Hadoop : les projets qui ont le vent en poupe
Doug Cutting, celui par qui Hadoop est arrivé, est revenu avec LeMagIT sur les projets qui montent dans la sphère Hadoop, sur les cas d’usages types et sur les rapports de la société avec Intel. Echanges avec ce géant du Big Data.

Il est celui par lequel Hadoop est venu. Doug Cutting, créateur du framework clé du Big Data, aujourd’hui architecte en chef de Cloudera, est revenu avec la rédaction sur les rapports de la société avec Intel, les projets qui montent dans la sphère Hadoop et sur les cas d’usages. Echanges avec ce géant du Big Data.
"Nous investissons dans Spark pour qu'il soit parfaitement intégré à l’écosystème"

LeMagIT : Quels sont les projets Hadoop qui ont retenu votre attention et sur lesquels vous travaillez au sein de Cloudera ?
Doug Cutting : Nous essayons de réduire l’écart entre ce que propose le projet Open Source Hadoop et ce dont les entreprises ont véritablement besoin. Et dans tous les cas, cela signifie pour nous d’investir encore davantage dans l’Open Source et continuer à intégrer des nouveaux projets à la plateforme.
Mais tout en ajoutant des composants en dehors de la communauté Open Source, notamment en matière d’administration. Au final, nos clients voient de la valeur là où ils sont aujourd’hui limités.
Nous investissons également dans des technologies comme Spark (NDR : un moteur alternatif à MapReduce qui ne se limite pas au batch) afin que ce projet soit parfaitement intégré au reste de l’écosystème.
Nos clients voient de la valeur là où ils sont aujourd’hui limités
Nous avons travaillé sur la sécurité, qui est un élément clé. Il s’agit de s’assurer que les données soient bien chiffrées à tous les niveaux, y compris dans Spark. La sécurité est un élément critique pour aider les entreprises à adopter Spark dans des industries très réglementées.
Spark est un excellent projet, mais sans fonctions de sécurité, il n’est pas très utile. Nous travaillons également à en faire un backend pour Hive (NDR : technologie permettant de faire des requêtes de type SQL sur un cluster Hadoop dans un contexte de Datawarehouse) pour créer un moteur SQL batch optimisé et cela sera intégré très prochainement à notre plateforme.
Des travaux autour de Kafka (NDR : bus de messages) sont également en cours.
LeMagIT : Quels sont aujourd’hui vos rapports avec Intel ?
Doug Cutting : Les orientations que nous poussons sont aussi le fruit de notre collaboration avec Intel. Tout l’écosystème doit bien fonctionner sur les nouveaux hardwares Intel au moment de leur sortie. Ils partagent leur roadmap avec nous afin d’être sûr de la compatibilité avec les capacités hardware.
Et aussi
Le checksum a déjà été intégré, ainsi que le chiffrement de fichiers. Nous travaillons également sur les nouveaux systèmes de mémoire d’Intel. Nous avons accès aux versions en avance de phase pour nous assurer qu’Hadoop fonctionnera de pair avec ces nouvelles fonctions. C’est l’objectif de notre collaboration avec Intel.
Si vous êtes une société comme Intel et que vous passez beaucoup de temps à investir sur le hardware, vous avez la volonté que ce hardware puisse véritablement être utilisé et créer de la valeur immédiatement.
LeMagIT : Intel développait à l’origine sa propre distribution Hadoop. Cloudera a-t-il rapproché ces développements de sa plateforme ?
Doug Cutting : Absolument. Les travaux portant sur le chiffrement au repos des données dans HDFS ont été réalisés par Intel. Nous collaborons désormais avec leurs équipes de développement. Leurs travaux ont été intégrés à CDH ainsi qu’au cœur Open Source d’Hadoop.
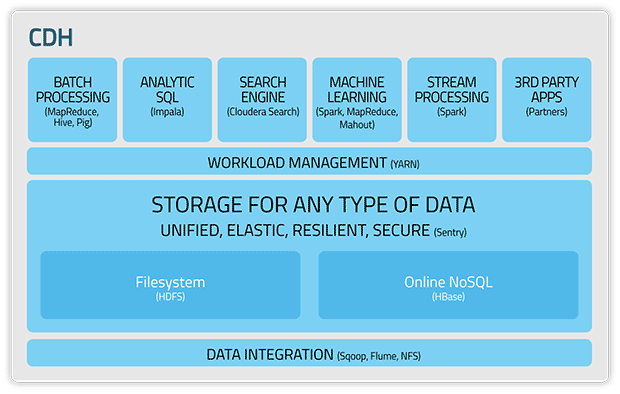 Les différentes briques de CDH, la distribution Hadoop de Cloudera
Les différentes briques de CDH, la distribution Hadoop de Cloudera
Pour l’essentiel, la distribution d’Intel a été intégrée, y compris la possibilité d’optimisation avec le hardware du groupe, le chiffrement et un certain nombre d’autres fonctions. Nous permettons aussi aux clients de la distribution Intel de devenir facilement client Cloudera.
LeMagIT : Cela illustre-t-il un point de départ pour Cloudera. Devrions-nous assister à d’autres partenariats clés avec l’industrie du hardware, notamment avec le monde ARM, de plus en plus actif dans le domaine des serveurs ?
