Qu'est-ce qu'un réseau neuronal récurrent ?

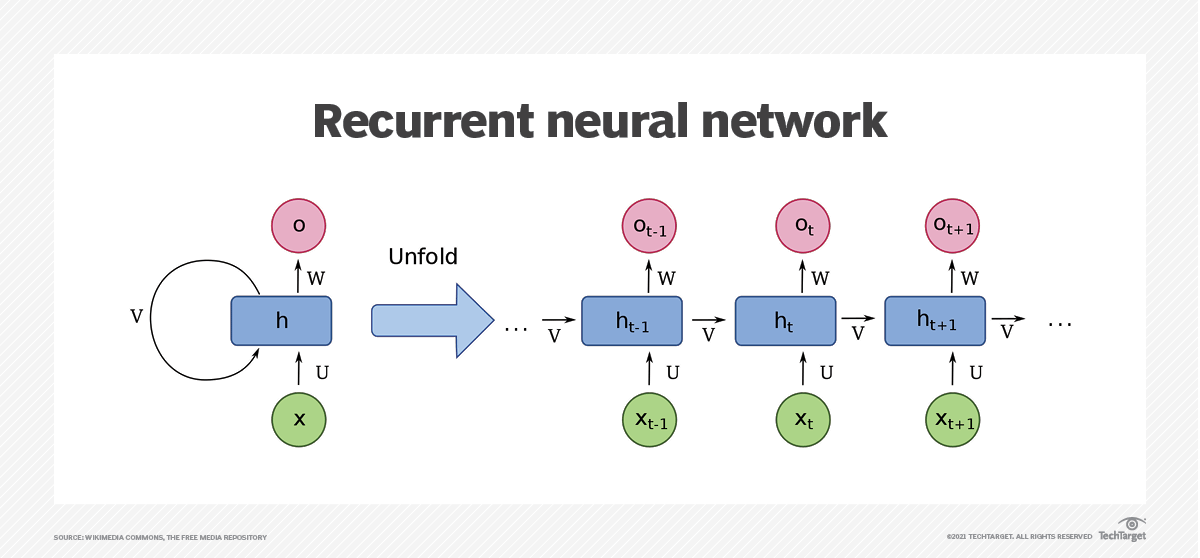
Un réseau neuronal récurrent (RNN) est un type de réseau neuronal artificiel couramment utilisé dans la reconnaissance vocale et le traitement du langage naturel. Les réseaux neuronaux récurrents reconnaissent les caractéristiques séquentielles des données et utilisent des modèles pour prédire le prochain scénario probable.
Les RNN sont utilisés dans l'apprentissage profond et dans le développement de modèles qui simulent l'activité des neurones dans le cerveau humain. Ils sont particulièrement puissants dans les cas d'utilisation où le contexte est essentiel pour prédire un résultat, et se distinguent également des autres types de réseaux neuronaux artificiels parce qu'ils utilisent des boucles de rétroaction pour traiter une séquence de données qui informent la sortie finale. Ces boucles de rétroaction permettent à l'information de persister. Cet effet est souvent décrit comme une mémoire.
Les cas d'utilisation des RNN tendent à être liés à des modèles de langage dans lesquels la connaissance de la prochaine lettre d'un mot ou du prochain mot d'une phrase dépend des données qui la précèdent. Une expérience convaincante montre qu'un RNN entraîné avec les œuvres de Shakespeare produit avec succès une prose semblable à celle de Shakespeare. L'écriture par des RNN est une forme de créativité informatique. Cette simulation de la créativité humaine est rendue possible par la compréhension qu'a l'IA de la grammaire et de la sémantique apprises à partir de son ensemble de formation.
Comment les réseaux neuronaux récurrents apprennent
Les réseaux neuronaux artificiels sont créés avec des composants de traitement de données interconnectés qui sont vaguement conçus pour fonctionner comme le cerveau humain. Ils sont composés de couches de neurones artificiels - les nœuds du réseau - qui ont la capacité de traiter les données d'entrée et de transmettre les données de sortie à d'autres nœuds du réseau. Les nœuds sont reliés par des arêtes ou des poids qui influencent la force d'un signal et la sortie finale du réseau.
Dans certains cas, les réseaux neuronaux artificiels traitent les informations dans une seule direction, de l'entrée à la sortie. Ces réseaux neuronaux "feed-forward" comprennent les réseaux neuronaux convolutifs qui sont à la base des systèmes de reconnaissance d'images. Les RNN, en revanche, peuvent être superposés pour traiter les informations dans deux directions.
Comme les réseaux neuronaux à progression directe, les RNN peuvent traiter des données depuis l'entrée initiale jusqu'à la sortie finale. Contrairement aux réseaux neuronaux à progression directe, les RNN utilisent des boucles de rétroaction, telles que la rétropropagation dans le temps, tout au long du processus de calcul pour réinjecter des informations dans le réseau. Ces boucles relient les entrées et permettent aux RNN de traiter des données séquentielles et temporelles.
