Gestion des données ? Pourquoi est-elle fondamentale ?
La gestion des données (ou data management) consiste à collecter, ingérer, stocker, organiser et garder à jour les données d’une entreprise. Elle est essentielle. Réalisée efficacement, elle améliore le cœur des applications métiers et apporte les éléments analytiques qui permettent de prendre des décisions opérationnelles éclairées en s’appuyant sur des informations pertinentes. Elle aide également les dirigeants, les responsables métiers et l’ensemble des utilisateurs dans leurs planifications stratégiques.
Les différentes composantes de la gestion de données, mises bout à bout, garantissent que les données d’une entreprise sont correctes, disponibles et faciles d’accès. Ce travail est principalement réalisé par l’IT et par des équipes dédiées, mais les utilisateurs métiers peuvent également contribuer à certaines parties du processus : les données répondent ainsi mieux à leurs besoins et ils se familiarisent avec les règles internes de leur utilisation.
Cet article approfondit ce qu’est la gestion des données et fournit des informations sur ses différentes sous-catégories. Il détaille également les bonnes pratiques et liste les principaux défis qu’elle pose. Il revient aussi sur les avantages opérationnels d’une bonne stratégie de gestion de données. Enfin, il offre une vue d’ensemble des outils et des techniques disponibles ainsi qu’un brief historique de la discipline.
La gestion de données, un concept fondamental
Les données sont de plus en plus considérées comme un actif de l’entreprise pour prendre de meilleures décisions, améliorer les campagnes marketing, optimiser les opérations, réduire les coûts, et toutes autres actions qui aident à augmenter le chiffre d’affaires et les bénéfices.
Une mauvaise gestion des données peut à l’inverse créer des silos, rendre des jeux de données incohérents et provoquer des problèmes de qualité des données qui réduisent la capacité de l’entreprise à recourir à l’informatique décisionnelle (BI) et aux applications analytiques. Pire, elle peut mener à des analyses erronées et donc à des décisions viciées.
La gestion de données voit son rôle grandir encore plus à l’heure où les entreprises doivent répondre à des exigences de conformité réglementaires toujours plus nombreuses, comme le Règlement sur la protection de données privées (RGPD) ou le California Consumer Privacy Act.
On constate également que les entreprises amassent des volumes toujours plus importants de données de types toujours plus variés – ce que l’on appelle le Big Data – avec à la clé des systèmes de gestion spécifiques à ce Big Data. Sans une bonne gestion des données, ces environnements à forte volumétrie deviennent rapidement des usines à gaz, peu pratiques, voire contre-productives, où les données se perdent.
Les étapes de la gestion de données
Une gestion globale des données est une suite d’étapes et de technologies, intriquées les unes aux autres, qui vont du traitement de la donnée et au stockage jusqu’à la gouvernance (suivi des formats des données et de leurs utilisations dans tel ou tel système opérationnel et/ou analytique).
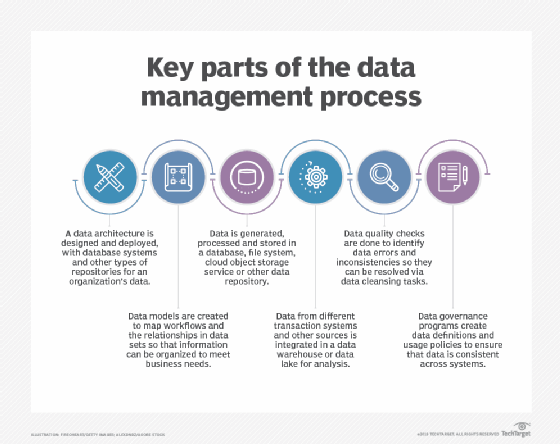
La première étape de la gestion des données, en particulier pour les grandes entreprises qui ont de gros volumes de données, est la mise en œuvre d’une architecture. L’architecture – spécialité du Data Architect – est le schéma directeur qui liste toutes les bases et toutes les plateformes techniques de données déployées, jusqu’aux technologies qui motorisent les applications les plus spécifiques.
