LLM : Avec DBRX, Databricks se met au niveau de Meta, Mistral AI et xAI
Databricks a présenté son LLM DBRX. Ce démonstrateur géant entend prouver qu’il est possible d’entraîner de grands modèles de langage avec les outils de sa plateforme. Plus largement, l’éditeur veut asseoir l’idée que les modèles ouverts sont aussi performants, voire meilleurs que leurs pairs sous licence exclusivement propriétaire.
DBRX est censé être plus efficace que Llama 2-70B et GPT-3.5 dans la plupart des benchmarks. Il égale ou dépasse Grok-1 (314 milliards de paramètres), le modèle développé par xAI, l’entreprise d’Elon Musk et fait jeu égal avec Gemini 1.0 Pro et Mistral Medium. Il reste toutefois derrière GPT-4.
Ensuite, vu l’effervescence autour des LLM, Databricks a lancé plusieurs expériences afin d’obtenir des jeux de données et des modèles pour exister sur la place publique et prouver qu’il est possible de faire, ou de continuer à faire, des projets ouverts, alors que les gros du secteur ont fermé les portes de leur laboratoire et ont rendu propriétaire leurs projets.
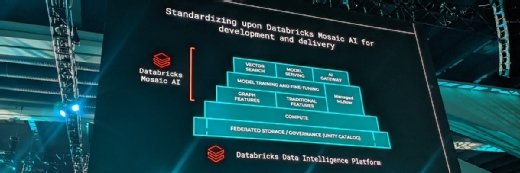
Bien conscient que le marché se tourne massivement vers les modèles d’IA générative, Databricks a racheté plusieurs sociétés, dont MosaicML, un spécialiste de l’entraînement et de l’inférence d’algorithmes de Deep Learning.
« Depuis l’acquisition de MosaicML par Databricks il y a neuf mois, nous avons travaillé d’arrache-pied pour intégrer nos produits, afin essentiellement de rendre utile l’IA générative pour les entreprises en maintenant la gouvernance, la sécurité, et la confidentialité des données au sein de la plateforme Databricks », assure Naveen Rao, vice-président de l’IA générative chez Databricks et ex-CEO et cofondateur de MosaicML, auprès du MagIT.
À la recherche de la maîtrise de la technique « Sparse Mixture of Experts »
Outre une plateforme, MosaicML a développé ses propres LLMs, les MPTs, mis au catalogue de la place de marché de Databricks. DBRX est différent.
DBRX est une famille de modèles autorégressifs « decoder only ». C’est l’appellation technique d’un grand modèle de langage de type GPT (Generative Pretrained Transformer). Il est décliné en deux versions : une version préentraînée, DBRX, et une autre fine-tunée pour suivre des instructions, DBRX-instruct. Jusque-là, pas de surprise. Mais au lieu d’être « dense » comme peuvent l’être MPT et Llama 2, DBRX dépend d’une architecture « Sparse Mixture of Experts » (SMoE).
Cette technique consiste à regrouper des paramètres en lot qui joue le rôle d’experts dans des tâches subalternes du traitement du langage naturel. Au lieu d’activer l’ensemble des paramètres quand des données se présentent en entrée, seuls quelques groupes de paramètres sont appelés pour résoudre un problème. « Le mélange d’experts nous permet d’obtenir la qualité d’un très grand modèle, mais avec l’empreinte d’inférence d’un plus petit modèle », résume Naveen Rao.
Cette approche n’a rien de trivial, considère l’ancien dirigeant de MosaicML. « C’est pour cela que Meta ne s’y est pas encore risqué », affirme-t-il, tandis que Mistral AI avec Mixtral, Google avec Gemini 1.0 Pro et xAI avec Grok-1 misent eux aussi sur cette technique.
« Dans notre cas, nous avons 16 groupes d’experts [là où Mistral en a huit et en sollicite deux avec Mixtral, N.D.L.R.] que l’on peut presque considérer comme des modèles indépendants. Pour chaque utilisateur, on en sélectionne quatre à partir de ces 16 lors de l’entraînement, ce qu’on appelle le “routage” », explique-t-il. « Équilibrer la charge entre ces différents experts n’est pas facile […]. Cependant, malgré le risque, nous avons réussi à faire fonctionner ce système et à démontrer son efficacité économique supérieure », estime-t-il.
