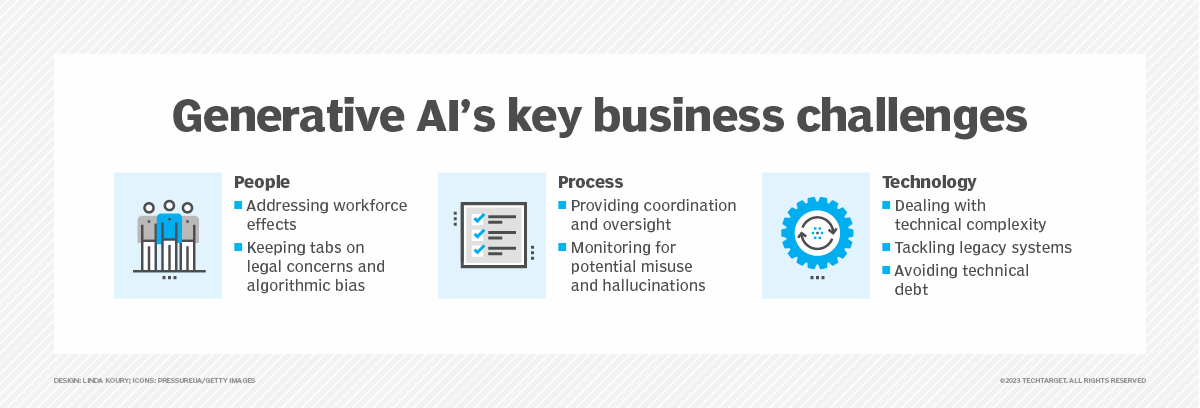
Que sont les hallucinations de l'IA et pourquoi constituent-elles un problème ?
Une hallucination IA se produit lorsqu'un modèle linguistique à grande échelle (LLM) alimentant un système d'intelligence artificielle (IA) génère des informations erronées ou des résultats trompeurs, conduisant souvent à des prises de décision humaines incorrectes.
Les hallucinations sont principalement associées aux modèles linguistiques à grande échelle (LLM), ce qui entraîne des résultats textuels incorrects. Cependant, elles peuvent également apparaître dans les vidéos, images et fichiers audio générés par l'IA. Un autre terme pour désigner une hallucination IA est la fabulation.
Les hallucinations de l'IA désignent les résultats faux, incorrects ou trompeurs générés par les modèles d'apprentissage automatique à grande échelle (LLM) ou les systèmes de vision par ordinateur. Elles sont généralement le résultat de l'utilisation d'un petit ensemble de données pour entraîner le modèle, ce qui entraîne des données d'entraînement insuffisantes ou des biais inhérents aux données d'entraînement. Quelle que soit la cause sous-jacente, les hallucinations peuvent être des écarts par rapport aux faits externes, à la logique contextuelle et, dans certains cas, aux deux. Elles peuvent aller de légères incohérences à des informations complètement inventées ou contradictoires. Les LLM sont des modèles d'IA qui alimentent les chatbots génératifs, tels que ChatGPT d'OpenAI, Microsoft Copilot ou Google Gemini (anciennement Bard), tandis que la vision par ordinateur désigne la technologie d'IA qui permet aux ordinateurs de comprendre et d'identifier le contenu des entrées visuelles telles que les images et les vidéos.
Les LLM utilisent des statistiques pour générer un langage grammaticalement et sémantiquement correct dans le contexte de la requête. Les LLM bien entraînés sont conçus pour produire des textes fluides, cohérents et pertinents par rapport au contexte en réponse à certaines entrées humaines. C'est pourquoi les hallucinations de l'IA semblent souvent plausibles, ce qui signifie que les utilisateurs peuvent ne pas se rendre compte que le résultat est incorrect, voire absurde. Ce manque de prise de conscience peut conduire à des décisions erronées.
Pourquoi les hallucinations de l'IA se produisent-elles ?
Tous les modèles d'IA, y compris les LLM, sont d'abord entraînés sur un ensemble de données. À mesure qu'ils consomment de plus en plus de données d'entraînement, ils apprennent à identifier des modèles et des relations au sein de ces données, ce qui leur permet ensuite de faire des prédictions et de produire des résultats en réponse à l'entrée d'un utilisateur (appelée « invite » ou « prompt »). Cependant, il arrive parfois que le LLM apprenne des modèles incorrects, ce qui peut conduire à des résultats erronés ou à des hallucinations.
