
Laurent - stock.adobe.com
Apprentissage supervisé et non supervisé : les différencier et les combiner
Découvrez comment LinkedIn, Zillow et d’autres choisissent entre l’apprentissage supervisé, l’apprentissage non supervisé et l’apprentissage semi-supervisé pour leurs projets de machine learning.

On entend davantage parler de l’apprentissage supervisé, car il s’agit généralement de la dernière étape de la construction d’un modèle algorithmique. Cette appellation regroupe des techniques pour faciliter la reconnaissance d’images, obtenir de meilleures prédictions, effectuer des recommandations de produits ou pour l’évaluation de l’intérêt d’un prospect.
En revanche, l’apprentissage non supervisé est invoqué plus tôt dans le cycle de développement de l’IA : il est souvent utilisé pour préparer le terrain et faire en sorte que la magie de l’apprentissage supervisé fasse son effet.
Introduction (simplifiée) aux techniques de machine learning
Techniquement parlant (mais en simplifiant), les termes d’apprentissage supervisé et non supervisé renvoient au fait que les données brutes utilisées pour entraîner les algorithmes ont été pré-étiquetées ou non.
Apprentissage supervisé. Dans l’apprentissage supervisé, les data scientists alimentent les algorithmes avec des jeux de données d’entraînement étiquetées, et définissent les variables qu’ils veulent que l’algorithme évalue pour les corrélations. Les entrées et les sorties sont toutes spécifiées dans cette phase de formation. Par exemple, quand un data scientist essaie d’entraîner un algorithme pour déduire si une image contient un chat, en utilisant l’apprentissage supervisé, il crée une étiquette pour chaque image utilisée dans les données de formation indiquant si l’image contient un chat ou non.
Apprentissage non supervisé. Avec l’apprentissage non supervisé, l’algorithme est entraîné sur des données non étiquetées. Il parcourt les ensembles de données à la recherche de toute connexion significative. Cette approche est utile lorsque vous ne savez pas ce que vous recherchez. Si vous montriez à cet algorithme plusieurs milliers ou millions d’images, il pourrait en arriver à classer un sous-ensemble d’images (un cluster), par exemple celles où les humains reconnaîtraient des félins.
En revanche, un algorithme entraîné sur des images labélisées de chats dans un jeu de comparaison avec des images de chien sera capable d’identifier des images de chat avec un degré de confiance élevé. Mais si le projet d’apprentissage supervisé nécessite un million d’images étiquetées pour développer le modèle, la prédiction générée par le modèle exige beaucoup d’efforts humains (ou autant d’astuces).
Apprentissage semi-supervisé. Les data scientists peuvent prendre une sorte de raccourci appelé apprentissage semi-supervisé qui combine les deux approches. L’apprentissage semi-supervisé décrit un flux de travail spécifique dans lequel des algorithmes d’apprentissage non supervisé sont utilisés pour générer automatiquement des étiquettes, qui peuvent être introduites dans les algorithmes d’apprentissage supervisé. Reprenons notre exemple de la reconnaissance d’images. Dans cette approche, les humains étiquettent manuellement certaines images, l’apprentissage non supervisé devine les étiquettes pour d’autres, puis toutes ces étiquettes et images sont introduites dans les algorithmes d’apprentissage supervisé pour créer un modèle d’IA.
L’apprentissage semi-supervisé a un grand avantage financier. Il permet de baisser le coût de l’étiquetage des grands ensembles de données utilisés dans le cadre du machine learning. « Si vous pouvez faire en sorte que les humains étiquettent 0,01 % de vos millions d’échantillons, l’ordinateur peut alors exploiter ces étiquettes pour augmenter de manière significative sa précision prédictive », assure Aaron Kalb, co-fondateur et directeur de la société Alation, une plateforme de catalogue de données d’entreprise.
