
alex_aldo - Fotolia
Traçage distribué vs logging : quelles différences ?
Le traçage distribué et la journalisation aident les équipes IT à identifier les dysfonctionnements des systèmes de différentes manières. Mais ils se complètent également pour mettre le doigt sur les problèmes.

Quand une erreur se produit au cœur d’une application ou sur un site Web, les développeurs cherchent souvent à régler le problème en s’appuyant sur deux processus technologiques : le traçage distribué et le logging (la journalisation en français).
Les deux approches peuvent être exploitées dans le cadre de la supervision des performances applicatives. Elles s’inscrivent généralement au programme des initiatives APM et d’observabilité des équipes « Dev » et « Ops ».
Mais il ne faut pas les confondre. Examinons de plus près les deux processus et leurs principales différences, ainsi que la manière dont ils peuvent se compléter.
Qu’est-ce que la journalisation (le logging) ?
Le fonctionnement de la journalisation est simple. Lorsque quelque chose se produit dans un système informatique, comme un message d’erreur, une connexion d’utilisateur ou divers autres événements, les détails sont consignés dans un fichier journal, un « log ». Les entrées du journal sont horodatées et des niveaux de gravité sont parfois automatiquement appliqués, afin d’indiquer la nature des entrées et aider les développeurs à les filtrer pour le contrôle des performances et le dépannage. Les niveaux les plus courants sont DEBUG, INFO, WARN, ERROR et FATAL.
En outre, les entrées comprennent souvent des éléments tels que des codes d’erreur et des informations d’état. Les logs sont essentiels pour diagnostiquer les problèmes au sein d’une application ou d’un service unique. Les équipes peuvent voir exactement ce qui s’est passé juste avant et après une erreur.
Le processus de journalisation est sensiblement le même depuis l’avènement de l’IT. Presque toutes les composantes de l’architecture d’un système créent ces enregistrements. Les trois catégories de logs les plus courantes sont les suivantes :
- Logs applicatifs. Ils comprennent généralement des informations telles que les messages de démarrage/arrêt de l’application, les transactions traitées et les erreurs ou exceptions rencontrées. Les événements personnalisés relatifs à la logique commerciale/métier d’une application peuvent également être consignés.
- Logs système. Ils sont générés par l’OS ou d’autres logiciels au niveau du système, tels que les pilotes de périphériques et les services système. Les journaux système relèvent les événements de bas niveau : signaux d’amorçage, défauts matériels ou de réseau, connexions des utilisateurs, alertes sur la consommation des ressources, etc.
- Logs de sécurité. Ils enregistrent les événements liés à la sécurité IT et aux accès. Il s’agit notamment des détails relatifs à l’authentification des usagers, tels que les connexions réussies, les tentatives de connexion échouées, les contrôles d’autorisation, les changements de mot de passe, les verrouillages de compte et les refus de pare-feu. Les journaux de sécurité alimentent souvent les systèmes de gestion des informations et des événements de sécurité pour la détection des menaces et l’analyse « forensics ».
Parmi les autres types de logs, l’on peut citer ceux des bases de données, qui accompagnent les requêtes, les modifications et autres actions dans les SGBD ; les enregistrements d’audit, qui permettent de suivre l’accès aux données sensibles et d’autres activités dans les systèmes IT afin de soutenir les initiatives de conformité ; et les logs réseau, qui recueillent le trafic réseau et les requêtes API. L’ensemble de ces logs fournit une image presque exhaustive des activités dans un environnement IT.
Les problèmes à connaître de la journalisation
Les logs peuvent être structurés ou non structurés. Les journaux structurés sont stockés dans des formats de données tels que JSON et XML. Là, les entrées ont une structure cohérente – d’où le terme. Ils sont plus faciles à rechercher, à interroger et à analyser que les fichiers texte non structurés, en particulier si les équipes souhaitent employer des outils de logging automatisés pour les aider dans ces tâches. En revanche, les logs non structurés peuvent être plus aisés à lire d’un seul coup d’œil.
Lorsqu’un bug logiciel ou un problème de performance est signalé, les logs fournissent des indices immédiats pour le débogage. Il peut s’agir, par exemple, des traces de la pile d’erreurs, c’est-à-dire de la séquence des routines logicielles qui ont conduit à une erreur, des valeurs de tous les paramètres ou variables du système à ce moment-là et, éventuellement, des identifiants des utilisateurs.
Ce niveau de détail rend les journaux essentiels au respect des réglementations externes et des politiques internes. Les organisations peuvent être amenées à conserver les logs de sécurité pendant un an ou plus afin de vérifier la conformité avec les lois sur la protection de la vie privée. Ils peuvent donc devenir très volumineux. Mais d’autres types de journaux peuvent également occuper beaucoup d’espace disque, compte tenu de la quantité de données enregistrées.
