Qu'est-ce que l'apprentissage par renforcement ?
Traduction
L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique qui permet d'entraîner un logiciel à effectuer certaines actions souhaitées. L'apprentissage par renforcement est basé sur la récompense des comportements souhaités et la punition des comportements indésirables.
En général, un agent d'apprentissage par renforcement - l'entité logicielle à former - est capable de percevoir et d'interpréter son environnement, ainsi que de prendre des mesures et d'apprendre par essais et erreurs.
L'apprentissage par renforcement est l'une des nombreuses approches utilisées par les développeurs pour former les systèmes d'apprentissage automatique. Cette approche est importante car elle permet à un agent d'apprendre à naviguer dans les complexités de l'environnement pour lequel il a été créé. Par exemple, on peut apprendre à un agent à contrôler un jeu vidéo ou à un robot dans un environnement industriel à effectuer une tâche spécifique. Au fil du temps, grâce à un système de retour d'information qui comprend généralement des récompenses et des punitions, l'agent apprend de son environnement et optimise ses comportements.
Comment fonctionne l'apprentissage par renforcement ?
Une action correspond aux mesures prises par un agent RL pour naviguer dans son environnement. Par exemple, il peut s'agir de sélectionner un onglet pour naviguer vers une page web. Dans l'apprentissage par renforcement, les développeurs conçoivent une méthode pour récompenser les actions souhaitées et punir les comportements négatifs. Cette méthode utilise un algorithme d'apprentissage par renforcement pour attribuer des valeurs positives aux actions souhaitées afin d'encourager l'agent à les utiliser, tandis que des valeurs négatives sont attribuées aux comportements indésirables afin de les décourager. L'agent est ainsi programmé pour rechercher des récompenses globales maximales et à long terme afin de parvenir à une solution optimale.
Ces objectifs à long terme permettent à l'agent de ne pas rester bloqué sur des objectifs moins importants. Au fil du temps, l'agent apprend à éviter le négatif et à rechercher le positif.
Le processus de décision de Markov sert de base aux systèmes d'apprentissage par renforcement. Dans ce processus, un agent existe dans un état spécifique au sein d'un environnement ; il doit sélectionner la meilleure action possible parmi plusieurs actions potentielles qu'il peut effectuer dans son état actuel. Certaines actions offrent des récompenses pour la motivation. Lorsqu'il se trouve dans l'état suivant, il a accès à de nouvelles actions gratifiantes. Au fil du temps, et grâce à un processus d'essais et d'erreurs, l'agent commence à effectuer les actions optimales pour maximiser sa récompense cumulée, ou la somme des récompenses que l'agent reçoit des actions qu'il choisit d'effectuer.
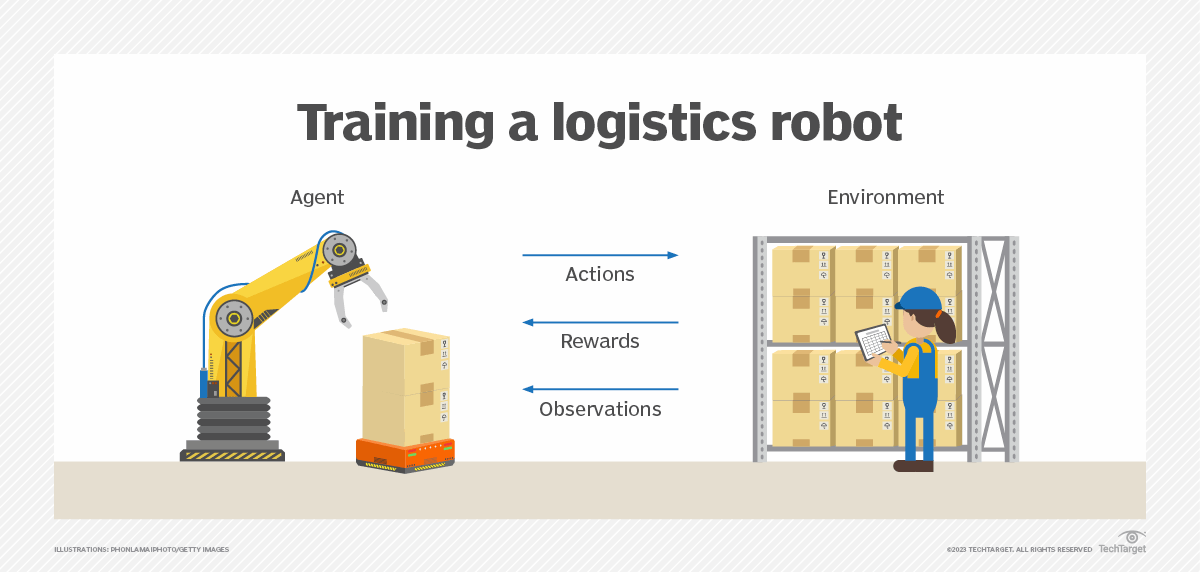
Cette méthode d'apprentissage a été adoptée dans le domaine de l'intelligence artificielle (IA) comme moyen de diriger l'apprentissage automatique non supervisé par le biais de récompenses ou de renforcements positifs et de pénalités ou de renforcements négatifs.