 Aaron Kalb, Alation
Aaron Kalb, Alation
Apprentissage par renforcement. Généralement utilisé pour apprendre à une machine à exécuter une séquence d’étapes, l’apprentissage par renforcement est différent de l’apprentissage supervisé et non supervisé. Les scientifiques programment un algorithme pour effectuer une tâche, en lui donnant des indices positifs ou négatifs au fur et à mesure qu’il travaille sur la façon d’effectuer la tâche. Le programmeur fixe les règles pour les récompenses, mais laisse à l’algorithme le soin de décider lui-même des étapes à suivre pour maximiser la récompense, et donc accomplir la tâche.
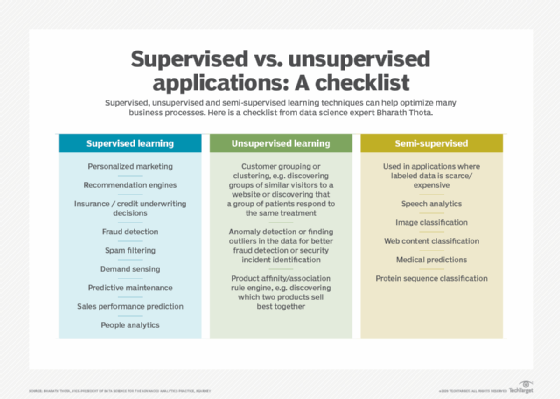
Choisir entre le machine learning supervisé ou non supervisé
Shivani Rao, spécialiste senior en recherche appliquée chez LinkedIn, considère que les meilleures pratiques pour adopter l’apprentissage supervisé ou non supervisé sont souvent dictées par les circonstances, les hypothèses que vous pouvez faire sur les données et l’application qui en découle.
 Shivani Rao, LinkedIn
Shivani Rao, LinkedIn
Le choix d’utiliser des algorithmes d’apprentissage supervisé ou non supervisé peut également évoluer avec le temps, selon Shivani Rao. « Souvent, dans les premières étapes du processus de construction de modèles, les données ne sont pas étiquetées, et on peut avoir besoin de les identifier lors des étapes ultérieures de la modélisation ».
Par exemple, pour un système qui prédit si un membre de LinkedIn va regarder une vidéo de formation, le tout premier modèle sera basé sur une technique non supervisée. Une fois ces recommandations servies, une métrique indique si quelqu’un clique sur la recommandation et fournit ainsi de nouvelles données pour générer une étiquette.
LinkedIn utilise également cette technique pour étiqueter les cours en ligne avec les compétences qu’un étudiant pourrait vouloir acquérir. Les étiqueteurs humains tels qu’un auteur, un éditeur ou un étudiant peuvent fournir une liste très précise et exacte des compétences que le cours enseigne, mais il ne leur est pas possible de fournir une liste exhaustive de ces compétences. Ces données peuvent donc être considérées comme partiellement étiquetées. Afin de pallier ce problème, il est possible d’utiliser des techniques semi-supervisées pour aider à construire un ensemble de balises plus exhaustif.
 Bharath Thota, Kearney
Bharath Thota, Kearney
 Andrea Levy, Alation
Andrea Levy, Alation
Bharath Thota – vice-président de la data science pour la pratique de l’analyse avancée chez Kearney – une société de conseil en stratégie et gestion mondiale, affirme lui aussi que des considérations pratiques ont tendance à régir le choix de son équipe d’utiliser l’une des deux formes d’apprentissage.
« Nous choisissons l’apprentissage supervisé pour les applications lorsque des données étiquetées sont disponibles et que l’objectif est de prédire ou de classer les observations futures » témoigne Bharath Thota. « Nous utilisons l’apprentissage non supervisé, lorsque les données étiquetées ne sont pas disponibles et que le but est de construire des stratégies en identifiant des modèles ou des segments à partir des données ».
Alation adopte une approche similaire pour développer des modèles, selon Andrea Levy, responsable de la data science chez l’éditeur d’un data catalog.