« Équilibrer la charge entre ces différents experts n’est pas facile […]. Cependant, malgré le risque, nous avons réussi à faire fonctionner ce système et à démontrer son efficacité économique supérieure ».
Naveen RaoVP of Generative AI, Databricks
DBRX résulte de la mise en pratique de MegaBlocks, un système de SMOE open source pensé par Trevor Gale, un doctorant dont la thèse est dirigée par Matei Zaharia lui-même, et fondé sur les bases des outils d’entraînement de MegatronLM (Nvidia). MegaBlocks doit permettre d’accélérer l’entraînement de 40 % par rapport à l’état de l’art, en subdivisant les opérations nécessaires à l’entraînement de ces groupes de paramètres et en concevant des kernels GPU compatibles avec la nature « éparse » de cette architecture. Les librairies open source MlFlow (Databricks), LLM Foundry, Compose et streaming imaginées par MosaicML ont également été utilisées. Sans évoquer l’usage de la suite Databricks.
DBRX, un LLM encore gourmand
Entraîné à partir de 12 000 milliards de tokens « triés avec soin pour être figés au mois de décembre 2023 » (du texte et du code), soit presque dix fois plus que Llama 2, DBRX bénéficie de plusieurs optimisations du mécanisme d’attention du Transformer sous-jacent. Il utilise les techniques RoPe (encodage rotatif de la position d’un token), Grouped Query Attention (GQA) et la fonction d’activation Gated Linear Unit (GLU) préexistante aux modèles Transformers.
DBRX « est une démonstration de tout le pouvoir de l’étoile noire », plaisante Naveen Rao. « Nous avons utilisé toutes les capacités de Databricks pour entraîner ce modèle, dont celle que nous avons amenée avec MosaicML ».
Le LLM a été entraîné sur 3072 GPU Nvidia H100 interconnectés par un lien Infiniband d’une vitesse de 3,2 Tb/s (selon les préceptes de l’architecture de référence DGX Cloud) pendant trois mois, mais il a réclamé neuf mois de travail. DBRX n’est pas dérivé d’un autre modèle.
« Nous sommes partis de zéro », avance Naveen Rao. « Le mélange d’experts, l’architecture, l’assurance que le modèle peut s’entraîner de manière stable et à haut débit sur des GPU… Tout ce travail a été effectué avant que nous ne commencions le préentraînement », justifie-t-il. « Il a donc fallu une bonne dose d’ingénierie pour y parvenir ».
« Franchement, la seule raison pour laquelle nous avons été plus en retard que prévu sur ce modèle est la disponibilité des GPU. Il s’agissait d’obtenir les GPU auprès de notre fournisseur et de s’assurer qu’ils fonctionnaient tous », ajoute-t-il.
Le partenariat de Databricks avec les fournisseurs cloud et Nvidia ont tout de même facilité la tâche, selon le responsable.
Dans le cas présent, sur les 132 milliards de paramètres de DBRX, environ 36 milliards d’entre eux sont actifs à l’inférence. « Et, c’est en fait très rapide », insiste le VP de l’IA chez Databricks, exemple à l’appui.
Dans une courte démonstration pour LeMagIT, Naveen Rao a comparé simultanément la vitesse des réponses de DBRX et de LLama 2-70B déployés sur des instances Azure équipées de cartes accélératrices Nvidia H100. Quand Llama 2-70B produit sa réponse en 70 à 80 tokens par seconde, DBRX génère le résultat au rythme de 140 à 160 tokens par seconde. « Nous avons optimisé ce résultat [pour DBRX] et nous continuerons à le faire dans les semaines à venir. Nous pensons que nous pouvons atteindre 200 tokens à la seconde d’ici à deux semaines », lance-t-il fièrement au MagIT.
Jusqu’alors, c’est Mixtral 8X7B qui détenait le record du nombre de tokens par seconde à l’inférence, mais Grok-1, disponible depuis le 17 mars, et DBRX ont changé la donne.