Un réseau neuronal à rétropropagation tronquée dans le temps est un RNN dans lequel le nombre de pas de temps dans la séquence d'entrée est limité par une troncature de la séquence d'entrée. Cette méthode est utile pour les réseaux neuronaux récurrents utilisés comme modèles de séquence à séquence, où le nombre d'étapes de la séquence d'entrée (ou le nombre d'étapes temporelles de la séquence d'entrée) est supérieur au nombre d'étapes de la séquence de sortie.
Réseaux neuronaux récurrents bidirectionnels
Les réseaux neuronaux récurrents bidirectionnels (BRNN) sont un autre type de RNN qui apprennent simultanément les directions avant et arrière du flux d'informations. Cela diffère des RNN standard, qui n'apprennent les informations que dans une seule direction. Le processus d'apprentissage simultané des deux directions est connu sous le nom de flux d'informations bidirectionnel.
Dans un réseau neuronal artificiel classique, les projections vers l'avant sont utilisées pour prédire l'avenir et les projections vers l'arrière pour évaluer le passé. Elles ne sont toutefois pas utilisées ensemble, comme dans un BRNN.
Les défis des RNN et la manière de les résoudre
Les problèmes les plus courants avec le RNNS sont la disparition du gradient et les problèmes d'explosion. Les gradients font référence aux erreurs commises lors de la formation du réseau neuronal. Si les gradients commencent à exploser, le réseau neuronal devient instable et incapable d'apprendre à partir des données d'entrainement.
Unités de mémoire à long terme
L'un des inconvénients des RNN standard est le problème du gradient disparaissant, dans lequel les performances du réseau neuronal diminuent parce qu'il ne peut pas être entraîné correctement. Cela se produit avec les réseaux neuronaux à couches profondes, qui sont utilisés pour traiter des données complexes.
Les RNN standard qui utilisent une méthode d'apprentissage basée sur le gradient se dégradent au fur et à mesure qu'ils deviennent plus grands et plus complexes. Le réglage efficace des paramètres dans les premières couches prend trop de temps et devient trop coûteux en termes de calcul.
Les réseaux à mémoire à long terme (LSTM), inventés par les informaticiens Sepp Hochreiter et Jurgen Schmidhuber en 1997, constituent une solution à ce problème. Les RNN construits avec des unités LSTM classent les données dans des cellules de mémoire à court terme et à long terme. Cela permet aux RNN de déterminer quelles données sont importantes et doivent être mémorisées et réintroduites dans le réseau. Cela permet également aux RNN de déterminer quelles données peuvent être oubliées.
Unités récurrentes à accès limité
Les unités récurrentes à portes (GRU) sont une forme d'unité de réseau neuronal récurrent qui peut être utilisée pour modéliser des données séquentielles. Bien que les réseaux LSTM puissent également être utilisés pour modéliser des données séquentielles, ils sont plus faibles que les réseaux feed-forward standard. En utilisant conjointement une LSTM et une GRU, les réseaux peuvent tirer parti des atouts des deux unités : la capacité d'apprendre des associations à long terme pour la LSTM et la capacité d'apprendre à partir de modèles à court terme pour la GRU.
<iframe width="740" height="416" src="https://www.youtube.com/embed/-8se4mWn058" title="What is a Neural Network and How Does it Work?" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
Perceptrons multicouches et réseaux neuronaux convolutifs
Les deux autres types de classes de réseaux neuronaux artificiels comprennent les perceptrons multicouches (MLP) et les réseaux neuronaux convolutifs.
Les MLP se composent de plusieurs neurones disposés en couches et sont souvent utilisés pour la classification et la régression. Un perceptron est un algorithme qui peut apprendre à effectuer une tâche de classification binaire. Un perceptron unique ne peut pas modifier sa propre structure, c'est pourquoi ils sont souvent empilés en couches, où une couche apprend à reconnaître des caractéristiques plus petites et plus spécifiques de l'ensemble de données.
Les neurones des différentes couches sont connectés les uns aux autres. Par exemple, la sortie du premier neurone est connectée à l'entrée du deuxième neurone, qui agit comme un filtre. Les MLP sont utilisés pour superviser l'apprentissage et pour des applications telles que la reconnaissance optique de caractères, la reconnaissance vocale et la traduction automatique.
Les réseaux neuronaux convolutifs, également connus sous le nom de CNN, sont une famille de réseaux neuronaux utilisés dans le domaine de la vision par ordinateur. Le terme "convolutif" fait référence à la convolution - le processus de combinaison du résultat d'une fonction avec le processus de calcul - de l'image d'entrée avec les filtres du réseau. L'idée est d'extraire des propriétés ou des caractéristiques de l'image. Ces propriétés peuvent ensuite être utilisées pour des applications telles que la reconnaissance ou la détection d'objets.

Les CNN sont créés par le biais d'un processus de formation, ce qui constitue la principale différence entre les CNN et les autres types de réseaux neuronaux. Un CNN est composé de plusieurs couches de neurones, et chaque couche de neurones est responsable d'une tâche spécifique. La première couche de neurones peut être chargée d'identifier les caractéristiques générales d'une image, telles que son contenu (par exemple, un chien). La couche suivante de neurones peut identifier des caractéristiques plus spécifiques (par exemple, la race du chien).







