Amazon Security Lake : AWS s’engouffre dans la brèche du cyber data lake
AWS embrasse la tendance du lac de données dédié à la cybersécurité, une tendance d’abord mise en exergue par Snowflake. De son côté, le géant du cloud entend industrialiser le concept.
Lors de sa conférence annuelle, AWS a annoncé la préversion d’Amazon Security Lake, une solution pensée pour centraliser toutes les données de sécurité dans un lac de données à l’échelle du pétaoctet et de pouvoir les analyser à partir de différents outils utilisés par les équipes de sécurité et les développeurs.
Cette solution émerge de plusieurs constats et de tendances dans l’écosystème de la cybersécurité. Les logs et événements de sécurité proviennent de multiples systèmes et applications. Ces données doivent être corrélées par différents outils de supervision, de détection de vulnérabilités, de menaces, de protection, etc. Et les entreprises ne déploient pas un seul type d’outils, mais plusieurs, suivant les besoins des équipes. Les progiciels et les données sont donc dispersés entre différents systèmes qui communiquent mal entre eux.
Pire, un seul éditeur peut offrir une multitude de produits ne reposant pas sur les mêmes puits de données. Ce travail d’unification des données de supervision et de sécurité dans un lac était nécessaire pour des acteurs comme Splunk, Datadog, Elastic ou encore Micro Focus. L’intérêt pour un éditeur serait de devenir l’unique interlocuteur du client, qui choisirait des solutions de son catalogue capable d’interroger des données réunies dans un seul lac de données.
Or, cela réclame une forme de consolidation. Certaines entreprises ne veulent pas se débarrasser de leur existant. La solution d’un éditeur peut être bonne dans un domaine, mais celle du concurrent peut être meilleure dans un autre. Et, chacun de ces fournisseurs a mis sur pied son propre système de données. Si des passerelles ou des connecteurs existent, les données demeurent – la plupart du temps – dans des silos.
Sur les traces de Snowflake
Certains spécialistes, dont Omer Singer, responsable de la stratégie de cybersécurité chez Snowflake, ont plaidé pour la mise au point d’un data lake consacré à la cybersécurité agnostique des solutions du marché, et ce, dès 2019.
Snowflake est donc l’un des premiers éditeurs d’un data warehouse/data lake cloud à se positionner en juin dernier comme le fournisseur d’un « data cloud » consacré à la cybersécurité. La solution est proposée en partenariat avec Securonix, Tenable, Orca, Panther ou encore Lacework qui utilisent déjà Snowflake pour stocker leurs données.
Deux raisons à cela. Premièrement, Frank Slootman, CEO et président au conseil de l’entreprise, est également un investisseur. Snowflake Ventures a investi dans plusieurs éditeurs de la cybersécurité, dont Securonix, Lacework et Panther. Deuxièmement, cela résonne particulièrement avec une tendance plus large dans l’IT : la verticalisation des solutions par secteur ou par domaine.
Finalement, les systèmes de supervision, de détection et de protection reposent sur des bases de données, des entrepôts, des data lakes, des colonnes, des lignes, des paires clé-valeur, des documents, des outils de recherche, d’analyse ou encore des algorithmes de machine learning. C’est la conviction d’Elastic, parti de l’enterprise search pour également devenir l’éditeur d’un SIEM. « La sécurité est un problème de données », indiquait Mandy Andress, RSSI d’Elastic au MagIT lors de l’ElasticOn 2022 à Amsterdam.
Et, fondamentalement, un problème de données est un problème d’infrastructure : de stockage, de calcul et de réseau. Évidemment, ces enjeux intéressent AWS, ils sont au centre de son activité. D’autant que les éditeurs de solutions de sécurité, mais aussi Snowflake, s’appuient en grande partie sur ses services IaaS, PaaS, et ses magasins de données pour faire fonctionner leurs produits. Cela confère au géant du cloud une force de frappe à laquelle seuls ses concurrents les plus directs peuvent prétendre.
Lors de son événement re:Invent 2022, les porte-parole de la filiale cloud d’Amazon ont répété ad nauseam que la « sécurité est au cœur » de tout ce qu’elle fait et que « 90 % des fonctionnalités » qu’elle annonce « proviennent des retours des clients ». Pourtant, Security Lake semble fortement inspiré de l’offre de Snowflake. Publiquement, Omer Singer ne s’en plaint pas.
« Les annonces en provenance de re:Invent donnent une superbe validation du data lake consacré à la sécurité », avance Omer Singer sur LinkedIn. « Ce modèle est clairement en train de jouer un rôle de taille, dans de plus en plus de programmes de sécurité ».
Si AWS prend la vague un peu plus tard que son coopétiteur, Rod Wallace élude cette question de la parenté d’une telle approche. « Nous discutons avec nos partenaires et nos clients. Tous nous ont dit qu’ils souhaiteraient utiliser un lac de données pour les données de sécurité », avance-t-il.
