
Ingestion de données : avec Datastream, Snowflake chasse sur les terres de Confluent
Plutôt qu’un système Apache Kafka managé, Snowflake entend simplifier l’ingestion de données de streaming depuis ce système orienté événements. Un moyen de tacler Confluent et sa solution TableFlow.

Plutôt qu’un système Apache Kafka managé, Snowflake entend simplifier l’ingestion de données de streaming depuis ce système orienté événements. Un moyen de tacler Confluent et sa solution TableFlow.
Snowflake continue d’étoffer ses moyens d’ingestion de données. Après les tables dynamiques qui se mettent à jour automatiquement pour refléter le résultat d’une requête, l’éditeur a présenté Datastream, un service de streaming de données « compatible avec Apache Kafka ».
Bientôt en préversion privée, Datastream est un conteneur logique qui regroupe les topics, les pipes et les groupes de brokers Kafka. Le service géré par Snowflake doit écouter les producteurs et matérialiser les données dans des tables dynamiques Iceberg ou propriétaires. Pour cela, Snowflake prend directement en charge le protocole Kafka Wire.
Il est également possible d’exposer les données de ces tables vers des topics Kafka accessibles par des clients consommateurs, dans une approche egress ou Change Data Capture. Les tables dynamiques sont également sous le contrôle du catalogue Horizon, donc les protections RBAC et de sécurité s’appliquent.
Sous le capot, les mouvements de données sont effectués à travers Snowpipe Streaming. Avec Kafka Connect 4.0, l’ingestion peut atteindre jusqu’à 10 Go/s par table pour une latence moyenne de 5 secondes. Certains tests chez les clients ont atteint jusqu’à 20 Go/s, selon un porte-parole de Snowflake.
Si Snowflake défend dans un blog l’idée de pouvoir « remplacer des infrastructures Kafka », il faut plutôt voir Datastream comme un moyen de simplifier la migration des données événementielles sur Snowflake. Tyler Jones, ingénieur logiciel principal chez Snowflake, rencontré sur le stand dédié à Datastream, ne prétend pas remplacer les « grandes architectures Kafka réparties dans plusieurs entités métiers ». Et le service managé ne s’appuie pas sur le framework orienté événements, mais sur ses composants périphériques.
Datastream, la réponse à TableFlow de Confluent
Derrière ce dispositif technique, Snowflake entend proposer une alternative à TableFlow. C’est un moyen développé par Confluent pour insérer des données en provenance de topics Kafka dans des tables Apache Iceberg ou Delta. « Elle sera prochainement en préversion, mais nous sommes persuadés que nous pouvons proposer une solution compétitive », assure Tyler Jones.
À titre de comparaison, Confluent TableFlow affiche un débit maximum de 7,5 Go/s par cluster facturé à l’heure, auquel il faut ajouter un coût de 0,04 dollar par Go traité ou lu et 0,10 dollar par heure et par topic. Snowpipe streaming est par défaut facturé 0,0037 crédit/Go. Un crédit vaut 2, 3 ou 4 dollars suivant le forfait choisi par le client. Les prix varient donc de 0,0074 dollar à 0,0148 dollar par Go. Évidemment, ce comparatif s’arrête au coût d’ingestion de base : il exclut le prix final de Datastream, tout comme il n’inclut pas le coût de stockage pratiqué par les deux éditeurs. Côté client, les premiers utilisateurs réduiraient leurs coûts de 30 %, selon Snowflake.
« Il était possible de faire la même chose avec Snowpipe Streaming, mais la configuration des connecteurs avec notre SDK et des clusters de Kafka Connect est complexe à maintenir pour les clients », affirme Tyler Jones.
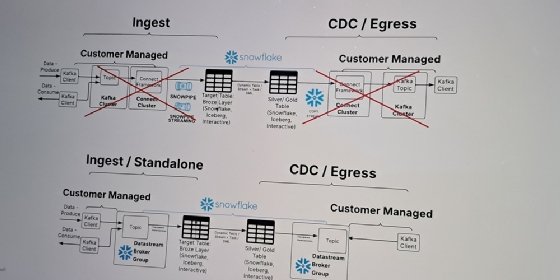
Et l’ingénieur d’assurer que Datastream est également plus simple à configurer que le couple Kafka–Flink, nécessaire au fonctionnement de TableFlow. Dès que les données sont sauvegardées dans les tables dynamiques de Snowflake (pas celle d’Apache Flink), il est possible de les interroger en SQL « en quelques secondes ».