Les bases de données sont le type de plateforme le plus couramment utilisé pour enregistrer les informations d’une entreprise, sous une forme organisée, de manière à pouvoir les consulter, les manipuler et les mettre à jour. On utilise ces bases aussi bien dans les systèmes transactionnels – qui génèrent des données opérationnelles (dossiers clients, commandes, ventes, etc.) – que dans les systèmes analytiques (BI, etc.) avec des entrepôts de données qui stockent des données utilisées par les systèmes des métiers (ERP, CRM, inventaires et stocks, etc.), mais dans une optique décisionnelle et analytique.
L’administration des bases de données (DBA) est un aspect crucial de la gestion de données. Une fois les bases déployées, elles doivent être paramétrées (le tuning) et supervisées (le monitoring), leurs performances doivent être suivies et améliorées en continu. L’objectif est de garantir des temps de réponse acceptables aux utilisateurs qui lancent des requêtes pour interroger les informations qui y sont stockées. Parmi les autres tâches des administrateurs, on trouve : la conception des bases (design), la configuration, la gestion des accès, l’installation et les montées de versions, l’application des patchs et des correctifs de sécurité, la sauvegarde (backup) et la récupération (data recovery).
Le principal type d’outils pour administrer une base est un SGBD pour Système de Gestion de Base de Données ou en anglais DBMS pour Database Management System. Ce logiciel fait l’interface entre d’un côté la base elle-même et de l’autre les administrateurs et les utilisateurs qui veulent la contrôler. Il existe des alternatives aux bases de données comme les systèmes de fichiers et les services de stockage objet en mode cloud. Ces alternatives stockent les données d’une manière moins structurée que les bases classiques, ce qui offre plus de souplesse dans le type et le format des données qu’ils gèrent. La contrepartie est que ces systèmes ne sont pas adaptés aux applications transactionnelles. À noter que certains SGBD relationnels managés ou hébergés dans le cloud utilisent les mêmes services de stockage objet.
D’autres aspects de la gestion de données sont incontournables : la modélisation de données (data modeling) – dont les diagrammes établissent les relations entre les éléments de données et les flux de données dans le système ; l’intégration de données – qui regroupe et mélange des données (analytique et opérationnel) provenant de différentes sources ; la gouvernance de données – qui établit les règles et les procédures pour garantir la cohérence des données à tous les niveaux de l’entreprise ; la gestion de la qualité des données (data quality), par laquelle les incohérences et les erreurs dans les données sont corrigées. On peut également citer la gestion des référentiels de données (MDM pour Master Data Management), qui définit un socle de données de référence pour des domaines comme les clients ou les produits.
Techniques et outils de gestion des données
Revenons plus en détail sur cette palette d’outils et de technologies de dépôts de données à l’œuvre dans un processus de gestion de données.
Les systèmes de gestion de données (SGBD)
Les systèmes de base de données les plus courants sont les bases de données relationnelles. Ce type de bases organise les données par tableaux, eux-mêmes composées de lignes et de colonnes. Elles contiennent des enregistrements qui, quand ils existent dans différentes tables, sont connectés par des clés – primaires ou étrangères – qui créent des « relations » entre tables (d’où le nom de ces bases), ce qui évite les doublons. Les bases relationnelles s’appuient sur le langage SQL et sur un modèle de données rigide. Si l’on ajoute qu’elles sont adaptées aux propriétés ACID (atomicité, cohérence, isolation et durabilité), on comprend qu’elles soient le choix de prédilection pour les applications transactionnelles.
D’autres types de SGBD sont valables pour différents types de traitement de données. Le plus connu est le NoSQL (pour Not Only SQL). Leurs modèles de données et leurs schémas de bases de données n’imposent pas d’exigences strictes, ce qui leur permet de stocker des données semi-structurées voire non structurées, comme les données de capteurs, des clics sur internet ou des logs d’applications ou de serveurs.