Types d'algorithmes d'apprentissage par renforcement
Il existe plusieurs algorithmes d'apprentissage par renforcement qui sont généralement regroupés dans les deux catégories suivantes :
- Le RL basé sur un modèle permet à un agent de créer un modèle interne de l'environnement. Cela permet à l'agent de prédire la récompense d'une action. L'algorithme de l'agent est également basé sur la maximisation des points de récompense. Le RL basé sur un modèle est idéal pour les environnements statiques où le résultat de chaque action est bien défini.
- La logique sans modèle utilise une approche d'essai et d'erreur dans un environnement. L'agent effectue plusieurs fois différentes actions pour en apprendre les résultats. Au fur et à mesure qu'il effectue ces actions, il crée une stratégie - appelée politique - qui optimise ses points de récompense. La logique sans modèle est idéale pour les environnements inconnus, changeants, vastes ou complexes.
Applications et exemples d'apprentissage par renforcement
Bien que l'apprentissage par renforcement soit un sujet d'intérêt dans le domaine de l'intelligence artificielle, son adoption et son application généralisées dans le monde réel restent limitées. Toutefois, les documents de recherche sur les applications théoriques abondent et certains cas d'utilisation ont été couronnés de succès.
Les utilisations actuelles comprennent, sans s'y limiter, les éléments suivants :
- Jeux.
- Gestion des ressources.
- Recommandations personnalisées.
- Robotique.
- L'apprentissage automatique.
- Usage militaire.
Le jeu est probablement l'utilisation la plus courante de l'apprentissage par renforcement, car il permet d'obtenir des performances surhumaines dans de nombreux jeux. Le jeu Pac-Man en est un exemple.
Un algorithme d'apprentissage jouant à Pac-Man pourrait être capable de se déplacer dans l'une des quatre directions possibles - vers le haut, vers le bas, vers la gauche et vers la droite - à moins qu'il n'y ait un obstacle. À partir des données des pixels, un agent pourrait recevoir une récompense numérique pour le résultat d'une unité de déplacement : 0 pour les espaces vides, 1 pour les pastilles, 2 pour les fruits, 3 pour les pastilles de puissance, 4 pour les pastilles de puissance post-fantôme, 5 pour la collecte de toutes les pastilles afin de terminer un niveau, et une déduction de 5 points en cas de collision avec un fantôme. L'agent commence par un jeu aléatoire et évolue vers un jeu plus sophistiqué, en apprenant l'objectif d'obtenir toutes les pastilles pour terminer le niveau. Avec le temps, l'agent peut même apprendre des tactiques telles que la conservation des pastilles d'énergie jusqu'à ce qu'il en ait besoin pour se défendre.
L'apprentissage par renforcement peut fonctionner dans une situation où une récompense claire peut être appliquée. Dans le cadre de la gestion des ressources de l'entreprise, les algorithmes de renforcement affectent des ressources limitées à différentes tâches, à condition qu'il y ait un objectif global à atteindre. Dans ce cas, l'objectif serait de gagner du temps ou de conserver les ressources.
Dans le domaine de la robotique, l'apprentissage par renforcement a fait l'objet de tests limités. Ce type d'apprentissage automatique peut donner aux robots la capacité d'apprendre des tâches qu'un enseignant humain ne peut pas démontrer, d'adapter une compétence acquise à une nouvelle tâche et de parvenir à l'optimisation même lorsque la formulation analytique n'est pas disponible.
