalement pour une utilisation dans le cloud. Pour les organisations qui souhaitent déployer elles-mêmes des systèmes de big data, sur site ou dans le cloud, divers outils sont disponibles en plus de Hadoop et Spark. Ils comprennent les catégories d'outils suivantes :
- Référentiels de stockage.
- Cadres de gestion des clusters.
- Moteurs de traitement des flux.
- Bases de données NoSQL.
- Plateformes de lacs de données et d'entrepôts de données.
- SQL query engines.
Avantages du big data
Les organisations qui utilisent et gèrent correctement de grands volumes de données peuvent en tirer de nombreux avantages, notamment les suivants :
- Amélioration de la prise de décision. Une organisation peut tirer des informations importantes, des risques, des schémas ou des tendances à partir des big data. Les grands ensembles de données sont censés être exhaustifs et contenir autant d'informations que l'organisation en a besoin pour prendre de meilleures décisions. Les connaissances en matière de big data permettent aux chefs d'entreprise de prendre rapidement des décisions fondées sur des données qui ont un impact sur leur organisation.
- Meilleure connaissance des clients et du marché. Les big data qui couvrent les tendances du marché et les habitudes des consommateurs donnent à une organisation les informations importantes dont elle a besoin pour répondre aux demandes des publics auxquels elle s'adresse. Les décisions relatives au développement de produits, en particulier, bénéficient de ce type d'informations.
- Réduction des coûts. Le big data peut être utilisé pour déterminer comment les entreprises peuvent améliorer leur efficacité opérationnelle. Par exemple, l'analyse des big data sur la consommation d'énergie d'une entreprise peut l'aider à être plus efficace.
- Impact social positif. Le big data peut être utilisé pour identifier des problèmes qui peuvent être résolus, comme l'amélioration des soins de santé ou la lutte contre la pauvreté dans une certaine région.
Les défis du Big Data
Les experts en données sont confrontés à des défis communs lorsqu'ils traitent des données volumineuses (big data). Il s'agit notamment des défis suivants :
- Conception de l'architecture. La conception d'une architecture de big data axée sur la capacité de traitement d'une organisation est un défi commun pour les utilisateurs. Les systèmes de big data doivent être adaptés aux besoins particuliers d'une organisation. Ces types de projets sont souvent des entreprises de bricolage qui exigent des équipes informatiques et de gestion des données qu'elles assemblent un ensemble personnalisé de technologies et d'outils.
- Compétences requises. Le déploiement et la gestion des systèmes de big data exigent également de nouvelles compétences par rapport à celles que possèdent généralement les administrateurs de bases de données et les développeurs de logiciels relationnels.
- Les coûts. L'utilisation d'un service de cloud computing géré peut contribuer à maîtriser les coûts. Cependant, les responsables informatiques doivent toujours surveiller de près l'utilisation du cloud pour s'assurer que les coûts ne deviennent pas incontrôlables.
- Migration. La migration des ensembles de données et des charges de travail de traitement sur site vers l'informatique dématérialisée peut être un processus complexe.
- L'accessibilité. L'un des principaux défis de la gestion des systèmes de big data est de rendre les données accessibles aux data scientists et aux analystes, en particulier dans les environnements distribués qui comprennent un mélange de différentes plates-formes et de magasins de données. Pour aider les analystes à trouver les données pertinentes, les équipes de gestion des données et d'analyse créent de plus en plus de catalogues de données qui intègrent des fonctions de gestion des métadonnées et de lignage des données.
- Intégration. Le processus d'intégration des ensembles de big data est également compliqué, en particulier lorsque la variété et la vitesse des données sont des facteurs.

Les clés d'une stratégie efficace en matière de big data
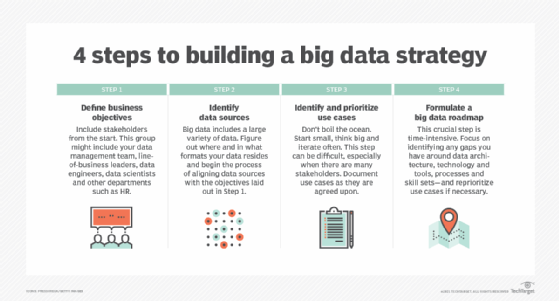
L'élaboration d'une stratégie en matière de big data nécessite une compréhension des objectifs de l'entreprise et des données disponibles, ainsi qu'une évaluation des besoins en données supplémentaires pour atteindre les objectifs. Les prochaines étapes à franchir sont les suivantes :
- Hiérarchiser les cas d'utilisation et les applications prévues.
- Identifier les nouveaux systèmes et outils nécessaires.
- Création d'une feuille de route pour le déploiement.
- Évaluer les compétences internes pour déterminer s'il est nécessaire de procéder à un recyclage ou à une embauche.