On dénombre quatre principaux types de NoSQL : les bases orientées documents qui stockent les éléments dans des structures qui ressemblent à des documents ; des bases clé-valeur qui associent des clés uniques à des valeurs associées, les « wide column stores » qui ont des tables avec un grand nombre de colonnes (adaptée aux systèmes distribués), et les bases orientées graph qui relient les éléments ayant des points communs de manière graphique.
Le nom NoSQL est trompeur : certaines de ces bases ne reposent pas sur SQL, mais elles sont désormais nombreuses à en supporter les éléments et certaines présentent un certain niveau de conformité ACID.
Il existe d’autres bases comme les bases In-Memory qui stockent les données dans la mémoire vive d’un serveur plutôt que sur un disque dur pour en accélérer les performances (I/O ou E/S), ou encore les bases de données orientées colonnes adaptées aux applications analytiques. Les bases de données hiérarchiques qui fonctionnaient sur les mainframes sont les ancêtres des bases relationnels et NoSQL et sont encore déployées dans certains systèmes.
On peut également déployer des bases de données sur site ou dans le cloud. Différents éditeurs proposent également des services managés de gestion de bases de données dans le cloud. Ils prennent alors en charge le déploiement, la configuration et l’administration.
Environnements Big Data
Les bases NoSQL sont souvent utilisées dans les déploiements Big Data car elles peuvent stocker et gérer différents types de données. Les environnements analytiques Big Data reposent aussi souvent sur des technologies open source comme Hadoop, une infrastructure de traitement distribuée avec un système de fichiers réparti sur des clusters de serveurs standard. Elle fonctionne avec la base de données HBase, le framework de traitement distribué Spark et les plateformes de streamings et de traitement flux Kafka, Flink et Storm. Les systèmes Big Data sont de plus en plus fréquemment déployés dans le cloud, en s’appuyant sur du stockage objets comme Amazon S3.
Entrepôts de données et lacs de données
Deux autres types de dépôts de données existent pour l’analytique : les entrepôts de données (Data warehouse) et les lacs de données (Data Lake).
Les entrepôts de données sont les plus traditionnels. Ils reposent sur des bases relationnelles ou en colonnes. Ils stockent les données sous forme structurée, données provenant de différents systèmes rassemblées et préparées pour l’analyse. Les principaux cas d’usages des Data Warehouses sont les requêtes BI et le reporting, qui permettent aux dirigeants et aux analystes métiers d’avoir les chiffres sur les ventes, la gestion des stocks ou sur d’autres indicateurs de performance clés (KPI).
L’entrepôt de données d’une entreprise rassemble les données de tous ses systèmes opérationnels. Dans les grands groupes, les filiales ou entités qui ont une certaine autonomie créent parfois leurs propres data warehouse. Les datamarts sont une autre option pour l’analytique. Ce sont de petits entrepôts de données qui contiennent des sous-ensembles de données correspondant aux besoins spécifiques d’un service ou d’un groupe d’utilisateurs.
La conception des lacs de données leur permet de stocker du Big Data, de manière non structurée, pour des applications analytiques avancées comme les modèles prédictifs ou le Machine Learning. Ils sont généralement construits sur un cluster Hadoop, mais peuvent également reposer sur des bases NoSQL ou du stockage objet en monde cloud. Un Data Lake dans un environnement peut même combiner différentes plateformes. Les données d’un Data Lake peuvent être traitées au moment de leur ingestion, mais un lac de données contient le plus souvent des données brutes, auquel cas les analystes – comme les Data Scientists – effectueront leur propre préparation des données (data prep) pour pouvoir faire leur travail.
