Qu'est-ce que l'apprentissage par renforcement à partir du feedback humain (RLHF) ?
L'apprentissage par renforcement à partir du feedback humain (RLHF) est une approche d'apprentissage automatique qui combine des techniques d'apprentissage par renforcement, telles que les récompenses et les comparaisons, avec des conseils humains pour former un agent d'intelligence artificielle (IA).
L'apprentissage automatique est une composante essentielle de l'IA. L'apprentissage automatique forme l'agent d'IA à une fonction particulière, en exécutant des milliards de calculs et en amenant l'agent à en tirer des enseignements. L'automatisation accélère le processus de formation et le rend plus rapide que la formation humaine.
Cependant, il arrive que le retour d'information humain soit vital pour affiner l'IA interactive ou générative. L'utilisation du retour d'information humain pour le texte généré permet d'optimiser le modèle et de le rendre plus efficace, plus logique et plus utile.
Dans le cadre de la RLHF, les testeurs et les utilisateurs humains fournissent un retour d'information direct afin d'optimiser le modèle linguistique de manière plus précise que l'auto-apprentissage seul. La RLHF est principalement utilisée dans le traitement du langage naturel (NLP) pour la compréhension des agents d'intelligence artificielle dans des applications telles que les agents conversationnels et les chatbots, la synthèse vocale et les résumés.
Pourquoi la RLHF est-elle importante ?
Dans l'apprentissage par renforcement classique, les agents d'intelligence artificielle apprennent de leurs actions par le biais d'une fonction de récompense qui attribue des notes numériques aux résultats du modèle en fonction de leur adéquation avec les préférences humaines. Mais l'agent apprend essentiellement par lui-même, et les récompenses ne sont souvent pas faciles à définir ou à mesurer, en particulier pour les tâches complexes, telles que le NLP. Le résultat est un chatbot facilement confus qui n'a aucun sens pour l'utilisateur.
L'objectif de la RLHF est de former des modèles de langage pour générer des textes à la fois attrayants et exacts sur le plan factuel. Pour ce faire, il crée d'abord un modèle de récompense capable de prédire comment les humains évalueront la qualité du texte généré en sortie. Le modèle de récompense est utilisé pour former un modèle ML capable de prédire les évaluations humaines du texte.
Ensuite, le système RLHF affine le modèle de récompense en récompensant le modèle linguistique qui génère un texte que le modèle de récompense évalue bien. Inversement, le modèle de récompense peut encourager le modèle linguistique à rejeter certaines questions ou entrées. Par exemple, les modèles de langage refusent souvent de générer des contenus qui font l'apologie de la violence ou qui sont racistes, sexistes ou homophobes.
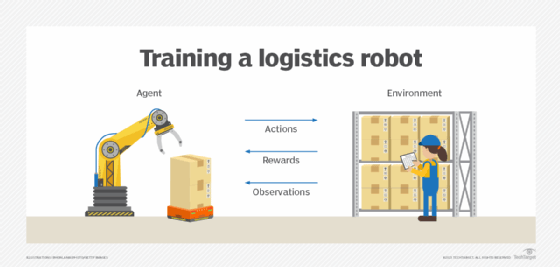
Comment fonctionne la RLHF ?
Le RLHF est un processus itératif dans lequel le retour d'information humain est recueilli en permanence et utilisé pour l'amélioration continue du grand modèle linguistique (LLM). La formation RLHF se déroule en trois phases :
- Phase initiale. La première phase implique la sélection d'un modèle existant en tant que LLM principal pour déterminer et étiqueter le comportement correct. Un modèle pré-entraîné nécessite moins de données d'entraînement, ce qui permet d'accélérer l'entraînement.
- Retour d'information humain. Après avoir formé le modèle initial, les testeurs humains utilisent diverses mesures pour évaluer ses performances. Par exemple, les formateurs humains attribuent une note de qualité ou de précision aux différents résultats générés par le modèle. Le système d'IA évalue ensuite ses performances sur la base du retour d'information humain afin de créer des récompenses pour l'apprentissage par renforcement.
- Apprentissage par renforcement. Le modèle de récompense est affiné à l'aide des résultats du LLM principal, et le LLM reçoit un score de qualité de la part des testeurs. Le LLM utilise ce retour d'information pour améliorer ses performances dans les tâches futures.

Quelles sont les utilisations spécifiques de la RLHF ?
Un exemple de modèle utilisant la RLHF est le GPT-4 d'OpenAI, qui alimente ChatGPT, un outil d'IA générative qui crée de nouveaux contenus, tels que des chats et des conversations, sur la base de messages-guides. Une bonne application d'IA générative doit pouvoir se lire et s'entendre comme une conversation humaine naturelle. Cela signifie que le NLP est nécessaire pour que l'agent d'IA comprenne comment le langage humain est parlé et écrit.
