Qu'est-ce que la détection d'anomalies ? Présentation et explication

La détection d'anomalies consiste à identifier les points de données, les entités ou les événements qui sortent de la norme. Une anomalie est tout ce qui s'écarte de la norme ou de ce qui est attendu. Les êtres humains et les animaux le font habituellement lorsqu'ils repèrent un fruit mûr dans un arbre ou un bruissement dans l'herbe qui se détache de l'arrière-plan et pourrait représenter une opportunité ou une menace. Ainsi, ce concept est parfois qualifié de détection d'aberrations ou de détection de nouveautés.
La détection des anomalies a une longue histoire dans le domaine des statistiques, grâce aux analystes et aux scientifiques qui ont étudié minutieusement les graphiques afin d'y trouver des éléments qui sortaient du lot. Au cours des dernières décennies, les chercheurs ont commencé à automatiser ce processus à l'aide de techniques d'apprentissage automatique conçues pour trouver des moyens plus efficaces de détecter différents types d'aberrations.
Dans la pratique, la détection d'anomalies est souvent utilisée pour détecter des événements suspects, des opportunités inattendues ou des données erronées enfouies dans des séries chronologiques. Un événement suspect peut indiquer une violation du réseau, une fraude, un crime, une maladie ou un équipement défectueux. Une opportunité inattendue peut consister à trouver un magasin, un produit ou un vendeur qui obtient de bien meilleurs résultats que les autres et qui mérite d'être étudié afin d'améliorer l'activité.
Une anomalie peut également résulter d'un équipement défectueux, de capteurs cassés ou d'un réseau déconnecté. Dans ces cas, un data scientist peut souhaiter supprimer les enregistrements de données anormaux de l'analyse ultérieure afin de ne pas compromettre le développement de nouveaux algorithmes.
Comment fonctionne la détection des anomalies ?
Il existe plusieurs façons d'entraîner les algorithmes d'apprentissage automatique à détecter les anomalies. Les techniques d'apprentissage automatique supervisé sont utilisées lorsque vous disposez d'un ensemble de données étiquetées indiquant les conditions normales par rapport aux conditions anormales. Par exemple, une banque ou une société de carte de crédit peut développer un processus pour étiqueter les transactions frauduleuses par carte de crédit après que ces transactions ont été signalées. De la même manière, les chercheurs médicaux peuvent étiqueter des images ou des ensembles de données indiquant un diagnostic de maladie future. Dans de tels cas, les modèles d'apprentissage automatique supervisé peuvent être entraînés à détecter ces anomalies connues.
Les chercheurs peuvent commencer par examiner certaines valeurs aberrantes déjà identifiées, mais soupçonnent l'existence d'autres anomalies. Dans le cas de transactions frauduleuses par carte de crédit, les consommateurs peuvent omettre de signaler des transactions suspectes dont les noms semblent anodins et dont la valeur est faible. Un data scientist peut utiliser des rapports incluant ce type de transactions frauduleuses pour classer automatiquement d'autres transactions similaires comme frauduleuses, à l'aide de techniques d'apprentissage automatique semi-supervisées.
Techniques de détection des anomalies supervisées et non supervisées
Les techniques supervisées et semi-supervisées ne peuvent détecter que les anomalies connues. Cependant, la grande majorité des données ne sont pas étiquetées. Dans ces cas, les scientifiques des données peuvent utiliser des techniques de détection d'anomalies non supervisées, qui permettent d'identifier automatiquement les événements exceptionnels ou rares.
Par exemple, un estimateur de coûts cloud pourrait rechercher des augmentations inhabituelles des frais de sortie de données ou des coûts de traitement qui pourraient être causés par un algorithme mal écrit. De même, un algorithme de détection d'intrusion pourrait rechercher de nouveaux modèles de trafic réseau ou une augmentation des demandes d'authentification. Dans les deux cas, des techniques d'apprentissage automatique non supervisées pourraient être utilisées pour identifier les points de données indiquant des éléments qui sortent largement du cadre d'un comportement normal. En revanche, les techniques supervisées devraient être explicitement entraînées à l'aide d'exemples de comportements déviants connus auparavant.