D’aucuns pourraient considérer ce résultat « comme de la triche », puisque tout le monde ne peut accéder aux précieuses cartes H100 de Nvidia pour inférer des modèles. « Les 132 milliards de paramètres compressés en huit bits prennent 140 gigaoctets d’espace dans la VRAM et il faut un peu de place pour d’autres opérations, donc deux cartes équipées de 80 Go de VRAM suffisent, mais nous recommandons un cluster de quatre cartes par sûreté », indique Naveen Rao.
Encodé en BFloat16, le modèle réclame 264 Go de VRAM.
« Nous voulions expressément ne pas dépasser quatre GPU pour l'inférence ».
Naveen RaoVP of Generative AI, Databricks
En clair, un cluster de quatre Nvidia A100 (320 Go de VRAM au total) devrait suffire pour exécuter DBRX. « Nous voulions expressément ne pas dépasser quatre GPU pour l’inférence et les nouvelles cartes Nvidia devraient avoir plus de mémoire. Le BH200 intègre 141 Go, donc deux d’entre eux pourront prendre en charge DBRX sans problème », estime le responsable.
DBRX est doté d’une fenêtre de contexte de 32 000 tokens, comme GPT-3.5 Turbo et bien d’autres.
D’autres variantes sont d’ores et déjà prévues. « Nous allons lancer de nouvelles variantes, en particulier la version RLHF », affirme Naveen Rao, qui explique que Databricks n’a pas encore poussé l’apprentissage par renforcement et l’alignement des modèles avec les préférences humaines. « Nous pourrions commencer à commercialiser des modèles spécifiques à un domaine. Il s’agit d’une plateforme complète sur laquelle nous pouvons nous appuyer. Nous prévoyons donc des mois et des mois de travail », anticipe-t-il.
La rapidité d’inférence et une plus faible empreinte mémoire sont les priorités de Databricks. « La barre que j’ai fixée pour notre équipe est de 50 tokens par seconde, au minimum. Si nous parvenons à l’atteindre et à réaliser de meilleures économies [avec un futur modèle], nous aurons un bon candidat », envisage le VP of Generative AI.
Licences : Databricks s’aligne sur Meta
Si Databricks est très transparent sur les méthodes d’entraînement et met à disposition des outils sous licence open source, il applique pourtant dans le cas de DBRX une licence propriétaire permissive. Nommée Open Model License, elle reprend les grandes caractéristiques de la licence appliquée par Meta pour Llama 2. Databricks demande d’accepter ses conditions d’usage acceptables et « de ne pas exploiter DBRX, ses dérivés ou ses sorties pour entraîner un autre modèle que DBRX ou ses dérivés ».
Étrangement, Databricks reprend la condition selon laquelle une condition commerciale s’applique quand l’utilisation directe d’un modèle de cette famille concerne une entreprise de plus de 700 millions d’utilisateurs actifs. Une condition que Meta avait posée pour proposer « des modèles les plus ouverts possibles, sans se tirer une balle dans le pied », dixit le bon mot d’un membre de Meta croisé par LeMagIT. Même si ce choix n’est pas totalement fidèle aux déclarations passées des dirigeants de l’éditeur, il respecte la doctrine présentée en avril 2023 par Ali Ghodsi, CEO de Databricks, souhaitant proposer des solutions ouvertes « commercialement viables ».
XAI, qui ne souhaite aucunement tempérer les usages de ses modèles (le fondateur de Tesla y met un point d’honneur) le propose sous licence Apache 2.0 en mode « open weight », comme l’a fait Mistral AI pour Mistral 7B et Mixtral. Grok -1 est toutefois difficile à exécuter au vu du grand nombre de paramètres et de ses 318 Go de VRAM.
DBRX est disponible via GitHub, Huggingface, AWS, Google Cloud ainsi que sur Azure via Databricks. Il rejoindra le catalogue Nvidia NIM prochainement et pourra être consommé par API dans un avenir proche.
Pour approfondir sur Intelligence Artificielle et Data Science