« Les modèles supervisés ont beaucoup de sens lorsque les étiquettes sont faciles à acquérir ou recueillies naturellement au sein du produit », indique-t-elle. Par exemple, dans le cadre d’une plateforme e-commerce, un clic ou un achat peut indiquer un intérêt – et peut être utilisé comme une donnée d’entraînement labélisée.
D’après Andréa Levy, l’objectif de l’apprentissage non supervisé est de trouver la structure naturelle dans des données qui ont déjà été vues, mais qui n’ont pas été catégorisées ou étiquetées. Les modèles non supervisés sont souvent utilisés dans l’exploration des données et la réduction de la dimensionnalité, ce qui implique de trouver des moyens plus efficaces de représenter les données pour un problème spécifique à résoudre.
Aaron Kalb affirme que l’un de ses exemples préférés d’utilisation de l’apprentissage non supervisé pour l’exploration a donné naissance à un modèle appelé Muthuball, créé par Muthu Alagappan alors étudiant à Stanford, dans lequel des grappes topologiques de données sur le basket-ball ont révélé de nouvelles façons de concevoir la composition des équipes pour les entraîneurs et les managers de la NBA. Cette analyse a révélé que les entraîneurs pourraient tirer profit de la réflexion sur treize postes virtuels plutôt que les cinq auxquels ils sont habitués.
Les data scientists d’Alation utilisent l’apprentissage non supervisé en interne pour diverses applications, selon Aaron Kalb. Par exemple, ils ont développé un processus de collaboration homme-machine pour traduire les noms d’objets de données obscurs en langage humain (par exemple, « na_gr_rvnu_ps » en « Revenu brut nord-américain des services professionnels »). Dans ce cas, les algorithmes devinent, les humains confirment et les modèles apprennent.
« Il faut imaginer cela comme une boucle itérative d’apprentissage semi-supervisé, créant un cycle vertueux de précision accrue », vante Aaron Kalb.
 Michael Kim, AArete
Michael Kim, AArete
Michael Kim, vice-président d’AArete, un cabinet de conseil mondial spécialisé dans les performances basées sur les données, a convenu que les techniques d’apprentissage non supervisées peuvent aider à catégoriser les données ou à regrouper les données, afin de démontrer des schémas que les experts humains ne voient pas facilement.
« Cette technique est un moyen très puissant de tester les hypothèses initiales ou d’aider à élaborer de futurs modèles d’apprentissage supervisé », estime-t-il. L’inconvénient, ajoute-t-il, est qu’elle peut être difficile à interpréter pour la prise de décision opérationnelle.
Michael Kim trouve que les modèles d’apprentissage supervisé sont plus faciles à interpréter, car les résultats sont présentés comme des probabilités ou des chances de succès. Le compromis est que les méthodes supervisées sont sujettes à beaucoup plus de biais, car il y a des idées préconçues sur ce que devraient être les entrées ou les sorties.
Le cas de l’expert de l’immobilier Zillow
L’entreprise américaine d’annonces immobilières Zillow utilise l’apprentissage supervisé pour fournir des recommandations personnalisées à ses clients. Le modèle algorithmique sous-jacent est supervisé par des signaux comme le nombre de pages vues sur la page d’accueil du site et les annonces sauvegardées par les utilisateurs.
 Sangdi Lin, Zillow
Sangdi Lin, Zillow
De plus, le Zestimate, une estimation du prix d’une maison, est calculé à l’instar d’un problème classique d’apprentissage supervisé où les étiquettes sont issues des prix de vente récents dans le cadre de transactions immobilières.
« Les données étiquetées ont souvent un coût, mais elles fournissent d’importants signaux de supervision pour l’entraînement des modèles », considère Sangdi Lin, data scientist chez Zillow.