Les LLM GPT-3 et GPT-4 qui sous-tendent ChatGPT sont entraînés à l'aide de RLHF pour générer des réponses conversationnelles et réalistes pour la personne qui fait la requête. Ils sont entraînés sur une quantité massive de données afin de prédire le mot suivant pour former une phrase. ChatGPT apprend les attentes des humains et crée des réponses semblables à celles des humains.
La formation d'un LLM de cette manière va au-delà de la prédiction du mot suivant par l'outil ; elle aide à construire une phrase cohérente dans son ensemble. ChatGPT se distingue ainsi des simples chatbots, qui fournissent généralement des réponses pré-écrites et standardisées aux questions. Grâce à sa formation basée sur l'humain, ChatGPT est capable de comprendre l'intention de la question et de fournir des réponses à consonance naturelle qui aident à la prise de décision.
Google Gemini utilise également la formation RLHF pour affiner les résultats de Gemini. Sa formation RLHF est menée parallèlement à une mise au point supervisée. Il s'agit d'une technique différente qui montre au LLM des exemples de résultats et de réponses de haute qualité afin qu'il s'adapte en conséquence.
Quels sont les avantages de la RLHF ?
La méthode RLHF est souvent utilisée comme alternative à l'apprentissage par renforcement en raison des avantages qu'offre le retour d'information humain. Ces avantages sont notamment les suivants :
- Valeurs humaines. Les modèles d'IA deviennent conscients de ce qu'est un comportement humain acceptable et éthique lorsque les humains sont dans la boucle, car les humains corrigent les résultats inacceptables.
- Sécurité. La RLHF empêche les modèles d'IA de produire des résultats dangereux. Ceci est particulièrement important pour les systèmes utilisés dans les véhicules autonomes et les applications de santé qui pourraient affecter la sécurité humaine.
- Expérience de l'utilisateur. Les commentaires humains aident un modèle d'IA à comprendre les préférences humaines mieux que les seules données sur les préférences. Le fait de donner un retour d'information cohérent en fonction de l'évolution des préférences permet au modèle de recommander des produits pertinents en fonction des préférences et des tendances actuelles.
- Tâches d'étiquetage des données. Les entreprises qui utilisent la RLHF gagnent du temps et de l'argent car les annotateurs humains ne sont pas nécessaires pour étiqueter de grands ensembles de données de formation lorsque le retour d'information humain peut clarifier le contenu des données de formation.
- Connaissance des modèles. Non seulement les lacunes des données de formation sont comblées avec l'aide de personnes, mais les modèles d'IA sont également exposés à de nouvelles connaissances du monde réel, telles que les processus d'entreprise et les flux de travail, dans le cadre des efforts de recherche sur l'IA.
Quels sont les défis et les limites de la RLHF ?
La RLHF présente également des défis et des limites, notamment les suivants :
- Subjectivité et erreur humaine. La qualité du retour d'information peut varier selon les utilisateurs et les testeurs. Lorsqu'il s'agit de générer des réponses à des questions complexes, il est préférable que ce soit des personnes ayant une formation appropriée dans des domaines complexes, tels que la science ou la médecine, qui fournissent un retour d'information. Cependant, trouver des experts peut s'avérer coûteux et prendre du temps.
- Formulation des questions. La qualité des réponses d'un outil d'IA dépend des questions. Si une question est trop ouverte ou si l'utilisateur n'est pas clair dans ses instructions, le LLM risque de ne pas comprendre entièrement la demande. En formation, une formulation correcte est nécessaire pour qu'un agent d'IA puisse déchiffrer l'intention de l'utilisateur et comprendre le contexte.
- Biais d'apprentissage. La RLHF est sujette à des problèmes de biais d'apprentissage automatique. Poser une question factuelle, telle que "Que vaut 2+2 ?", donne une seule réponse. Cependant, les questions plus complexes, comme celles qui sont de nature politique ou philosophique, peuvent avoir plusieurs réponses. L'IA choisit par défaut la réponse qu'elle a apprise, ce qui entraîne un biais et une portée étroite qui exclut d'autres réponses ou informations.
- Évolutivité. Étant donné que ce processus utilise le retour d'information humain, il est fastidieux et gourmand en ressources de le mettre à l'échelle pour former des modèles plus grands et plus sophistiqués. L'automatisation du processus de retour d'information pourrait contribuer à résoudre ce problème.
Mise en œuvre de l'apprentissage implicite de la langue (Q-learning)
Les LLM peuvent être incohérents dans leur précision pour certaines tâches spécifiées par l'utilisateur. Une méthode d'apprentissage par renforcement appelée apprentissage implicite du langage Q (ILQL) permet de remédier à ce problème.