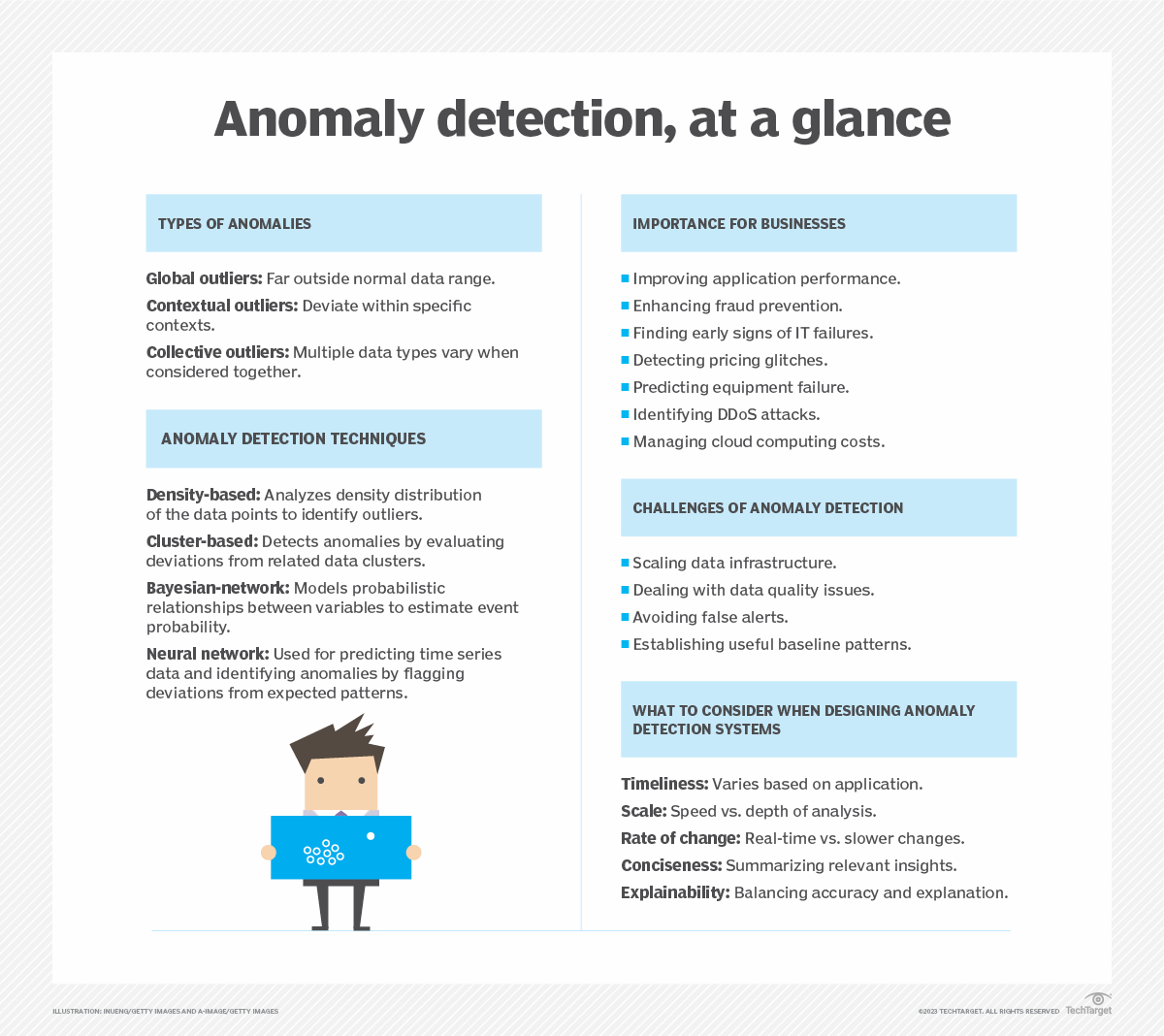
Différents types d'anomalies
De manière générale, il existe trois types d'anomalies.
