Qu'est-ce que l'OCR (reconnaissance optique de caractères) ?

L'OCR (reconnaissance optique de caractères) est l'utilisation d'une technologie permettant de distinguer les caractères imprimés ou manuscrits à l'intérieur d'images numériques de documents physiques, comme un document papier scanné. Le processus de base de l'OCR consiste à examiner le texte d'un document et à traduire les caractères en un code qui peut être utilisé pour le traitement des données. L'OCR est parfois appelée reconnaissance de texte.
Les systèmes OCR consistent en une combinaison de matériel et de logiciels utilisés pour convertir des documents physiques en texte lisible par une machine. Le matériel, tel qu'un scanner optique ou un circuit imprimé spécialisé, est utilisé pour copier ou lire le texte, tandis que le logiciel se charge généralement du traitement avancé. Les logiciels peuvent également tirer parti de l'IA pour mettre en œuvre des méthodes plus avancées de reconnaissance intelligente des caractères (RIC), comme l'identification des langues ou des styles d'écriture.
L'OCR est le plus souvent utilisée pour convertir des copies papier de documents juridiques ou historiques en PDF. Une fois le document sous forme de copie papier, les utilisateurs peuvent le modifier, le formater et y effectuer des recherches comme s'il avait été créé à l'aide d'un traitement de texte.
Comment fonctionne la reconnaissance optique de caractères
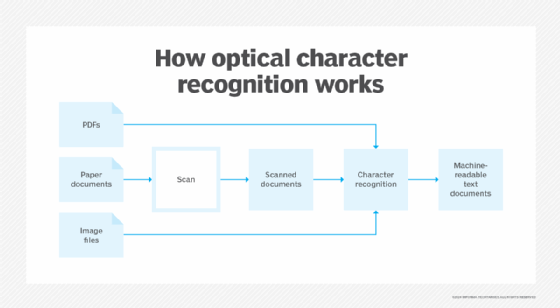
La première étape de l'OCR consiste à utiliser un scanner pour traiter la forme physique d'un document. Une fois toutes les pages copiées, le logiciel d'OCR convertit le document en une version bicolore, ou en noir et blanc. L'image numérisée ou le bitmap est analysé en fonction des zones claires et sombres, les zones sombres étant identifiées comme les caractères à reconnaître et les zones claires comme l'arrière-plan.
Les zones sombres sont ensuite traitées pour trouver les lettres alphabétiques ou les chiffres. Les programmes d'OCR peuvent varier dans leurs techniques, mais ils ciblent généralement un caractère, un mot ou un bloc de texte à la fois. Les caractères sont ensuite identifiés à l'aide de l'un des deux algorithmes suivants :
- Reconnaissance des formes. Les programmes d'OCR reçoivent des exemples de texte dans différentes polices et différents formats. Ils utilisent ensuite la reconnaissance des formes pour comparer et reconnaître les caractères dans le document numérisé.
- Détection des caractéristiques. Les programmes d'OCR appliquent des règles concernant les caractéristiques d'une lettre ou d'un chiffre spécifique pour reconnaître les caractères dans le document numérisé. Les caractéristiques peuvent inclure le nombre de lignes angulaires, de lignes croisées ou de courbes dans un caractère à des fins de comparaison. Par exemple, la lettre majuscule "A" peut être enregistrée sous la forme de deux lignes diagonales qui se rejoignent en une ligne horizontale au milieu.
Lorsqu'un caractère est identifié, il est converti en code ASCII que les systèmes informatiques peuvent utiliser pour effectuer d'autres manipulations. Les utilisateurs doivent corriger les erreurs de base, se relire et s'assurer que les mises en page complexes sont traitées correctement avant de sauvegarder le document pour un usage ultérieur.
Cas d'utilisation de la reconnaissance optique de caractères
L'OCR peut être utilisé pour une variété d'applications, dont les suivantes :
- Numérisation de documents imprimés dans des versions qui peuvent être éditées avec des traitements de texte, comme Microsoft Word ou Google Docs.
- Indexation des documents imprimés pour les moteurs de recherche.
- Automatiser la saisie, l'extraction et le traitement des données.
- Déchiffrer des documents en texte pouvant être lu à haute voix par des utilisateurs malvoyants ou aveugles.
- Archivage d'informations historiques, telles que des journaux, des magazines ou des annuaires, dans des formats consultables.
- Dépôt électronique de chèques sans passer par un guichet de banque.
- Placer des documents juridiques importants et signés dans une base de données électronique.
- Reconnaissance de textes, tels que les plaques d'immatriculation, à l'aide d'un appareil photo ou d'un logiciel.
- Trier les lettres pour la distribution du courrier.
- Traduire les mots d'une image dans une langue donnée.
Avantages de la reconnaissance optique de caractères
Les principaux avantages de la technologie OCR sont les suivants :
- permet de gagner du temps ;
- diminue les erreurs ;
- minimiser les efforts ; et
- permet des actions qui ne sont pas possibles avec des copies physiques, telles que la compression dans des fichiers ZIP, la mise en évidence de mots-clés, l'incorporation dans un site web et l'envoi en pièce jointe d'un courrier électronique.
Si la prise d'images des documents permet leur archivage numérique, l'OCR offre une fonctionnalité supplémentaire pour l'édition et la recherche de ces documents.
L'OCR extrait le texte des images, mais le traitement intelligent des documents (IDP) va plus loin : il comprend le sens et le contexte. Découvrez les principales différences entre l'OCR et l'IDP et pourquoi elles sont importantes.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Avec OCR 3, Mistral AI chasse sur les terres de Google Document AI et Azure AI Vision
Par: Gaétan Raoul
-
![]()
Mistral AI tente de faire bouger les lignes de l’OCR
Par: Gaétan Raoul
-
![]()
Assistants d’IA générative et LLM sont-ils toujours la meilleure option ?
Par: Gaétan Raoul
-
![]()
Box rachète Alphamoon pour rendre son OCR plus « intelligent »
Par: Don Fluckinger