Normaliser « automatiquement » les données de sécurité
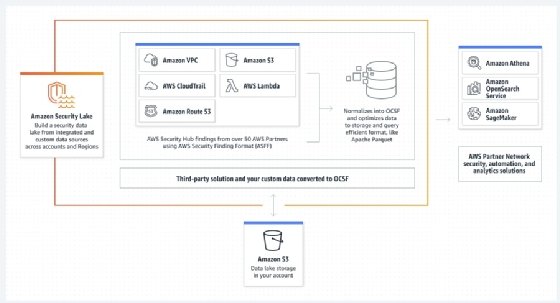
AWS fait donc converger plusieurs services, éditeurs et frameworks pour tenter de mettre en œuvre ce Security Lake. Essentiellement, Security Lake repose sur un pool de stockage objetAmazon S3 résidant dans le ou les comptes AWS d’un client, c’est-à-dire derrière son VPC (Security Lake peut également faire l’objet de déploiements multirégion). Le fournisseur ne souhaite pas limiter les usages des modes de tier de stockage (chaud, tiède, froid). Il sera ainsi possible d’organiser ses propres politiques d’archivage ou de faire confiance à la fonction de tiering intelligent de S3.
Les grands fondamentaux d'Amazon Security Lake
« Les clients veulent aussi se départir des politiques de rétention des éditeurs, qui parfois ne stockent leurs logs que pendant 30 jours », justifie Rod Wallace.
Les logs et les événements de sécurité peuvent être ingérés de diverses manières suivant leur provenance en utilisant des fonctions Lambda et ledata catalog Glue. Si l’ingestion n’est pas gratuite, Rod Wallace assure qu’AWS n’applique pas de coûts d’ingress sur les données extraites des solutions ou d’applications on-premise tierces. « La gestion des coûts de mouvement de données est transparente : ce sont leurs coûts qu’ils gèrent à leur rythme ». Outre les services AWS, Security Lake peut déjà ingérer des données en provenance d’une quinzaine d’outils, de services AWS (Route 53, CloudTrail, VPC, S3, etc.) et tiers (Crowdstrike, Cisco Security, CyberArk, Falco, etc.).
Placer les données dans un même format de table, puis les ranger dans des object stores ne suffit pas. Il convient d’unifier la manière dont elles sont représentées.
Le géant du cloud avait déjà préparé le terrain. En août 2022, il a lancé en collaboration avec Splunk l’initiative open source Open Cybersecurity Schema Framework (OCSF). Autour de la table, l’on retrouve une petite vingtaine d’éditeurs dont IBM, Okta, Zscaler, JupiterOne, Crowdstrike, Palo Alto, Trend Micro, IronNet, Splunk, Tanium, Sumo Logic, Securonix, ou encore Salesforce.
Pour rappel, OCSF est une variante du schéma de données ICD à l’origine imaginé par Symantec. Une fois embarquée dans les connecteurs des outils de sécurité, il est possible d’ingérer des données normalisées répondant au même standard. « OCSF tente de résoudre un problème auquel beaucoup d’éditeurs de solutions de cybersécurité sont confrontés quand ils discutent avec leurs clients », indique Rod Wallace. « Chaque logiciel a son propre modèle de données et cela est très difficile pour les équipes de sécurité de les décoder. Security Lake est le premier data lake à utiliser OSCF », annonce-t-il.
Avec Security Lake, cela implique, dans le cadre de l’ingestion de données, une phase de normalisation des logs au schéma OCSF. « Le coût de cette opération sera minime », assure Rod Wallace.
Ces informations normalisées sont stockées au format Parquet dans les buckets S3 et peuvent être interrogées à travers Athena, OpenSearch ou les outils des partenaires d’AWS, dont le XDR IBM Security QRadar ou les SIEM de Splunk et de Datadog. Dans cette préversion, les solutions de 37 éditeurs et partenaires peuvent déjà écrire ou lire des données, servir de source de données, et de moyen de les traiter, ou les deux. Quicksight, la plateforme BI d’AWS, peut servir à créer des tableaux de bord et des rapports pour les différentes équipes concernées. Plus tard, les clients pourraient développer leurs propres modèles de machine learning et les entraîner sur leurs logs.
Enfin, Lake Formation, la brique de gouvernance d’AWS présentée l’année dernière, est utilisée pour gérer les politiques de rétention, les rôles et les accès aux données par les différentes personnes autorisées à le faire. Le géant du cloud veut aussi proposer des fonctionnalités, comme le masquage des données personnelles ou sensibles dans les logs.
« Security Lake tente de se concentrer sur le problème majeur des clients, à savoir rassembler les données en un seul endroit. Plus tard, nous ajouterons des fonctionnalités pour analyser les données ».
Rod WallaceDirecteur général Amazon Security Lake, AWS
Centraliser d’abord, analyser plus tard
Snowflake a rapidement mis en perspective ce qu’il serait possible de faire avec les fonctionnalités de sa plateforme. Par exemple, l’éditeur a mis en avant ses environnements isolés de partage de données et la possibilité de créer des applications s’exécutant au plus proche de son moteur.
AWS a bien prévu des intégrations avec des outils d’analyse avancée, mais la préversion devra d’abord prouver que l’ingestion, la normalisation et la gestion des données de sécurité fonctionnent correctement dans Security Lake.
« Security Lake tente de se concentrer sur le problème majeur des clients, à savoir rassembler les données en un seul endroit. Plus tard, nous ajouterons des fonctionnalités pour analyser les données », tempère Rod Wallace.