
Warakorn - Fotolia
Terbium Labs met à profit MapR pour découvrir les données volées
La distribution Hadoop de MapR a permis à la jeune pousse de construire un système d’analyse de données à hautes performances pour aider les entreprises à découvrir les brèches dont elles ont été victimes à leur insu.

Terbium Labs revendique une approche originale de la sécurité. Le postulat de base que décrit Michael Moore, co-fondateur et directeur technique de la jeune pousse, est désormais bien ancré dans les esprits : « les données sont et seront toujours en danger, quels que soient les systèmes et pratiques de sécurité adoptées dans l’entreprise. Un acteur suffisamment motivé parviendra toujours à entrer et à prendre des données ».
Alors Terbium prend acte de données préoccupantes comme celles du rapport Mandiant 2015 sur les cybermenaces : en moyenne, il s’écoule plus de 200 jours avant qu’une brèche de sécurité ne soit découverte, et une très large majorité de ces brèches ne sont pas découvertes par la victime, mais par un tiers, client ou partenaire, notamment.
Dès lors, Michael Moore, ancien de l’université Johns Hopkins et spécialiste de l’analytique, explique ne pas avoir voulu « s’appuyer sur des technologies classiques telles que des sondes sur le réseau », mais pour se concentrer sur les données elles-mêmes et « ce qu’il leur arrive après la brèche, par exemple lorsqu’elles sont mises en vente sur ce que l’on appelle le Dark Web ». D’où MatchLight, qu’il présente comme un « moteur de recherche pour le Dark Web », qui collecte en continu des signatures de données volées pour les comparées aux signatures des données des clients de Terbium Labs. Et un résultat positif « peut constituer un indicateur de brèche dont le client n’est lui-même pas au courant ».
Respecter la confidentialité
Mais pas question de faire de Terbium un vecteur potentiel de brèche en lui permettant d’accéder aux données que ses clients veulent justement surveiller. Ainsi, Terbium fournit à ses clients « du code de référence ; environ 15 lignes en Pyhton », assorti d’un accès aux API de MatchLight, explique Michael Moore. Ce sont donc les clients de la jeune pousse qui réalisent les signatures de leurs données et qui les transfèrent ensuite pour chercher des correspondances.
Mais il ne s’agit pas de produire des signatures de fichiers ou de documents complets : « nous travaillons avec une granularité bien plus grande, à partir de blocs de fichiers qui peuvent n’être que de 14 caractères ». C’est l’ensemble des hash de qui constitue l’empreinte d’un fichier. Mais cette granularité permet donc de trouver des correspondances avec un niveau de finesse très élevé. Pas question en revanche de descendre en dessous de 14 caractères : « trouver des correspondances serait trop facile » et le moteur de recherche risquerait donc de produire trop de faux positifs.
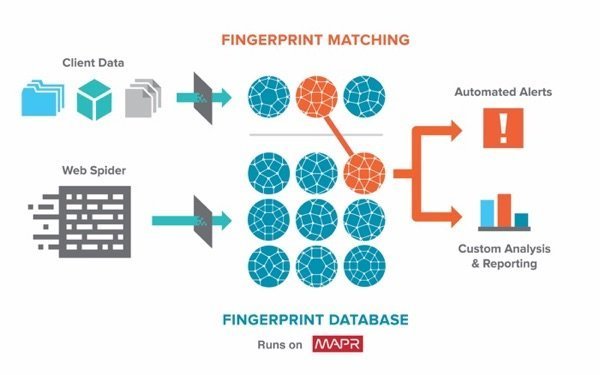
En parallèle, Terbium procède à la même construction de signatures à partir de données trouvées sur le Dark Web, en continu. Mais avec une subtilité : la signature est constituée à partir de séquences de 14 caractères à partir du début des données, puis de leur premier caractère, puis du second, etc. De quoi, le cas échéant, lui permettre de trouver des correspondances dès qu’un client commence à transférer des signatures pour ses données.
MapR pour traiter d’importants volumes de données
Terbium se retrouve donc à manipuler en continu des données fortement structurées, « distribuées de manière très uniforme, et d’une très grande cohésion en termes de format », mais surtout en très très grand volume – et « sans possibilité de compression ». D’où le recours à Hadoop, et en particulier à la distribution de MapR : « MapR-DB supporte l’ingestion en continu et à grande vitesse d’importants volumes de données. Mais la chose la plus importante que nous apporte MapR, c’est une capacité de recherche en temps réel. Nos clients uploadent l’empreinte de leur recherche et peuvent obtenir très vite des résultats, avec des liens pointant vers les documents trouvés ».
Et l’échelle qui concerne Terbium est impressionnante : « nous travaillons actuellement plus de 523 milliards d’empreintes et nous ajoutons environ 10 milliards par jour ; un chiffre qui est en train de progresser ».
Mais pourquoi MapR ? Question de performances : « nous avons commencer par réaliser un prototype du système avec Cloudera et, très franchement, cela ne permettait pas de répondre à la charge ». Ou bien Terbium aurait dû consentir des investissements conséquents pour doter son infrastructure d’un nombre de nœuds trop élevés pour ses capacités financières de jeune pousse. Alors pour Michael Moore, MapR fait la différence avec son implémentation en C du système de fichiers HDFS, et de MapR-DB : « cela nous permet de profiter de performances bien plus élevées à un coût bien inférieur ».
Aujourd’hui, Terbium monétise sa technologie de plusieurs manières différentes. La plus populaire à ce stade est la surveillance d’empreintes de données en continu, facturée à l’abonnement, mais la jeune pousse accepte également les missions ponctuelles de recherche sur ses archives ou encore la surveillance de mots clés et d’expressions régulières.
Pour approfondir sur Base de données
-
![]()
Évaluer les coûts et les avantages de la surveillance du dark web
Par: John Burke
-
![]()
DDoS contre X : les affirmations d’Elon Musk tournées en dérision
Par: Valéry Rieß-Marchive
-
![]()
Ransomware : 75 millions de dollars, la rançon record obtenue par Dark Angels
Par: Valéry Rieß-Marchive
-
![]()
Antivirus (anti-malware)
Par: Linda Rosencrance