C’est pourquoi il est important d’élaborer une politique unifiée à l’échelle de l’entreprise. Non seulement en matière d’instrumentation utilisée pour générer des logs, mais aussi en ce qui concerne la durée de stockage de ces données. Périodiquement, il est nécessaire de fermer ou de renommer un fichier de logs en cours et d’en créer un nouveau, afin que l’ancien fichier ne continue pas à croître indéfiniment. Une fois que les journaux sont « rafraîchis » de cette manière, les fichiers les plus anciens peuvent être compressés, archivés ou supprimés, ce qui permet d’optimiser la gestion du stockage et de conserver une bonne organisation des logs, pour en faciliter l’analyse.
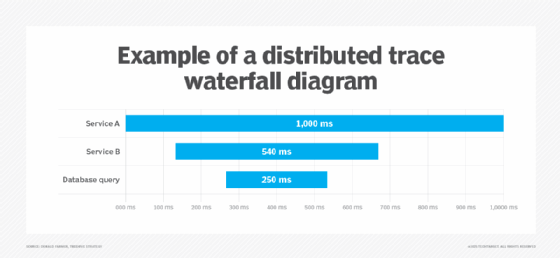
Qu’est-ce que le traçage distribué (distributed tracing) ?
Si les développeurs doivent diagnostiquer des ralentissements apparemment aléatoires affectant certaines requêtes d’utilisateurs dans une application, le recours aux seuls logs peut s’avérer pénible. Ils ne présentent que des messages d’erreur et d’autres entrées de manière séquentielle avec des horodatages. Un développeur peut être en mesure de déterminer que certaines de ces entrées sont liées à la même transaction. Or un log n’offre pas une cartographie automatique de la manière dont une requête passe d’un service ou d’un système à l’autre.
C’est là que le traçage distribué prend toute sa valeur. Il relie tous les éléments impliqués dans le traitement des requêtes à travers plusieurs services, afin que les développeurs et les administrateurs système voient quel service ralentit les opérations ou tombe en panne.
Le traçage distribué permet aux équipes IT de suivre les requêtes individuelles effectuées dans une application à travers tous les services ou processus qu’elles touchent. Dans un environnement de microservices, une seule requête d’utilisateur peut passer par de nombreux composants applicatifs. L’ensemble du chemin de la requête est tracé lorsqu’elle transite du service A au service B, puis au service C, et ainsi de suite.
Les éléments clés du traçage distribué sont les suivants :
- Spans. Au fur et à mesure que les requêtes circulent dans un système, la partie du travail de traitement de chaque service – comme le traitement d’un appel API entrant ou l’interrogation d’une base de données – est encapsulée dans un segment distinct (span en anglais). Par exemple, si le service A appelle le service B et que le service B interroge une base de données, vous obtiendrez trois spans : une pour le travail de A, une pour le travail de B et une autre pour l’appel à la base de données.
- Traces. Une trace combine tous ces spans pour fournir une vue d’ensemble de la manière dont une requête se déplace entre différents services. Chaque segment ou span d’une trace est étiqueté avec le même identifiant de trace, généralement un identifiant universel unique de 128 bits ou un autre type d’UID, de sorte que le contexte de la trace est transmis au fur et à mesure de l’évolution de la requête. Les données capturées dans le cadre d’une trace facilitent le dépannage des problèmes de performance ou de fiabilité dans un système distribué et l’identification de leur cause première.
Fonctionnalités de traçage et problèmes à prendre en compte
Les spans enregistrent à la fois une heure de début et une heure de fin pour le job qu’elles suivent. En mesurant la durée d’un span, les développeurs peuvent voir combien de temps a duré cette partie du processus, c’est-à-dire sa latence. Ces informations temporelles sont cruciales pour repérer les ralentissements ou les erreurs d’un système.
Chaque segment peut également contenir des balises ou des annotations contenant des détails supplémentaires relatifs à l’unité de travail exécutée, telle que le point d’accès à l’API qui est appelé ou un ensemble de paramètres de requête. Ces métadonnées permettent de déterminer pourquoi la tâche représentée par un span a pris plus de temps que d’habitude ou a échoué.
Les spans suivent une structure parent-enfant hiérarchique. Un span racine est le principal et peut-être le seul parent, représentant l’ensemble de la requête de l’utilisateur. Les segments enfant correspondant aux différentes actions de traitement sont imbriqués dans la span racine dans le cadre d’une trace. En outre, certains spans enfants peuvent avoir leurs propres segments enfants si les tâches qu’elles traitent comportent plusieurs étapes.
Ces relations parent-enfant peuvent générer un diagramme en forme d’arbre ou de cascade qui montre l’ensemble du flux mesuré par une trace. En effet, les outils de traçage distribués affichent généralement les spans dans un graphique chronologique ou de dépendance. Chaque segment apparaît sous la forme d’une barre, étiquetée avec sa durée moyenne. La visualisation de l’ensemble des spans, bout à bout, permet de savoir où passe la majeure partie du temps de traitement, quels services sont appelés en parallèle et où se produisent les éventuels goulets d’étranglement.