L’intégration de données
La technique d’intégration de données la plus connue est l’ETL pour extrait, transforme et charge (extract-transform-load). Un ETL extrait des données de systèmes sources, les convertit dans un format déterminé (pour uniformiser les données) avant de les charger dans un système cible (entrepôt de données ou autres). Mais d’autres méthodes d’intégration existent comme l’ELT – pour extrait, charge et transforme (extract-load-transform), une variation d’ETL qui laisse les données dans leur format d’origine quand elle les charge dans la plateforme cible. L’ELT est un choix classique pour les jobs d’intégration dans les Data Lakes et les systèmes Big Data.
ETL et ELT sont des processus batch qui s’exécutent à intervalles planifiés. Mais les équipes en charge de la gestion de données peuvent vouloir faire du temps réel avec des méthodes d’intégration continue de flux de données.
La virtualisation des données est un autre type d’intégration. Il s’agit d’utiliser une couche d’abstraction qui crée, pour l’utilisateur, une vue virtuelle des données hébergées dans différents systèmes (plutôt que de les charger réellement physiquement).
Gouvernance, qualité des données et MDM
Même si des logiciels dédiés existent, la gouvernance des données est essentiellement un processus organisationnel. Et même si elle concerne les professionnels de la donnée, cette gouvernance se fait typiquement au travers d’un comité qui rassemble des responsables (métiers, techniques, etc.) pour décider d’un commun accord comment définir les données, et pour choisir les standards pour leur création, leur formatage et leur utilisation.
Une autre clé de la gouvernance de données est le Data Stewardship. Le Data Steward et le coordinateur – ou l’ordonnateur – de la gouvernance. Son rôle consiste à superviser ses jeux de données et à s’assurer que les règles établies pour les utiliser sont respectées. La fonction de data steward peut, selon les cas et la taille de l’entreprise, être un poste à temps plein ou une mission à temps partiel. La personne qui assure ce rôle peut aussi bien venir de l’opérationnel, que des métiers ou de l’IT. Dans tous les cas, l’un des prérequis est une connaissance pointue des données à superviser.
La gouvernance est étroitement liée aux bons projets d’amélioration de la qualité des données. Des indicateurs pour démontrer cette amélioration sont essentiels pour apporter la preuve de la valeur d’un tel programme.
Il existe différentes techniques pour améliorer la qualité des données. Le profilage (Data Profiling) scanne les jeux de données pour identifier les valeurs aberrantes qui pourraient être des erreurs. Le nettoyage de données (data cleansing ou data scrubbing) répare les erreurs en modifiant ou en supprimant les données erronées, ou encore la validation des données (data validation) qui vérifie les données en leur appliquant des règles de qualité prédéfinies.
Le Master Data Management (MDM) est également rattaché à la gouvernance et à la qualité des données. Du fait de la complexité des programmes MDM, son application est souvent réservée aux grandes entreprises. La MDM crée un registre centralisé de données de référence pour des domaines définis : le « Golden Record ». Ces données de référence alimentent les systèmes analytiques et assurent ainsi la cohérence entre les différentes analyses et rapports. Le référentiel peut également au besoin renvoyer ces « données maîtres », mises à jour, vers les systèmes sources.
La modélisation de données
La modélisation de données consiste à faire un schéma des données de l’entreprise pour mieux les comprendre et mieux les manipuler. Il s’agit d’une représentation conceptuelle, et non technique, des éléments clés de chaque donnée ainsi que des logiques métiers et des relations qui existent entre elles, toujours au niveau logique.
La modélisation de données s’appuie sur la notion d’entités (par exemple des données sur les produits, les rayons/catégories, les fournisseurs, les clients, etc.), d’attributs qui sont liés à ces entités (nom, description, adresse, etc.) et trace des relations entre les entités. Les modèles de données doivent souvent évoluer quand on ajoute de nouvelles sources ou que les informations de l’entreprise évoluent.
