Qu'est-ce qu'une fenêtre contextuelle ?

Une fenêtre contextuelle est une plage textuelle autour d'un token cible qu'un modèle linguistique à grande échelle (LLM) peut traiter au moment où l'information est générée. En général, le LLM gère la fenêtre contextuelle d'une séquence textuelle, en analysant le passage et l'interdépendance de ses mots, ainsi qu'en encodant le texte sous forme de réponses pertinentes. Ce processus de catalogage des éléments d'une séquence textuelle est appelé tokenisation.
En tant que tâche de traitement du langage naturel, une fenêtre contextuelle s'applique aux questions d'intelligence artificielle (IA) en général, ainsi qu'aux techniques d'apprentissage automatique et d'ingénierie rapide, entre autres. Par exemple, les mots ou les caractères d'une phrase en anglais peuvent être segmentés en plusieurs tokens. C'est le codage positionnel dans l'IA générative qui détermine l'emplacement des tokens dans cette séquence textuelle.
La taille de la fenêtre contextuelle correspond au nombre de tokens précédant et suivant un mot ou un caractère spécifique (le token cible) et détermine les limites dans lesquelles l'IA reste efficace. La taille de la fenêtre contextuelle intègre un ensemble d'invites utilisateur et de réponses IA issues de l'historique récent de l'utilisateur. Cependant, l'IA ne peut pas accéder à un historique de données qui se trouve en dehors de la taille de fenêtre contextuelle définie et génère alors des résultats incomplets et inexacts.
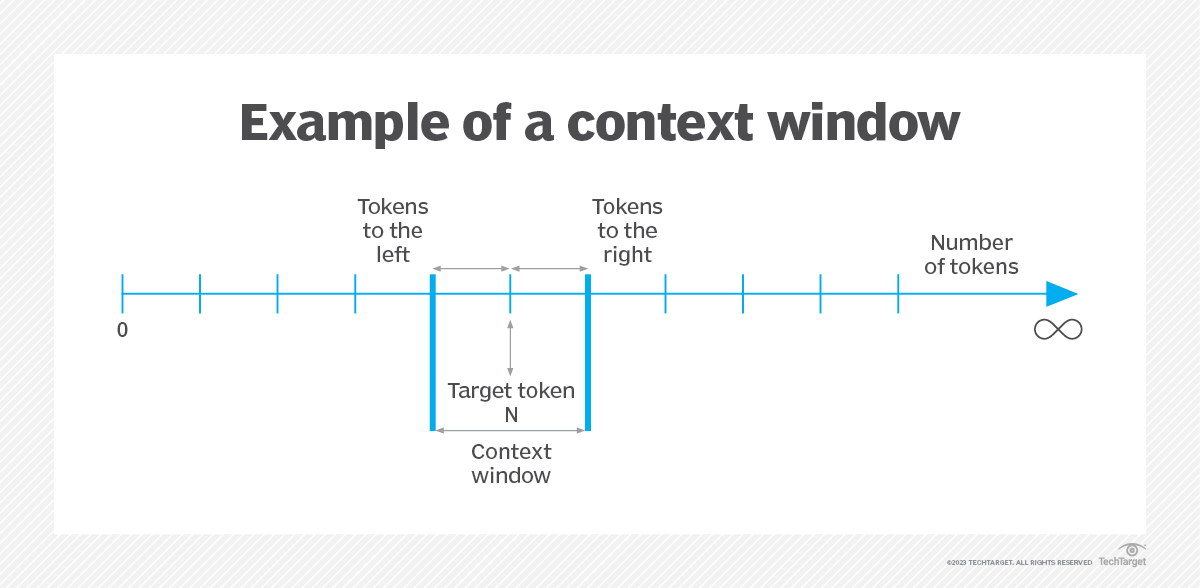
De plus, l'IA interprète les jetons en fonction de la longueur du contexte afin de créer de nouvelles réponses à la saisie actuelle de l'utilisateur ou au jeton cible saisi.
Pourquoi les fenêtres contextuelles sont-elles importantes dans les grands modèles linguistiques ?
Une fenêtre contextuelle est un facteur essentiel pour évaluer les performances et déterminer les applications futures des LLM. La capacité à fournir des réponses rapides et pertinentes en fonction des tokens entourant la cible dans l'historique du texte est un indicateur des performances du modèle. Une limite de tokens élevée indique un niveau d'intelligence supérieur et des capacités de traitement de données plus importantes.
Les fenêtres contextuelles peuvent définir des limites de texte pour les réponses intelligentes de l'IA, évitant ainsi les réponses trop longues et générant systématiquement des textes dans un langage lisible. L'outil d'IA génère chaque réponse dans le cadre des paramètres définis, contribuant ainsi à une conversation en temps réel.
De même, une fenêtre contextuelle vérifie à la fois à gauche et à droite du token cible dans le texte, et l'outil d'IA identifie et cible les ensembles de données entourant le token cible. Cela élimine les vérifications inutiles dans l'historique des conversations et ne fournit que les réponses pertinentes.