Il existe de nombreuses raisons possibles pour expliquer les hallucinations dans les LLM, notamment les suivantes :
- Mauvaise qualité des données. Des hallucinations peuvent se produire lorsque les données utilisées pour entraîner le LLM contiennent des informations erronées, incorrectes ou incomplètes. Les LLM s'appuient sur un vaste ensemble de données d'entraînement pour produire des résultats pertinents et précis pour l'utilisateur qui a fourni la commande d'entrée. Cependant, ces données d'entraînement peuvent contenir du bruit, des erreurs, des biais ou des incohérences ; par conséquent, le LLM produit des résultats incorrects et, dans certains cas, complètement absurdes.
- Méthode de génération. Les hallucinations peuvent également provenir des méthodes d'entraînement et de génération utilisées, même lorsque l'ensemble de données lui-même est cohérent et fiable, et contient des données d'entraînement de haute qualité. Par exemple, les générations précédentes du modèle peuvent créer un biais ou le transformateur peut effectuer un décodage erroné, ce qui entraîne dans les deux cas une hallucination de la réponse du système. Les modèles peuvent également avoir un biais envers des mots génériques ou spécifiques, ce qui peut influencer les informations qu'ils génèrent ou les amener à fabriquer leur réponse.
- Contexte d'entrée. Si les instructions fournies par l'utilisateur humain sont floues, incohérentes ou contradictoires, des hallucinations peuvent apparaître. Bien que la qualité des données d'entraînement et les méthodes d'entraînement utilisées échappent au contrôle des utilisateurs, ceux-ci peuvent contrôler les entrées qu'ils fournissent au système d'IA. En affinant leurs entrées et en fournissant le bon contexte au système d'IA, ils peuvent l'amener à produire de meilleurs résultats.
Types d'hallucinations liées à l'IA
Il existe plusieurs types d'hallucinations liées à l'IA, notamment les suivantes :
- Contradiction dans les phrases. Cela se produit lorsqu'un LLM génère une phrase qui contredit une phrase précédente. Par exemple :
- Consigne : Décrivez un paysage à l'aide de phrases de quatre mots.
- Résultat : L'herbe était verte. Les montagnes étaient bleues. La rivière était violette. L'herbe était brune.
- Contradiction avec la consigne. Il s'agit d'une phrase qui contredit la consigne utilisée pour la générer. Par exemple :
- Consigne : Écrivez une carte d'anniversaire pour ma nièce.
- Résultat : Joyeux anniversaire, maman et papa !
- Contradiction factuelle. Il s'agit d'une situation où des informations fictives sont présentées comme des faits. Par exemple :
- Consigne : Citez trois villes des États-Unis.
- Sortie : New York, Londres, Toronto.
- Hallucinations non pertinentes ou aléatoires. Il s'agit de la génération d'informations aléatoires ayant peu ou pas de rapport avec l'entrée.
- Consigne : Décrivez-moi Londres.
- Résultat : Londres est une ville d'Angleterre. Les chats doivent être nourris au moins une fois par jour.
Exemples d'hallucinations de l'IA
Un exemple tristement célèbre d'hallucination de l'IA s'est produit en février 2023, lorsque le chatbot de Google, Gemini, a fait une déclaration erronée au sujet du télescope spatial James Webb (JWST). Dans une vidéo promotionnelle, Gemini a été interrogé : « Quelles nouvelles découvertes du télescope spatial James Webb puis-je raconter à mon enfant de 9 ans ? » Gemini a répondu que le JWST avait pris les toutes premières photos d'une exoplanète en dehors du système solaire terrestre. Cette information était fausse, car les premières images d'une exoplanète ont été prises en 2004 par le Very Large Telescope (VLT) de l'Observatoire européen austral, et le JWST n'a été lancé qu'en 2021. La réponse de Bard semblait plausible et correspondait à la question posée, mais elle a été signalée comme fausse par l'agence de presse Reuters.
Une autre hallucination de l'IA s'est produite fin 2022 lorsque Meta (anciennement Facebook) a présenté Galactica, un LLM open source formé à partir de millions d'informations scientifiques provenant de manuels, d'articles, d'encyclopédies, de sites web et même de notes de cours. Galactica a été conçu pour être utilisé par des chercheurs et des étudiants en sciences, dont beaucoup ont signalé que le système générait des résultats inexacts, suspects ou biaisés. Un professeur de l'université de New York a déclaré que Galactica n'avait pas réussi à résumer correctement ses travaux, tandis qu'un autre utilisateur a déclaré que le système avait inventé des citations et des recherches lorsqu'il lui avait demandé d'effectuer une revue de la littérature sur la question de savoir si le VIH causait le sida.