Bonnes pratiques de la gestion de données
Les programmes de gouvernance sont utiles pour une stratégie de gestion de données efficace, surtout quand les entreprises ont des environnements distribués et différents systèmes. Il est alors essentiel de mettre l’accent sur la qualité des données. Mais, les équipes IT et celles en charge de la gestion des données ne peuvent agir seules. Les responsables métiers et les utilisateurs doivent aux aussi être impliqués afin de s’assurer qu’ils ont bien les données dont ils ont besoin et que les problèmes de qualité identifiés ne se reproduisent pas (à cause d’une mauvaise saisie ou d’une mauvaise manipulation régulière par exemple). Il en va de même pour les projets de modélisation de données.
Les plateformes de données disponibles, dont les bases de données, sont légion. Concevoir une architecture, évaluer et sélectionner les technologies ad hoc est un art délicat. Les responsables IT qui s’occupent de l’infrastructure et les spécialistes des données (comme les architectes et les DBA) doivent s’assurer que les systèmes mis en place répondent bien aux besoins et qu’ils pourront fournir les capacités de traitement et les informations nécessaires au fonctionnement des entités de l’entreprise.
Pour les aider, la Data Governance Professionals Organization travaille en collaboration avec DAMA International et d’autres organisations sectorielles pour établir des règles de bonne gestion des données et proposer conseils et bonnes pratiques. De ce travail est né le « DAMA-DMBOK : Data Management Body of Knowledge » un ouvrage de référence qui définit une approche standard des fonctions et des méthodes applicables. Ce DMBOK2, comme on l’appelle communément, date de 2009. Une seconde version est parue en 2017.
Risques et défis de la gestion de données
Lister les données
L’entreprise qui n’a pas bien pensé son architecture de données en amont risque de se retrouver avec des systèmes en silo qui pourront difficilement être intégrés les uns aux autres et qui ne pourront pas être gérés de manière coordonnée. Même dans un environnement mieux conçu, permettre aux data scientists et aux analystes de trouver les données qu’ils souhaitent et d’y accéder relève parfois de la gageure, surtout quand elles sont éparpillées sur plusieurs bases et systèmes Big Data.
C’est la raison pour laquelle existe ce que l’on appelle des « catalogues de données » (Data Catalog). Ces catalogues visent à lister tout le patrimoine informationnel disponible dans les systèmes existants d’une entreprise. On y trouve généralement des glossaires métiers (pour une même information, deux métiers peuvent en effet avoir deux termes différents comme « zone » et « région » et ne pas appeler la donnée de la même façon), des dictionnaires de métadonnées sur les jeux de données et un suivi des modifications des données, techniques ou de manipulation par les métiers comme un nettoyage ou un croisement entre deux jeux pour en générer un troisième (le Data Lineage).
Atouts et défauts du cloud
L’évolution vers le cloud simplifie la gestion de données à certains égards, mais elle génère également de nouveaux défis. La migration en elle-même vers des bases (DBaaS pour Database as a Service) et des plateformes Big Data hébergées peut être épineuse (format, conversion). Leur exploitation introduit de nouvelles logiques (latence entre une application et la base, etc.). Se pose également la question du coût : il conviendra de surveiller les systèmes cloud et les services gérés avec attention pour s’assurer que le coût du traitement des données n’excède pas le budget prévu.
Sécurité et conformité
Ce sont de plus en plus souvent les équipes dédiées à la gestion de données qui sont en charge d’assurer la sécurité de ces données et de limiter les risques juridiques potentiels en cas de fuite ou d’utilisation inappropriée des données. Les responsables doivent contribuer à assurer la conformité réglementaire. Cette obligation s’est renforcée avec la mise en place des exigences du RGPD par l’Union européenne en mai 2018 et le California Consumer Privacy Act, en vigueur depuis 2020.