Les données non labélisées, en revanche, sont des données largement disponibles, et elles sont également utiles pour la construction de modèles, selon le spécialiste. « Nous utilisons l’apprentissage non supervisé pour comprendre le modèle et la distribution des données sous-jacentes lorsque les étiquettes ne sont pas disponibles ».
L’apprentissage non supervisé a été utilisé chez Zillow, par exemple, pour comprendre les caractéristiques de différents types de clientèle, tels que les utilisateurs se trouvant à différents stades de l’achat d’un bien immobilier (par exemple, au stade de l’exploration précoce ou au stade prêt à effectuer une transaction).
« L’apprentissage semi-supervisé est utilisé pour combler les lacunes lorsque les données étiquetées ne sont pas disponibles », déclare Sangdi Lin. En utilisant certaines données étiquetées pour la supervision ainsi que des données non étiquetées pour saisir les modèles de données sous-jacents, l’approche améliore la génération du modèle.
Par exemple, l’équipe du data scientist a eu recours à un apprentissage semi-supervisé dans le cadre d’un projet où elle a extrait des phrases clés des descriptions d’annonces, afin de fournir aux clients des informations sur leur maison. Ils ont commencé par des techniques d’extraction de phrases clés non supervisées, puis ont intégré des signaux de supervision provenant à la fois des annotateurs humains et de l’engagement du client sur la page d’accueil afin d’améliorer encore la précision du modèle.
Sangdi Lin explique qu’ils utilisent parfois les différentes approches dans différentes parties du cycle de développement du modèle. Par exemple, l’exploration des données à l’aide de techniques d’apprentissage non supervisé est souvent effectuée à un stade précoce d’un projet de data science. Un data scientist peut appliquer des techniques de regroupement non supervisées et diverses méthodes de visualisation pour comprendre la meilleure façon de formuler un problème de recommandation, et ce afin de former un algorithme d’apprentissage supervisé. Dans d’autres cas, les data scientists peuvent découvrir des clusters et constater qu’ils peuvent obtenir de meilleurs résultats, en entraînant différents modèles supervisés sur chaque cluster de données séparé, plutôt qu’un modèle unique pour toutes les données. Ils peuvent aussi créer des étiquettes dédiées aux clusters pour former un modèle.
La détection d’anomalies, une autre technique d’apprentissage non supervisé, est utilisée par Zillow pour améliorer la qualité des données qui sont ensuite introduites dans les algorithmes d’apprentissage supervisé.
« L’identification des anomalies et l’amélioration de la qualité des données d’entraînement peuvent souvent améliorer la précision des modèles de machine learning », estime Sangdi Lin. Zillow a utilisé cette approche pour améliorer de manière significative son système d’estimation du prix des biens immobiliers.
Conclusion : cinq techniques d’apprentissage non supervisé
En résumé, les techniques d’apprentissage supervisé ont tendance à se concentrer soit sur la régression linéaire (ajustement d’un modèle à une collection de points de données pour la prédiction), soit sur la classification (une image représente-t-elle un chat ou non ?).
Les techniques d’apprentissage non supervisé complètent souvent celles de l’apprentissage supervisé en utilisant diverses manières de découper en dés des ensembles de données brutes. Voici cinq d’entre elles.
1. Regroupement de données. Les points de données ayant des caractéristiques similaires sont regroupés pour aider à comprendre et à explorer les données plus efficacement. Par exemple, Zillow utilise des méthodes de regroupement de données pour identifier les segments d’utilisateurs et découvrir des annonces immobilières similaires.
2. Réduction de la dimensionnalité. Chaque variable d’un jeu de données est considérée comme une dimension distincte. Cependant, de nombreux modèles fonctionnent mieux en analysant une relation spécifique entre les variables. Un exemple simple de réduction de la dimensionnalité consiste à utiliser le profit comme une seule dimension, qui représente le revenu moins les dépenses – deux dimensions distinctes. Cependant, des types plus sophistiqués de nouvelles variables peuvent être générés à l’aide d’algorithmes tels que l’analyse en composantes principales (ACP), les auto-encodeurs (c’est-à-dire la conversion de mots de texte en vecteurs) ou l’incorporation stochastique de voisins t-distribués (t-SNE).