Pour s'assurer que les ensembles de données sont propres, cohérents et utilisés correctement, un programme de gouvernance des données et des processus associés de gestion de la qualité des données doivent également être prioritaires. D'autres bonnes pratiques pour la gestion et l'analyse des big data consistent à se concentrer sur les besoins d'information de l'entreprise plutôt que sur les technologies disponibles et à utiliser la visualisation des données pour faciliter la découverte et l'analyse des données.
Pratiques et réglementations en matière de collecte de données (big data)
Alors que la collecte et l'utilisation des big data ont augmenté, il en va de même pour le potentiel d'utilisation abusive des données. Un tollé public concernant les violations de données et autres atteintes à la vie privée a conduit l'Union européenne (UE) à approuver le Règlement général sur la protection des données (RGPD), une loi sur la confidentialité des données qui est entrée en vigueur en mai 2018.
Le GDPR limite les types de données que les organisations peuvent collecter et exige le consentement explicite des individus ou le respect d'autres raisons spécifiées pour la collecte de données personnelles. Il comprend également une disposition relative au droit à l'oubli, qui permet aux résidents de l'UE de demander aux entreprises de supprimer leurs données.
Bien qu'il n'existe pas de loi fédérale similaire aux États-Unis, le California Consumer Privacy Act (CCPA) vise à donner aux résidents californiens plus de contrôle sur la collecte et l'utilisation de leurs informations personnelles par les entreprises qui font des affaires dans l'État. La CCPA a été promulguée en 2018 et est entrée en vigueur le 1er janvier 2020. Ce projet de loi était le premier du genre aux États-Unis. D'ici 2023, 12 autres États auront adopté des lois similaires sur la protection des données.
D'autres efforts en cours pour empêcher les technologies, telles que l'IA et l'apprentissage automatique, d'utiliser les big data à mauvais escient comprennent la loi sur l'IA de l'UE, que le Parlement européen a adoptée en mars 2024. Il s'agit d'un cadre réglementaire complet pour l'utilisation de l'IA, qui fournit aux développeurs d'IA et aux entreprises qui déploient la technologie de l'IA des conseils basés sur le niveau de risque que pose un modèle d'IA.
Pour s'assurer qu'elles respectent les lois qui régissent le big data, les entreprises doivent gérer avec soin le processus de collecte de ces données. Des contrôles doivent être mis en place pour identifier les données réglementées et empêcher les employés non autorisés et d'autres personnes d'y accéder.
L'aspect humain de la gestion et de l'analyse des données massives (big data)
En fin de compte, la valeur commerciale et les avantages des initiatives de big data dépendent des travailleurs chargés de gérer et d'analyser les données. Certains outils de big data permettent à des utilisateurs moins techniques d'exécuter des applications d'analyse prédictive ou aident les entreprises à déployer une infrastructure adaptée aux projets de big data, tout en minimisant le besoin de matériel et de savoir-faire en matière de logiciels distribués.
On peut opposer les big data aux small data, un terme parfois utilisé pour décrire des ensembles de données qui peuvent être facilement utilisés pour la BI et l'analyse en libre-service. Un axiome couramment cité est le suivant : "Les grandes données sont pour les machines ; les petites données sont pour les gens".
L'avenir du big data
Un certain nombre de technologies émergentes sont susceptibles d'influer sur la manière dont les big data sont collectées et utilisées. Les tendances technologiques suivantes sont celles qui auront le plus d'influence sur l'avenir du big data :
- Analyse de l'IA et de l'apprentissage automatique. Les grands ensembles de données sont de plus en plus volumineux et, par conséquent, de moins en moins efficacement analysés par l'œil humain. L'IA et les algorithmes d'apprentissage automatique deviennent essentiels pour effectuer des analyses à grande échelle et même des tâches préliminaires, telles que le nettoyage et le prétraitement des ensembles de données. Les outils d'apprentissage automatique seront probablement utiles dans ce domaine.
- Un stockage amélioré avec une capacité accrue. Les capacités de stockage cloud ne cessent de s'améliorer. Les datalakes et les entrepôts, qui peuvent être sur site ou dans le cloud, sont des options intéressantes pour le stockage des données volumineuses.
- L'accent mis sur la gouvernance. La gouvernance et la réglementation des données deviendront plus complètes et plus courantes à mesure que la quantité de données utilisées augmentera, ce qui nécessitera davantage d'efforts pour les sauvegarder et les réglementer.
- L'informatique quantique. Bien que moins connue que l'IA, l'informatique quantique peut également accélérer les analyses de big data grâce à une puissance de traitement accrue. Elle n'en est qu'à ses débuts et n'est accessible qu'aux grandes entreprises ayant accès à de vastes ressources.
Si le big data devient un enjeu pour votre organisation, vous voudrez connaître ces outils et technologies open source pour le big data.