L'apprentissage par renforcement est également utilisé dans la recherche opérationnelle, la théorie de l'information, la théorie des jeux, la théorie du contrôle, l'optimisation basée sur la simulation, les systèmes multi-agents, l'intelligence en essaim, les statistiques, les algorithmes génétiques et les efforts d'automatisation industrielle en cours.
L'armée utilise l'apprentissage par renforcement pour préparer les véhicules terrestres autonomes à des situations réelles. Il a également été utilisé pour des jeux de guerre numériques qui simulent des scénarios de combat.
Avantages de l'apprentissage par renforcement
Les avantages de l'apprentissage par renforcement sont notamment les suivants :
- Fonctionne dans des environnements complexes. Les algorithmes RL sont utilisables dans des environnements statiques et dynamiques.
- Ne nécessite pas beaucoup d'attention. Les algorithmes RL peuvent apprendre sans supervision humaine.
- Est optimisé pour des objectifs à long terme. Les algorithmes RL sont axés sur l'optimisation des processus afin d'obtenir des récompenses cumulatives maximales.
Défis liés à l'application de l'apprentissage par renforcement
L'apprentissage par renforcement, bien que très prometteur, s'accompagne des compromis suivants :
- Une applicabilité limitée. Il peut être difficile à déployer et son application reste limitée. L'un des obstacles au déploiement de ce type d'apprentissage automatique est sa dépendance à l'égard de l'exploration de l'environnement. Par exemple, si un robot dépendant de l'apprentissage par renforcement était déployé pour naviguer dans un environnement physique complexe, il chercherait de nouveaux états et entreprendrait différentes actions au fur et à mesure de ses déplacements. Avec ce type de problème d'apprentissage par renforcement, il est toutefois difficile d'adopter systématiquement les meilleures actions dans un environnement réel en raison de la fréquence à laquelle il change.
- Elle demande beaucoup de temps. Le temps nécessaire pour s'assurer que l'apprentissage est effectué correctement par le biais de cette méthode peut en limiter l'utilité et solliciter fortement les ressources informatiques. Au fur et à mesure que l'environnement de formation devient plus complexe, les exigences en matière de temps et de ressources informatiques augmentent.
- Difficile à interpréter. Les algorithmes complexes de NR auront une raison pour laquelle ils effectuent un ensemble spécifique d'actions, mais il peut devenir difficile pour les observateurs humains de déterminer la logique qui les sous-tend.
- Exigeant en termes de ressources. L'apprentissage par renforcement nécessite beaucoup de données et de calculs. En comparaison, l'apprentissage supervisé peut fournir des résultats plus rapides et plus efficaces aux entreprises, à condition de disposer de la quantité de données nécessaire. L'apprentissage supervisé peut être utilisé avec moins de ressources.
Algorithmes courants d'apprentissage par renforcement
Plutôt que de se référer à un algorithme spécifique, le domaine de l'apprentissage par renforcement se compose de plusieurs algorithmes qui adoptent des approches quelque peu différentes. Les différences sont principalement dues aux différentes stratégies qu'ils utilisent pour explorer leurs environnements :
- État-action-récompense-état-action. Cet algorithme d'apprentissage par renforcement commence par donner à l'agent ce que l'on appelle une politique. Pour déterminer l'approche optimale basée sur la politique, il faut examiner la probabilité que certaines actions aboutissent à des récompenses, ou à des états bénéfiques, afin de guider la prise de décision.
- Apprentissage Q. Cette approche de l'apprentissage par renforcement adopte l'approche inverse. L'agent ne reçoit aucune politique et apprend la valeur d'une action en explorant son environnement. Cette approche n'est pas basée sur un modèle, mais plutôt autodirigée. Les implémentations de l'apprentissage Q dans le monde réel sont souvent écrites à l'aide de la programmation Python.
- Réseaux Q profonds. Combinés à l'apprentissage Q profond, ces algorithmes utilisent des réseaux neuronaux en plus des techniques d'apprentissage par renforcement. Ils sont également appelés apprentissage par renforcement profond et utilisent l'approche d'exploration autodirigée de l'environnement de l'apprentissage par renforcement. Dans le cadre du processus d'apprentissage, ces réseaux basent les actions futures sur un échantillon aléatoire d'actions bénéfiques passées.