Les algorithmes traditionnels d'apprentissage Q utilisent le langage pour aider le modèle à comprendre la tâche. L'ILQL est un type d'algorithme d'apprentissage par renforcement utilisé pour apprendre à un modèle à effectuer une tâche spécifique, par exemple pour apprendre à un chatbot du service clientèle à interagir avec un client.
ILQL est un algorithme qui permet d'apprendre aux modèles à effectuer des tâches complexes avec l'aide d'un retour d'information humain. En utilisant l'apport humain dans le processus d'apprentissage, les modèles peuvent être formés plus efficacement que par le seul auto-apprentissage.
Dans l'ILQL, le modèle reçoit une récompense basée sur le résultat et le retour d'information de l'homme. Le modèle utilise ensuite cette récompense pour mettre à jour ses valeurs Q, qui déterminent la meilleure action à entreprendre à l'avenir. Dans l'apprentissage Q traditionnel, le modèle reçoit une récompense uniquement pour le résultat de l'action.
RLHF vs. apprentissage par renforcement à partir du retour d'information de l'IA
L'apprentissage par renforcement à partir du retour d'information de l'IA (RLAIF) est différent de l'apprentissage par renforcement à partir du retour d'information de l'homme. Le RLHF s'appuie sur le retour d'information humain pour affiner les résultats. Le RLAIF, quant à lui, incorpore le retour d'information d'autres modèles d'IA. Avec RLAIF, un LLM pré-entraîné est utilisé pour former le nouveau modèle, ce qui automatise et simplifie le processus de retour d'information. L'inconvénient de cette pratique est que, sans retour d'information humain, le nouveau modèle pourrait manquer d'empathie, de considérations éthiques et d'autres capacités humaines.
Les cas d'utilisation pour lesquels RLAIF pourrait être la meilleure approche comprennent l'analyse des sentiments dans les médias sociaux et le traitement de grands volumes de données sur la satisfaction des clients, car les modèles d'IA analysent les données volumineuses plus rapidement que les humains. RLHF est mieux adapté aux applications plus petites qui requièrent des nuances que les humains peuvent apporter, comme les applications de soins de santé.
Quelle est la prochaine étape pour la RLHF ?
La technologie RLHF devrait s'améliorer au fur et à mesure que les limitations actuelles seront corrigées. Les améliorations attendues sont les suivantes :
- Amélioration de la collecte du retour d'information. Il existe plusieurs moyens de rendre le processus de collecte du retour d'information plus efficace, comme le crowdsourcing, qui consiste à répartir les tâches de retour d'information entre un grand nombre d'individus.
- Possibilités multimodales. Les modèles d'IA multimodaux examinent différentes formes d'entrées, telles que les images ou le son, en plus du texte. Leur utilisation devrait augmenter. La RLHF peut fournir un retour d'information sur ces différents types de résultats, par exemple en améliorant les détails des images.
- Mécanismes de récompense spécifiques à l'utilisateur. La RLHF continuera à rendre l'IA plus consciente des préférences spécifiques des utilisateurs et conduira à de meilleurs mécanismes de récompense qui adhèrent aux besoins spécifiques des utilisateurs.
- Nouvelles techniques d'apprentissage. On s'attend à ce que de nouvelles techniques de RLHF voient le jour. Par exemple, l'apprentissage par transfert prend en compte le retour d'information humain sur une tâche et l'applique à d'autres tâches similaires.
- Explicabilité. La RLHF contribuera à faire progresser les efforts en matière d'IA explicable, en fournissant des résultats plus transparents et en expliquant les étapes suivies lors de la formation des modèles.
- Nouvelles réglementations. Les réglementations et les cadres de gouvernance de l'IA se multiplient dans le monde entier, d'où l'importance de la conformité. Les réglementations existantes et futures contribueront à garantir que la RLHF est menée de manière responsable et éthique.
Le RLHF est l'une des nombreuses techniques utilisées par les professionnels de la ML. En savoir plus sur les certifications et cours de ML les plus populaires qui couvrent diverses techniques de renforcement et d'apprentissage supervisé.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Que sont les hallucinations de l'IA et pourquoi constituent-elles un problème ?
Par: Ben Lutkevich
-
![]()
Qu'est-ce que l'alignement de l'IA ?
Par: Ben Lutkevich
-
![]()
L'apprentissage par renforcement à partir du feedback humain (RLHF) ?
Par: Andy Patrizio
-
![]()
Qu'est-ce que l'apprentissage par renforcement ?
Par: Joseph Carew