Il est fort probable que nous supportions l'architecture ARM
Doug Cutting : Il est fort probable que nous supportions cette architecture. Je ne pense pas que nous ayons encore été approchés.
Nous sommes des partenaires de longue date de HP, Dell et Oracle via une série d’appliances. Nous collaborons également avec Teradata, Amazon et Microsoft.
Nous essayons de nouer des partenariats avec autant de sociétés que nous pouvons. Ce que nous faisons est complémentaire de ce que font ces fournisseurs de technologies.
LeMagIT : Cela aide-t-il Cloudera à être plus près des vrais besoins des entreprises ?
Doug Cutting : Cela nous aide à proposer de meilleurs produits et mieux nous intégrer avec le hardware. Avoir Intel comme partenaire nous ouvre également beaucoup de portes. En théorie, ils vendent des puces, mais Intel dispose de nombreuses connexions dans l’industrie. Ils forment un canal clé pour nous.
Ils nous ont ouvert le marché en Chine, car le groupe y était déjà présent. Cela va donc bien au-delà de cette collaboration autour du hardware. Ils sont également des utilisateurs d’Hadoop en interne et nous donnent des retours pour améliorer la plateforme. Il s’agit d’un cercle vertueux pour optimiser également les puces d’Intel.
LeMagIT : Vous avez cité précédemment des projets qui montent dans la sphère des technologies Hadoop, comme Spark, Storm (outil de Complex Event Processing) ou Kafka. Des projets complémentaires à Hadoop. Pensez-vous que ces projets finiront à terme intégrés au cœur Hadoop ?
A terme, Spark remplacera MapReduce [mais] Hadoop et Spark ne fusionneront pas
Doug Cutting : Nous créons une distribution à partir du cœur Open Source d’Hadoop. Nous devons donc sélectionner les composants pour lesquels nous allons proposer du support et dans lesquels nous allons investir. Il s’agit d’une opération délicate.
Parfois, nous devons anticiper ce que pourrait être à terme la demande des clients. Avec Spark, nous avons été des "early adopters" car nous pensions que ce projet allait être utile. Un outil meilleur que MapReduce, capable de supporter davantage d’opérations.
Nous devons également nous adapter lorsque des clients utilisent déjà une technologie et souhaitent donc un support . Toutefois, nous ne devons pas surcharger nos contributions. Nous ne pouvons pas supporter une centaine de projets. Nous essayons de ne supporter que des projets dans lesquels nous disposons d’une expertise et dans lesquels nos équipes peuvent contribuer.
Les utilisateurs Linux ne maintiennent pas le Kernel. Ils utilisent une distribution. C’est pareil dans le monde Hadoop
Hadoop et Spark sont deux projets différents au sein de la fondation Apache. Ils sont complémentaires et ne fusionneront pas. Spark peut aussi s’exécuter en dehors d’ Hadoop.
Je ne pense pas que les fusionner apporte un quelconque gain. Ils sont utiles en tant que projets séparés et autonomes. A terme, Spark remplacera MapReduce. Ce dernier sera toutefois conservé dans certains cas.
Hadoop n’est jamais utilisé seul. La technologie est utilisée avec d’autres outils. Personne ne télécharge Hadoop et l’exécute en l’état. Très peu de personnes installent et maintiennent Hadoop directement depuis la fondation Apache. A l’image des utilisateurs Linux qui ne maintiennent pas le noyau Linux et ne chargent pas les paquets dont ils ont besoin. Ils utilisent une distribution.
C’est pareil dans le monde Hadoop. Il existe ainsi plusieurs distributions, dans un environnement concurrentiel sain.
LeMagIT : Quels sont les cas d’usages clé d’Hadoop identifiés par Cloudera ?
Doug Cutting : Dans certaines industries, nous avons identifié des patterns d’usage Big Data.
Dans les services financiers, on s’intéresse à l’évaluation des risques et à avoir une vision temps réel de leur exposition au risque.
Nous avons identifié des patterns d’usage, ce sont les mêmes outils configurés de la même façon dans 90% des cas
Ce qui est critique pour eux mais qui est difficile à mettre en place. Mais il existe des outils que l’on peut configurer d’une certaine façon pour réaliser ces opérations. Nous pouvons désormais décrire cela et lorsqu’une banque vient nous voir et a une problématique autour de l’évaluation du risque, nous pouvons lui présenter une typologie de configuration, une sorte de blueprint. Nous pouvons la généraliser.
La prochaine étape consiste à créer une application prête à être utilisée. Nous n’en sommes pas encore là. Mais cela devrait arriver dans les prochaines années. La détection de fraude est également un autre cas d’usage. Encore une fois, ce sont les mêmes outils configurés de la même façon dans 90% des cas. Ces solutions se sont généralisées cette année et nous pouvons aider les clients à les reproduire.
Nous n’avons pas du code préconfiguré, mais une série de documentations que nous pouvons fournir aux entreprises qui peuvent rassembler une équipe compétente via nos services professionnels.
Sur le même sujet
Nous utilisons cela également pour mener les développements du code lorsque par exemple nous identifions une fonction qui manque et qui serait très utile. Des nombreuses fonctions de sécurité ont été bâties en ce sens dans Hadoop.