Avantages des grandes fenêtres contextuelles
Les fenêtres contextuelles de grande taille présentent plusieurs avantages. Parmi les plus notables, on peut citer les suivants :
- Gain de temps. L'outil d'IA générative identifie précisément les ensembles de données situés de part et d'autre du token cible, évitant ainsi les données non pertinentes par rapport au token cible saisi. En effet, une fenêtre contextuelle bien définie, en particulier une fenêtre contextuelle plus large, peut accélérer les opérations.
- Accepte des entrées volumineuses. Une fenêtre contextuelle volumineuse est un indicateur fort de la capacité sémantique des LLM à gérer les jetons. Les LLM prennent en charge les recherches linguistiques dans la base de données vectorielle à l'aide d'intégrations de mots, générant finalement des réponses pertinentes grâce à une compréhension des termes liés au jeton cible.
- Fournit une analyse détaillée. Une fenêtre contextuelle s'affiche à gauche et à droite du token cible pour analyser les données en profondeur. Le placement des scores d'importance permet de résumer l'ensemble d'un document. L'examen minutieux de nombreux tokens stimule la recherche, l'apprentissage et les opérations d'entreprise basées sur l'IA.
- Permet l'ajustement des jetons. L'encodeur-décodeur des LLM utilise des mécanismes tels que les « têtes d'attention » pour mieux comprendre les dépendances contextuelles. Dans les cas d'utilisation où le contexte est long, un LLM peut se concentrer de manière sélective sur la partie pertinente du jeton cible afin d'éviter les réponses superflues. En effet, l'optimisation de l'utilisation des jetons garantit un traitement rapide des textes longs tout en identifiant et en préservant leur pertinence.
Comparaison des tailles des fenêtres contextuelles des principaux LLM
Il existe différentes tailles de fenêtre contextuelle pour les différents LLM, telles que les suivantes :
- GPT-3. Generative Pre-trained Transformer (GPT) est un modèle linguistique de grande taille pour ChatGPT d'OpenAI. La taille de la fenêtre contextuelle pour GPT-3 est de 2049 tokens. Tous les modèles GPT sont entraînés jusqu'en septembre 2021.
- GPT-3.5-turbo. Le GPT-3.5-turbo d'OpenAI dispose d'une fenêtre contextuelle de 4 097 tokens. Une autre version, le GPT-3.5-16k, peut traiter un plus grand nombre de tokens ; il a une limite de 16 385 tokens.
- GPT-4. Le GPT-4 dans ChatGPT, doté d'une capacité de réglage fin, offre une fenêtre contextuelle pouvant contenir jusqu'à 8 192 tokens. Le GPT-4-32k dispose d'une fenêtre contextuelle plus grande pouvant contenir jusqu'à 32 768 tokens.
- Claude. L'outil d'IA Claude d'Anthropic offre une limite de jetons d'environ 9 000. Claude est en phase bêta et l'API est disponible pour un nombre limité d'utilisateurs en temps réel.
- Claude 2. Anthropic a annoncé que Claude 2 offre une fenêtre contextuelle plus large pouvant contenir jusqu'à 100 000 tokens. Les utilisateurs peuvent saisir un document entier d'environ 75 000 mots dans une seule invite pour l'API Claude 2.
- Grand modèle linguistique Meta AI (Llama). Meta AI a annoncé une famille open source de LLM appelée Llama. Tous les modèles Llama sont entraînés sur une fenêtre contextuelle de 16 000 caractères. Selon ArXiv, la famille Llama offre plus de 100 000 jetons.
Critiques à l'égard des fenêtres contextuelles de grande taille
Il y a certains points à prendre en considération avec les fenêtres contextuelles de grande taille, notamment les suivants :
- La précision diminue. L'hallucination de l'IA est l'incapacité à distinguer les tokens dans les grandes fenêtres contextuelles. Une étude de Stanford montre que les performances de l'IA se dégradent avec les grands ensembles de données, fournissant des informations inexactes.
- Cela demande plus de temps et d'énergie. Les fenêtres contextuelles de grande taille fonctionnent sur de nombreux ensembles de données complexes, ce qui augmente le temps de réponse. Le temps moyen consacré à la saisie des données et à la génération des résultats nécessite une puissance de traitement plus importante et consomme plus d'électricité.
- Augmentation des coûts. Afin de garantir l'exactitude des informations dans des fenêtres contextuelles longues, les coûts de calcul des outils d'IA générative sont multipliés par quatre. L'augmentation des prix est une conséquence directe de l'allongement des fenêtres contextuelles.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
GPT-5.5 : les promesses d’OpenAI contredites par les premiers retours
Par: Gaétan Raoul
-
![]()
GPT-5.4 nano, mini, Astral : OpenAI s’équipe face à la montée en régime de Claude Code
Par: Gaétan Raoul
-
![]()
Gemini 3.1 Pro : Google, leader en raisonnement, à la traîne en IA agentique
Par: Gaétan Raoul
-
![]()
GPT-5.3 Codex vs Claude Opus 4.6 : Anthropic et OpenAI jouent au jeu des 7 différences
Par: Gaétan Raoul