- Recherche arborescente de Monte Carlo. Cette approche d'apprentissage par renforcement basée sur un modèle utilise des simulations pour construire un arbre de recherche et fonde ses décisions sur les résultats. La méthode bénéficie de la combinaison de la généralité apportée par la simulation et de la précision apportée par la recherche arborescente.
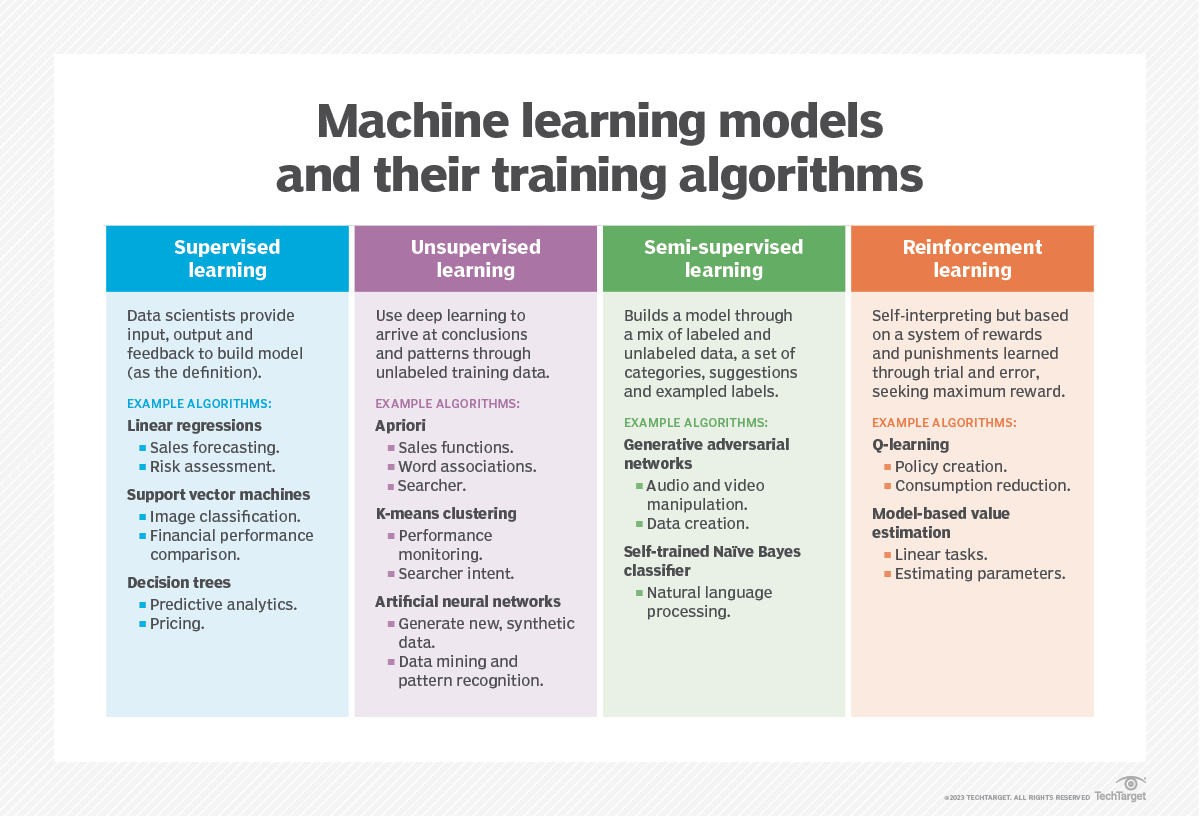
Comparaison de l'apprentissage automatique renforcé, supervisé et non supervisé
L'apprentissage par renforcement est considéré comme une branche à part entière de l'apprentissage automatique. Toutefois, il présente certaines similitudes avec d'autres types d'apprentissage automatique, qui se répartissent dans les quatre domaines suivants :
- Apprentissage supervisé. Les algorithmes s'entraînent sur un ensemble de données étiquetées. Les algorithmes d'apprentissage supervisé ne peuvent apprendre que les attributs spécifiés dans l'ensemble de données. Les modèles de reconnaissance d'images constituent une application courante de l'apprentissage supervisé. Ces modèles reçoivent un ensemble d'images étiquetées et apprennent à distinguer les attributs communs de formes prédéfinies.