- Les valeurs aberrantes globales, ou anomalies ponctuelles, se situent bien en dehors de la plage du reste d'un ensemble de données.
- Les valeurs aberrantes contextuelles s'écartent des autres points dans le même contexte, par exemple les ventes pendant les vacances ou les week-ends.
- Les valeurs aberrantes collectives se produisent lorsqu'un ensemble de données de types différents varie lorsqu'il est considéré dans son ensemble, par exemple les ventes de crème glacée et les pics de température.
Techniques de détection des anomalies
De nombreux types d'algorithmes d'apprentissage automatique peuvent être entraînés pour détecter les anomalies. Parmi les méthodes de détection d'anomalies les plus courantes, on peut citer les suivantes :
- Les algorithmes basés sur la densité déterminent quand une valeur aberrante diffère d'un ensemble de données normal plus grand, donc plus dense, à l'aide d'algorithmes tels que K-nearest neighbor et Isolation Forest.
- Les algorithmes basés sur les clusters évaluent dans quelle mesure un point donné diffère des clusters de données associées à l'aide de techniques telles que l'analyse par clusters K-means.
- Les algorithmes de réseau bayésien développent des modèles permettant d'estimer la probabilité que des événements se produisent à partir de données connexes, puis d'identifier les écarts significatifs par rapport à ces prévisions.
- Les algorithmes de réseau neuronal entraînent un réseau neuronal à prédire une série chronologique attendue, puis signalent les écarts.
Pourquoi la détection des anomalies est-elle importante pour les entreprises ?
Les systèmes de détection des anomalies peuvent être utilisés de différentes manières pour améliorer les performances commerciales, informatiques et applicatives. Ces systèmes peuvent également améliorer la détection des fraudes, des incidents de sécurité et des opportunités d'innovation. Voici quelques autres cas d'utilisation courants de la détection des anomalies :
- Prévision des pannes d'équipement.
- Détection des premiers signes de défaillances informatiques imminentes.
- Détection des anomalies de prix.
- Prévention améliorée contre la fraude.
- Identification des attaques DDoS.
- Identifier les magasins et les produits qui obtiennent des résultats supérieurs aux prévisions.
- Meilleure qualité des produits.
- Expérience utilisateur améliorée.
- Gestion des coûts liés au cloud.
Applications et exemples de détection d'anomalies
- Dans la gestion des coûts liés au cloud, la détection des anomalies pourrait rechercher des changements soudains dans l'utilisation des ressources, tels qu'une augmentation des appels à la base de données, des pics dans les frais de sortie ou une augmentation des frais SaaS. Cela pourrait aider les responsables à déterminer si cette augmentation est due à la sortie d'une nouvelle version d'une application, à une faille de sécurité ou au lancement réussi d'un produit.
- En matière de cybersécurité, la détection des anomalies permet d'évaluer des milliers de flux de données afin de détecter les changements dans les demandes d'accès, l'augmentation des échecs d'authentification ou les nouveaux modèles de trafic qui méritent d'être examinés de plus près. La détection des anomalies est souvent intégrée à la plupart des appareils et services de sécurité destinés aux systèmes de détection d'intrusion, aux pare-feu d'applications web et aux outils de sécurité API.
- Les outils de gestion des performances applicatives surveillent généralement les journaux de tout le trafic afin d'identifier les problèmes de performances ou les défaillances. Dans ces cas, la détection des anomalies leur permet de détecter de nouveaux problèmes qui n'auraient pas été identifiés avec les approches d'analyse traditionnelles basées sur des règles.
- Dans le secteur bancaire et financier, la détection des anomalies est couramment utilisée pour identifier les fraudes en corrélant des facteurs tels que le montant des transactions, l'heure, le lieu et le taux de dépenses. Par exemple, des transactions d'un montant suspect dans un pays étranger peuvent être signalées. De même, un nombre suspect de petites transactions provenant d'un nouveau fournisseur peut faire l'objet d'une enquête.
Les défis liés à la détection des anomalies
Les défis liés à la détection des anomalies sont les suivants :
- L'infrastructure de données doit être dimensionnée pour prendre en charge les anomalies utiles.