Toutefois, ni le moteur de Snowflake ni Openflow (Apache Nifi) n’ont les capacités de transformation avancées de Flink, reconnaît Tyler Jones. « Nos clients cherchent principalement à effectuer des transformations simples et ne font pas nécessairement partie des quelques dizaines d’entreprises qui utilisent Kafka-Flink à très large échelle ». Parmi ceux-là, LeMagIT peut citer Netflix.
Avant son rachat par IBM, au troisième trimestre fiscal 2025, Confluent affirmait que plus de 1000 clients utilisaient activement Flink. Le revenu récurrent annuel de Flink bénéficiait d’une croissance de 70 % d’un trimestre sur l’autre. Le trimestre précédent, l’éditeur rapportait un ARR de 10 millions de dollars pour cette technologie. Au Q3 2025, le revenu récurrent annuel attribué à Flink chez Confluent atteignait mathématiquement 17 millions de dollars. Cela représente un peu moins de 1,5 % de l’ARR global de Confluent (286 millions de dollars). C’est pourtant là qu’IBM a vu un potentiel. Là où d’autres pourraient suggérer que les clients n’adhèrent pas à cette technologie.
La multiplication des produits d’appel
Snowflake ne joue pas au même jeu. Le prix relativement bas de Snowpipe streaming lui permet d’accroître le volume de données stockées et traitées sur sa plateforme. Là où il gagne véritablement de l’argent.
Malgré l’ouverture effective des technologies du fournisseur au flocon, faire tomber les barrières les plus complexes en matière de traitements de données lui assure de conserver l’adhésion des clients. La majorité d’entre eux n’a pas envie de maintenir des briques open source. Ils souhaitent surtout réduire le nombre de solutions différentes au sein de leur architecture de données. Un sondage d’IDC établit que 97 % des entreprises partagent cet avis.
Cerise sur le gâteau selon Snowflake, il suffira de demander à son IDE agentique CoCo de bâtir les pipelines de streaming de données. Un autre flux agentique devra automatiser la migration de données sur site ou de BigQuery et de MongoDB vers Snowflake via Openflow. Le tout en bénéficiant d’une connexion privée.
C’est la même logique qui motive la création des connecteurs zero copy pour SAP, Salesforce, Workday et d’autres.
Snowflake cherche aussi à relever son jeu en matière de machine learning. En préversion privée, une fonction doit optimiser l’inférence par lot pour accélérer les résultats. Snowpark, l’environnement de travail des ingénieurs ML, a le droit de nouvelles API et de connecteurs JDBC pour simplifier l’importation de données externes. Il s’agit ensuite de les exposer à Apache Spark. Le déploiement de projets Python multifichiers, un générateur visuel de pipelines DAG servant à orchestrer les notebooks ML, ainsi que des librairies de déploiement pour les langages Python et Java (code bundles), sont autant de tentatives de convaincre les rôles les plus techniques.
Jusqu’où ira la consolidation des architectures de données ?
L’attrait d’une plateforme consolidée est fort.
Pour autant, les dirigeants et les ingénieurs chez Snowflake savent qu’ils ne feront pas l’unanimité. Toujours selon IDC, seulement 12 % des entreprises sont prêtes à dépendre d’un seul fournisseur de gestion de données.
Confluent, Fivetran+dbt labs (75 % des clients de Snowflake utiliseraient dbt), Qlik et les autres éditeurs indépendants sont menacés par l’approche de Snowflake. Databricks empreinte le même chemin. Dans un même temps, ces acteurs tiers vivent encore autour de ces grandes plateformes. Ils étaient tous présents lors du Snowflake Summit 2026.
Le pari de Snowflake et Databricks semble en partie gagné, au vu de leur croissance financière respective. « Tant que je gagne, je joue », disait un fameux humoriste.
Pour approfondir sur Datawarehouse
-
![]()
L’IA agentique est désormais au centre de la feuille de route de Confluent
Par: Gaétan Raoul
-
![]()
RAG, A2A, détection d’anomalies : Confluent enrichit son arsenal IA
Par: Gaétan Raoul
-
![]()
IBM met 11 milliards de dollars sur la table pour acquérir Confluent
Par: Gaétan Raoul
-
![]()
Confluent vend un cloud privé qui n’en est pas encore un
Par: Gaétan Raoul