Poste, métiers et compétences de la gestion de données
La gestion de données implique d’effectuer un ensemble de tâches. Ce qui requiert des compétences et des fonctions spécifiques. Dans les petites entreprises, une seule personne sera responsable de plusieurs tâches, mais en général, dans les grandes entreprises on trouvera des personnes différentes pour des fonctions différentes : des architectes, des spécialistes de la modélisation (data modeler), des administrateurs de bases de données (DBA), des développeurs de bases de données, des ingénieurs et des analystes en charge de la qualité des données, des développeurs spécialistes de l’intégration, des responsables de la gouvernance, des data stewards et des ingénieurs de données qui, tous, collaboreront avec les équipes d’analystes pour élaborer les bons pipelines et préparer en amont les données.
Les data scientists et autres analystes spécialisés réalisent parfois eux-mêmes certaines tâches de gestion des données, en particulier dans les systèmes de Big Data où il faut manipuler des données brutes qu’il faut préparer avant de les utiliser. Les développeurs d’applications peuvent également aider à déployer et à gérer les environnements de Big Data car ces tâches font appel à des compétences nouvelles par rapport aux bases relationnelles. L’entreprise est donc parfois obligée de recruter de nouveaux talents ou de former ses DBA aux spécificités du Big Data.
Avantages d’une gestion de données bien pensée
La stratégie de gestion de données, quand elle est bien pensée, peut donner un avantage compétitif, à la fois en améliorant l’efficacité opérationnelle et en permettant une prise de décision plus éclairée. Les entreprises peuvent également gagner en agilité, en repérant mieux les tendances du marché et en tirant parti plus rapidement d’opportunités émergentes.
Une gestion efficace peut également aider à éviter les fuites de données et les problèmes liés au respect de la vie privée et aux contraintes légales, des mésaventures qui peuvent ternir une réputation, coûter très cher et aboutir sur des procédures judiciaires.
Mais le plus grand avantage d’une bonne gestion des données reste l’amélioration des performances de l’entreprise.
Historique et évolution de la gestion de données
La gestion des données tient son origine du constat, fait par les informaticiens qui travaillaient sur les tout premiers ordinateurs. Ceux-ci se sont rapidement rendu compte que les machines calculaient bien, mais qu’elles arrivaient à des conclusions fausses à cause de la piètre qualité des données qu’on leur donnait. Le problème est encore d’actualité et est connu sous le nom de « garbage in, garbage out » (en français « déchet à l’entrée, déchet à l’arrivée »).
Au début des années 60, de nombreux groupes sectoriels et des associations professionnelles ont commencé à promouvoir des bonnes pratiques en matière de gestion de données, en particulier des recommandations sur la formation et sur les indicateurs clés de qualité. C’est à la même époque que les bases de données hiérarchiques sur mainframe sont apparues.
Les bases de données relationnelles ont émergé dans les années 70, pour devenir incontournables dans les années 80. Le concept d’entrepôt de données est, lui, apparu à la fin des années 80, mais ses premiers déploiements réels ont commencé au milieu des années 90. Au début des années 2000, les bases relationnelles restaient la technologie dominante, avec une mainmise quasiment totale sur les bases de données.
La première version de Hadoop est sortie en 2006, suivie par plusieurs autres technologies Big Data, dont Spark. Toute une gamme de bases NoSQL est également apparue à la même période. Aujourd’hui, si les technologies relationnelles détiennent encore la plus grosse part du marché, l’émergence du Big Data, des alternatives NoSQL et de nouveaux environnements de type data lake sans oublier les bases multimodèle offrent une palette d’outils de gestion de données bien plus large.
Pour approfondir sur Base de données
-
![]()
Big Data : bienvenue dans l’ère des plateformes pour industrialiser la data science
Par: Cyrille Chausson
-
![]()
Big Data
Par: Philippe Ducellier
-
![]()
IoT et Big Data : et si on réfléchissait un peu avant de se lancer ?
-
![]()
Analytique et Big Data : deux priorités d’investissement en 2016 pour les entreprises françaises
Par: Cyrille Chausson