- Les problèmes liés à la qualité des données peuvent réduire les performances de la détection des anomalies.
- Des algorithmes de détection d'anomalies médiocres peuvent inonder les utilisateurs de fausses alertes.
- Il peut falloir beaucoup de temps pour établir une base de référence utile qui tienne compte des tendances normales telles que les ventes pendant les fêtes, les vagues de chaleur ou d'autres événements normaux qui se produisent moins fréquemment.
Considérations relatives à la conception d'un système efficace de détection des anomalies
Les scientifiques des données, les responsables informatiques, les responsables de la sécurité et les équipes commerciales doivent tenir compte de plusieurs aspects lors de la conception d'applications de détection des anomalies afin d'offrir la valeur ajoutée appropriée.
- Rapidité. Quel est le délai nécessaire pour obtenir de la valeur ajoutée ? Un système de détection des fraudes doit fonctionner en quelques secondes, un système de sécurité en quelques minutes, tandis qu'une application d'analyse des tendances commerciales peut apporter de la valeur ajoutée grâce à des mises à jour quotidiennes.
- Échelle. L'objectif est-il la rapidité ou la profondeur de l'analyse ? L'analyse de quelques indicateurs peut donner des résultats rapides, mais une analyse plus approfondie peut nécessiter des milliers, voire des millions de flux de données.
- Taux de changement. À quelle vitesse les événements analysés dans les données changent-ils ? Les applications de maintenance prédictive peuvent avoir besoin d'analyser des flux de données en temps réel, tandis que les données commerciales ont tendance à changer plus lentement.
- Concis. Existe-t-il un meilleur moyen de résumer les informations pertinentes pour les décideurs ?
- Définition des incidents. Comment automatiser le processus d'étiquetage des types d'anomalies connexes afin de déterminer les causes profondes et les réponses appropriées ?
- Explicabilité. Suffit-il de déterminer si un événement anormal s'est produit, ou faut-il donner la priorité aux algorithmes capables d'expliquer les facteurs contributifs, même s'ils ne sont pas aussi précis ?
Outils et logiciels de détection des anomalies
La détection des anomalies est généralement intégrée dans la plupart des systèmes et applications modernes de sécurité, de gestion informatique et de détection des fraudes. Cependant, les entreprises qui souhaitent développer leurs propres algorithmes de détection des anomalies peuvent se tourner vers des outils et des progiciels populaires dans les domaines des statistiques, de la science des données et des mathématiques. Voici quelques exemples parmi les plus courants :
- Anodot, une plateforme de surveillance des activités qui permet de détecter les anomalies dans les événements commerciaux et cloud.
- Amazon SageMaker, une plateforme de science des données qui prend en charge la détection des anomalies.
- ELKI, un outil open source d'exploration de données.
- Service Microsoft AI Anomaly Detector pour Azure.
- PyOD, une bibliothèque open source de détection d'anomalies écrite en Python.
- Scikit-learn, une bibliothèque populaire dédiée à la science des données qui prend en charge la détection des anomalies.
- Wolfram Mathematica, un outil de développement d'algorithmes qui prend en charge la détection des anomalies.
Comment personnaliser la stratégie de détection des anomalies de votre entreprise
La détection des anomalies est une tâche complexe. Tester de nouveaux outils pour détecter les anomalies est une chose. Mais dans la pratique, il n'est pas facile de détecter de manière fiable les anomalies importantes sans inonder les utilisateurs de faux positifs.
Dans la plupart des cas, il sera probablement plus facile d'utiliser des outils spécifiques à un domaine, dotés de capacités intégrées de détection des anomalies, pour des applications telles que la gestion des coûts du cloud, la gestion des services informatiques ou la détection des fraudes.
Le développement sur mesure de systèmes de détection des anomalies est plus pertinent pour les entreprises qui souhaitent ajouter des capacités de détection des anomalies à leurs propres produits et services. Dans ces cas, il est judicieux de tirer parti des plateformes open source et propriétaires de science des données telles que scikit-learn ou Mathematica.