Pour Sangdin Lin, la réduction de la dimensionnalité peut aider à empêcher les phénomènes de surentraînement, dans lesquels un modèle fonctionne bien pour un petit ensemble de données, mais ne se généralise pas bien aux nouvelles données. Cette technique permet également à Zillow de visualiser des données en haute dimension dans un espace 2D ou 3D, que les humains peuvent facilement comprendre. Par exemple, Zillow utilise la réduction dimensionnelle, pour visualiser la façon dont un algorithme de recommandation de maison représente la relation entre plusieurs attributs d’un logement.
3. Détection d’anomalies ou de valeurs aberrantes. L’apprentissage non supervisé peut aider à identifier les points de données qui ne font pas partie de la distribution régulière des données. L’identification et la suppression des anomalies comme étape de préparation des données peuvent améliorer les performances des modèles de machine learning.
4. Apprentissage par transfert (Transfer learning). Ces algorithmes utilisent un modèle qui a été formé à une tâche connexe, mais différente. Par exemple, cette technique permettrait de configurer un classificateur entraîné sur des articles de Wikipédia pour baliser de nouveaux types de texte arbitraires avec les bons sujets. Shivani Rao pense que c’est l’un des moyens les plus efficaces et les plus rapides de résoudre un problème de données, lorsqu’il n’y a pas de labels.
5. Algorithmes basés sur des graphes. Ces techniques tentent de construire un graphe qui capture la relation entre les points de données, explique Shivani Rao. Par exemple, si chaque point de données représente un membre de LinkedIn ayant des compétences, alors un graphe peut être utilisé pour représenter les membres, où les arêtes indiquent le chevauchement des compétences entre les membres.
Les algorithmes de graphes peuvent également aider à transférer des labels de points de données connus vers des points de données inconnus, mais fortement liés. L’apprentissage non supervisé peut également être utilisé pour bâtir un graphe entre des entités de différents types (la source et la cible). Plus l’arête est forte, plus l’affinité du nœud source avec le nœud cible est élevée. Par exemple, LinkedIn les utilise pour faire correspondre des membres avec des cours basés sur les compétences.
Apprentissage supervisé ou non supervisé dans le domaine de la finance
Tom Shea, fondateur et PDG de OneStream Software, une plateforme de gestion des performances d’entreprise, déclare que l’apprentissage supervisé est souvent utilisé dans le domaine de la finance pour construire des modèles très précis, alors que les techniques non supervisées sont mieux adaptées aux tâches de type « calcul de coin de table ».
Dans les projets d’apprentissage supervisé, les data scientists travaillent avec les équipes financières afin d’utiliser leur expertise du domaine sur les produits clés, la tarification et les aperçus de la concurrence, comme un élément critique pour la prévision de la demande. L’expertise métier est particulièrement pertinente, dans les niveaux plus granulaires des besoins de prévision où chaque région, chaque produit et même chaque unité de gestion des stocks, ont des expériences uniques et requièrent de l’intuition. Ces types de modèles dérivés de l’apprentissage supervisé peuvent contribuer à améliorer la précision des prévisions et les indicateurs de stocks qui en résultent.
Tom Shea estime que l’apprentissage non supervisé est utilisé pour améliorer les fonctions de gestion régionales ou divisionnaires qui ne nécessitent pas la connaissance directe du domaine de l’apprentissage supervisé. Par exemple, l’apprentissage non supervisé pourrait aider à identifier le taux normal de dépenses parmi un groupe d’éléments connexes et les valeurs aberrantes. Cela est particulièrement utile pour analyser de grands ensembles de données transactionnelles (commandes, dépenses, facturation) et permet d’accroître la précision lors des processus de clôture financière.