Ces problèmes ont suscité de nombreuses critiques, de nombreux utilisateurs qualifiant le LLM de Galactica et ses résultats de suspects, irresponsables et même dangereux. Ce problème peut avoir de graves conséquences pour les utilisateurs d'IA qui ne connaissent pas bien un sujet pour lequel ils comptent sur l'aide de Galactica. Suite à ce tollé, Meta a retiré la démo de Galactica trois jours seulement après son lancement.
Tout comme Google Gemini et Meta Galactica, ChatGPT d'OpenAI a également été impliqué dans de nombreuses controverses liées à des hallucinations depuis sa sortie publique en novembre 2022. En juin 2023, un animateur radio de Géorgie a intenté un procès en diffamation contre OpenAI, accusant le chatbot d'avoir tenu des propos malveillants et potentiellement diffamatoires à son égard. En février 2024, de nombreux utilisateurs de ChatGPT ont signalé que le chatbot avait tendance à passer d'une langue à l'autre ou à se bloquer dans des boucles. D'autres ont signalé qu'il générait des réponses incohérentes qui n'avaient rien à voir avec la demande de l'utilisateur.
En avril 2024, certains militants pour la protection de la vie privée ont déposé une plainte contre OpenAI, affirmant que le chatbot hallucinait régulièrement des informations sur les personnes. Les plaignants ont également accusé OpenAI de violer la réglementation européenne en matière de protection de la vie privée, le règlement général sur la protection des données (RGPD). Un mois plus tard, une journaliste travaillant pour le site d'actualités technologiques The Verge a publié un article hilarant dans lequel elle racontait comment ChatGPT lui avait affirmé sans équivoque qu'elle avait une barbe et qu'elle ne travaillait pas réellement pour The Verge.
Depuis que ces problèmes ont été signalés pour la première fois, ces entreprises ont soit corrigé les applications, soit travaillé à leur correction. Malgré cela, ces événements démontrent clairement une faiblesse importante des outils d'IA : ils peuvent générer des résultats indésirables qui pourraient entraîner des conséquences indésirables ou dangereuses pour les utilisateurs.
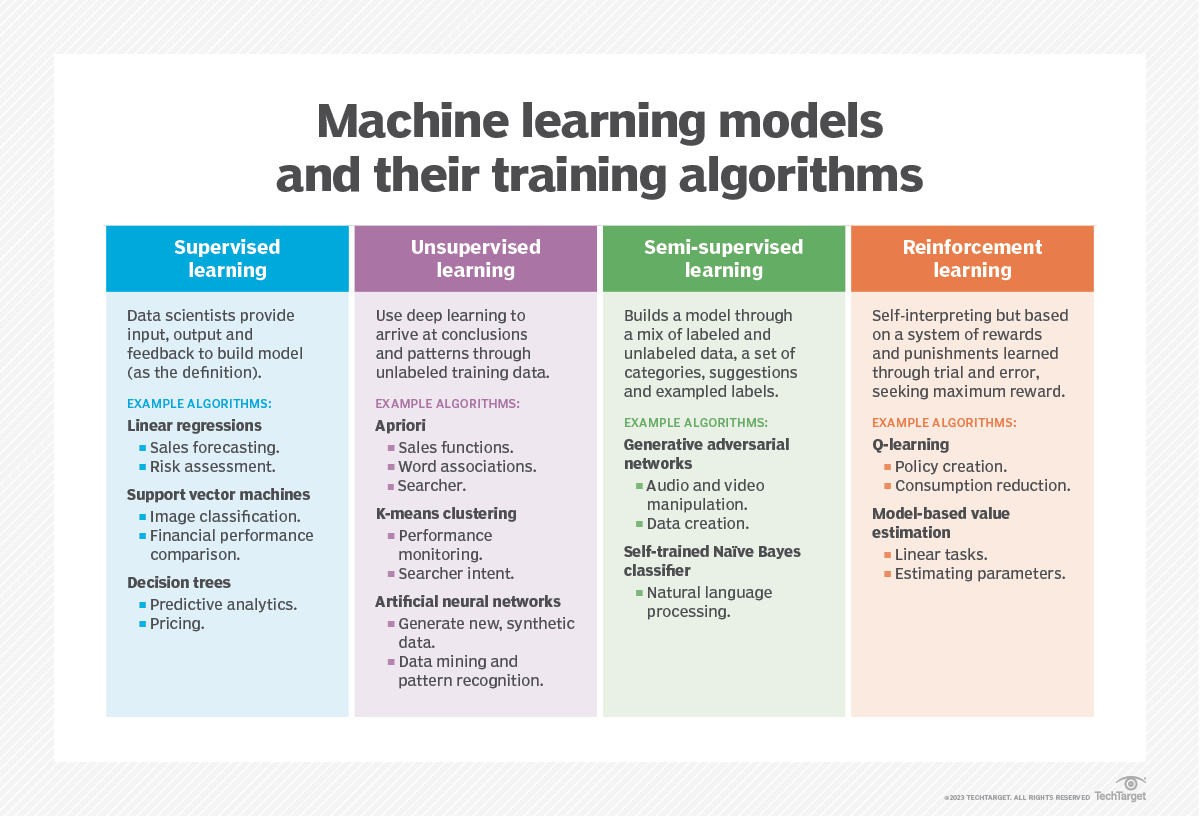
Pourquoi les hallucinations de l'IA posent-elles problème ?