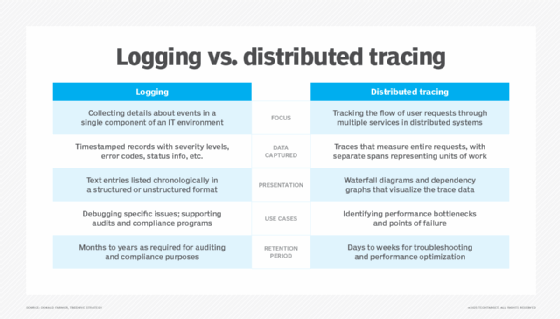
Comme la journalisation, le traçage distribué peut générer d’énormes quantités de données si chaque détail est capturé et stocké. Pour les applications et les services Web présentant un volume élevé de requêtes ou de messages, certaines équipes de développement et d’exploitation IT mettront en place une approche d’échantillonnage qui enregistrera des traces sur 5 à 10 % du trafic.
Si une équipe détecte trop d’anomalies ou soupçonne des problèmes de performance plus importants au fil du temps, elle peut augmenter dynamiquement le taux d’échantillonnage. Cette approche réduit les frais généraux du système tout en permettant aux développeurs, aux administrateurs et aux gestionnaires de sites Web d’observer les patterns d’exécution. Cependant, les traces doivent toujours être exécutées sur des types spécifiques de transactions critiques, telles que les paiements en ligne et autres.
Traçage distribué ou logging : lequel utiliser ?
Le traçage distribué est souvent le moyen le plus rapide de localiser les goulets d’étranglement dans les flux de travail multiservices. Les journaux seuls ne révèlent pas facilement cette chaîne d’événements, même si les informations y sont disponibles. En plus de profiter aux développeurs pour corriger les bogues ou à optimiser les performances, le traçage distribué aide l’équipe Ops à gérer les alertes ou les escalades concernant l’état général d’un système, y compris les serveurs et le réseau.
Comme décrit précédemment, les logs peuvent être conservés à long terme pour des raisons de conformité et d’audit. Les données de traçage distribuées ne sont pas toujours stockées indéfiniment – il s’agit plutôt d’un dépannage quotidien ou à court terme.
Dans la pratique, les développeurs et les administrateurs ne choisissent pas l’un plutôt que l’autre le traçage distribué ou la journalisation ; les deux processus sont complémentaires. Les journaux répondent à l’interrogation suivante : « Que s’est-il passé dans ce composant spécifique à un moment donné ? ». Le traçage distribué, lui, correspond à la question : « Comment une requête complète d’un usager se déplace-t-elle dans le système ? ».
Si l’utilisation du processeur ou de la mémoire monte en flèche dans un système, une équipe d’exploitation IT peut vouloir examiner les traces et les logs. Un pic inhabituel, ou une application qui échoue plus que la normale déclenchent une investigation plus approfondie que la simple surveillance de l’état actuel et des performances, à l’aide des tableaux de bord intégrés aux consoles de gestion des systèmes et aux outils APM. Les étapes ultérieures peuvent être le traçage distribué pour trouver le goulet d’étranglement ou le point de défaillance, puis l’étude d’un enregistrement pour la dernière couche de détails afin d’aider à diagnostiquer la raison du souci.
Une bonne pratique consiste à incorporer un identifiant de trace dans chaque entrée de log afin que les développeurs et les administrateurs puissent établir une corrélation entre des traces spécifiques et un fichier de logs. Ensuite, s’ils remarquent une partie potentiellement problématique d’une trace distribuée, ils peuvent accéder au log et voir facilement ce qui se passe de manière plus détaillée.
Deux piliers d’une stratégie d’observabilité
Le traçage distribué et la journalisation sont fréquemment associés à des mesures de performances globales afin que les développeurs, les administrateurs et les autres professionnels de l’IT puissent superviser les changements au fil du temps dans le cadre des pratiques d’observabilité.
L’observabilité permet aux équipes d’étudier les modèles de problèmes dans les systèmes et de diagnostiquer ceux qu’elles n’avaient pas anticipés lors de la mise en place de leurs processus initiaux de traitement des erreurs. Cette approche exploratoire est particulièrement précieuse dans les systèmes distribués complexes où les interactions entre les composants produisent souvent des comportements imprévisibles, que les outils de surveillance traditionnels ne peuvent pas capturer ou expliquer de manière adéquate.
Une bonne stratégie d’observabilité utilise à la fois la journalisation et le traçage distribué pour aider à veiller, déboguer et optimiser les performances sous plusieurs angles. Les logs, les traces et les métriques collectées par l’APM et d’autres processus de surveillance sont le plus souvent décrits comme les trois piliers de l’observabilité. Chaque méthode répond à des questions différentes sur le comportement de l’application et du système afin de mieux informer les efforts d’observabilité.
Pour approfondir sur Sécurité du Cloud, SASE
-
![]()
FortiClient EMS : une vulnérabilité exploitée pour déployer un cleptogiciel
Par: Valéry Rieß-Marchive
-
![]()
Qu'est-ce que l'APM ? Guide de surveillance des performances des applications
Par: Stephen Bigelow
-
![]()
Dataiku entend centraliser la gestion des projets d’IA agentique
-
![]()
Réseau : comment résoudre les problèmes de DHCP grâce aux logs
Par: Damon Garn