- Apprentissage non supervisé. Dans le cadre de l'apprentissage non supervisé, les développeurs lâchent les algorithmes sur des données totalement non étiquetées. Les algorithmes apprennent en cataloguant leurs propres observations sur les caractéristiques des données, sans qu'on leur dise ce qu'ils doivent rechercher.
- Apprentissage semi-supervisé. Cette méthode adopte une approche intermédiaire. Les développeurs saisissent un ensemble relativement restreint de données de formation étiquetées ainsi qu'un corpus plus important de données non étiquetées. L'algorithme d'apprentissage semi-supervisé est alors chargé d'extrapoler ce qu'il apprend des données étiquetées aux données non étiquetées et de tirer des conclusions à partir de l'ensemble.
- L'apprentissage par renforcement. Il s'agit d'une approche différente. Il place un agent dans un environnement avec des paramètres clairs définissant les activités bénéfiques et les activités non bénéfiques, ainsi qu'une finalité globale à atteindre.
L'apprentissage par renforcement s'apparente à l'apprentissage supervisé en ce sens que les développeurs doivent donner aux algorithmes des objectifs précis et définir des fonctions de récompense et de punition. Cela signifie que le niveau de programmation explicite requis est plus élevé que dans l'apprentissage non supervisé. Cependant, une fois ces paramètres définis, l'algorithme fonctionne de manière autonome, ce qui le rend plus autodirigé que les algorithmes d'apprentissage supervisé. C'est pourquoi l'apprentissage par renforcement est parfois considéré comme une branche de l'apprentissage semi-supervisé ; en réalité, il est le plus souvent considéré comme un type d'apprentissage automatique à part entière.
La différence essentielle entre les deux est que l'apprentissage non supervisé n'a pas de résultat spécifique, alors que l'apprentissage par renforcement a un objectif final prédéterminé : optimiser un système ou terminer un jeu vidéo, par exemple.
L'avenir de l'apprentissage par renforcement
L'apprentissage par renforcement est appelé à jouer un rôle plus important dans l'avenir de l'IA. Les autres approches de formation des algorithmes d'apprentissage automatique nécessitent de grandes quantités de données de formation préexistantes. Les agents d'apprentissage par renforcement, quant à eux, ont besoin de temps pour apprendre progressivement à fonctionner en interagissant avec leur environnement. Malgré les difficultés, diverses industries devraient continuer à explorer le potentiel de l'apprentissage par renforcement.
L'apprentissage par renforcement s'est déjà révélé prometteur dans divers domaines. Par exemple, les entreprises de marketing et de publicité utilisent des algorithmes formés de cette manière pour les moteurs de recommandation. Les fabricants utilisent l'apprentissage par renforcement pour former leurs systèmes robotiques de nouvelle génération.
L'apprentissage par renforcement continue également à s'améliorer en termes d'efficacité. Les techniques d'apprentissage par transfert intégrées dans le processus améliorent l'efficacité en permettant aux agents d'utiliser les compétences acquises précédemment pour résoudre d'autres problèmes. Cela permet de réduire le temps nécessaire à la formation d'un système.
De même, l'apprentissage par renforcement (deep learning) continue de s'améliorer, ces systèmes devenant plus indépendants et plus flexibles.
Des technologies telles que l'apprentissage par renforcement apparaissent comme un moyen d'améliorer les expériences numériques des clients basées sur l'IA. D'autres technologies dans ce domaine comprennent la simulation de l'IA, l'IA générative et l'apprentissage automatique fédéré.
Les algorithmes d'apprentissage automatique utilisent une ou plusieurs approches de formation, y compris l'apprentissage par renforcement. Découvrez les différents types d'algorithmes d'apprentissage automatique.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que le feature engineering ?
Par: Linda Rosencrance
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que l'apprentissage automatique (AutoML) ?
Par: Ben Lutkevich
-
![]()
L'apprentissage par renforcement à partir du feedback humain (RLHF) ?
Par: Andy Patrizio