Un problème immédiat lié aux hallucinations de l'IA est qu'elles sapent considérablement la confiance des utilisateurs. À mesure que les utilisateurs commencent à considérer l'IA comme un outil réel, ils peuvent développer une confiance plus inhérente à son égard. Les hallucinations peuvent éroder cette confiance et dissuader les utilisateurs de continuer à utiliser le système d'IA.
Les hallucinations peuvent également conduire à l'anthropomorphisme génératif, un phénomène dans lequel les utilisateurs humains perçoivent qu'un système d'IA possède des qualités humaines. Cela peut se produire lorsque les utilisateurs croient que les résultats générés par le système sont réels, même s'il génère des images représentant des scènes mythiques (irréelles) ou des textes qui défient la logique. En d'autres termes, les résultats du système sont comme un mirage qui manipule la perception des utilisateurs, les amenant à croire en quelque chose qui n'est pas réel, puis à utiliser cette croyance pour guider leurs décisions.
La capacité des hallucinations fluides et plausibles à tromper les gens peut être problématique ou dangereuse dans de nombreuses situations, en particulier si les utilisateurs sont optimistes et peu sceptiques. Le système d'IA pourrait involontairement diffuser des informations erronées pendant les élections, affectant leurs résultats ou même conduisant à des troubles sociaux. Les hallucinations pourraient même être utilisées comme arme par des cyberattaquants pour mener des cyberattaques graves contre des gouvernements ou des organisations.
Enfin, les LLM sont souvent des IA de type « boîte noire », ce qui rend difficile, voire impossible, de déterminer pourquoi le système d'IA a généré une hallucination spécifique. Il est également difficile de corriger les LLM qui produisent des hallucinations, car leur apprentissage s'arrête à un certain point. Modifier les données d'entraînement du modèle peut demander beaucoup d'énergie. De plus, l'infrastructure IA est coûteuse, ce qui rend la recherche de la cause profonde des hallucinations et la mise en œuvre de corrections très onéreuses. C'est souvent à l'utilisateur, et non au propriétaire du LLM, qu'il incombe de surveiller les hallucinations.
L'IA générative est justement cela : générative. Dans un certain sens, l'IA générative invente tout.
Comment détecter les hallucinations de l'IA ?
La manière la plus simple de détecter une hallucination de l'IA consiste à vérifier minutieusement les résultats fournis par le modèle. Cependant, cela peut s'avérer difficile pour les utilisateurs qui traitent des informations complexes, denses ou peu familières. Pour pallier ce problème, ils peuvent demander au modèle de s'auto-évaluer et de générer la probabilité qu'une réponse soit correcte ou de mettre en évidence les parties d'une réponse qui pourraient être erronées, puis d'utiliser ces informations comme point de départ pour vérifier les faits.
Les utilisateurs peuvent également se familiariser avec les sources d'information du modèle afin de les aider à vérifier les faits. Par exemple, si les données d'entraînement d'un outil s'arrêtent à une certaine année, toute réponse générée qui s'appuie sur des connaissances détaillées postérieures à cette date doit être vérifiée afin d'en garantir l'exactitude.
Comment prévenir les hallucinations de l'IA
Il existe plusieurs moyens pour les utilisateurs d'IA d'éviter ou de minimiser l'apparition d'hallucinations dans les systèmes d'IA :
- Utilisez des instructions claires et précises. Des instructions claires et sans ambiguïté, accompagnées d'informations contextuelles supplémentaires, peuvent guider le modèle afin qu'il fournisse le résultat souhaité et correct. Voici quelques exemples :
- Utilisation d'une invite (prompt) qui limite les résultats possibles en incluant des nombres spécifiques.
- Fournir au modèle des sources de données pertinentes et fiables.
- Attribuer un rôle spécifique au modèle, par exemple : « Vous êtes rédacteur pour un site web consacré à la technologie. Écrivez un article sur x. »
- Stratégies de filtrage et de classement. Les LLM ont souvent des paramètres que les utilisateurs peuvent régler. Le paramètre de température, qui contrôle le caractère aléatoire des résultats, en est un exemple. Lorsque la température est réglée à un niveau plus élevé, les résultats générés par le modèle linguistique sont plus aléatoires. Top-K, qui gère la manière dont le modèle traite les probabilités, est un autre exemple de paramètre pouvant être réglé afin de minimiser les hallucinations.
- Suggestions multiples. Les utilisateurs peuvent fournir plusieurs exemples du format de sortie souhaité afin d'aider le modèle à reconnaître avec précision les modèles et à générer une sortie plus précise.
C'est souvent à l'utilisateur, et non au propriétaire ou au développeur du LLM, qu'il revient de surveiller les hallucinations lors de l'utilisation du LLM et d'examiner les résultats du LLM avec un scepticisme approprié. Cela dit, les chercheurs et les développeurs de LLM s'efforcent également de comprendre et d'atténuer les hallucinations en utilisant des données d'entraînement de haute qualité, en utilisant des modèles de données prédéfinis et en précisant l'objectif, les limites et les limites de réponse du système d'IA.
Certaines entreprises adoptent également de nouvelles approches pour former leurs LLM. Par exemple, en mai 2023, OpenAI a annoncé avoir formé ses LLM à améliorer leur capacité à résoudre des problèmes mathématiques en récompensant les modèles pour chaque étape correcte du raisonnement menant à la bonne réponse, plutôt que de simplement récompenser la conclusion correcte. Cette approche, appelée « supervision du processus », vise à fournir un retour d'information précis au modèle à chaque étape individuelle afin de le manipuler pour qu'il suive une chaîne de pensée et produise ainsi de meilleurs résultats et moins d'hallucinations.
Histoire des hallucinations dans l'IA
Les chercheurs de Google DeepMind ont proposé le terme « hallucinations informatiques » en 2018. Ils ont décrit les hallucinations comme « des traductions hautement pathologiques qui sont complètement déconnectées du matériel source ». Le terme est devenu plus populaire et associé à l'IA avec la sortie de ChatGPT, qui a rendu les LLM plus accessibles, mais a également mis en évidence la tendance des LLM à générer des résultats incorrects.
Un rapport publié en 2022 intitulé « Survey of Hallucination in Natural Language Generation » (Enquête sur les hallucinations dans la génération de langage naturel) décrit comment les systèmes basés sur l'apprentissage profond sont susceptibles d' « halluciner des textes non intentionnels », ce qui affecte leurs performances dans des scénarios réels. Les auteurs de l'article mentionnent que le terme « hallucination » a été utilisé pour la première fois en 2000 dans un article intitulé « Proceedings: Fourth IEEE International Conference on Automatic Face and Gesture Recognition » (Actes : quatrième conférence internationale IEEE sur la reconnaissance automatique des visages et des gestes), où il avait une connotation positive dans le domaine de la vision par ordinateur, contrairement à la connotation négative qu'il a aujourd'hui.
ChatGPT a été pour beaucoup l'occasion de découvrir l'IA générative. Plongez-vous dans l'histoire de l'IA générative, qui s'étend sur plus de neuf décennies. Lisez également notre petit guide sur la gestion des hallucinations de l'IA générative, découvrez les étapes de la vérification des faits dans les contenus générés par l'IA et apprenez à élaborer une stratégie responsable en matière d'IA générative. Découvrez les meilleurs LLM, les compétences nécessaires pour devenir ingénieur en prompt engineering et les meilleures pratiques en la matière.





