
Avec DataMC, Ippon veut industrialiser les déploiements de Cassandra, Spark et Kafka
DataMC propose plusieurs configurations de Cassandra optimisées pour des cas d’usage type du Big Data et pour les composants Open Source Spark, Kafka et Zeppelin. La plateforme propose aussi des capacités de déploiements distribués rapides.

Ippon Technologies a décidé de capitaliser sur son expertise dans la base de données Cassandra et dans les technologies Open Source du Big Data. Le prestataire de services français a annoncé la création d’un spin-off nommée DataMC (financée grâce à une levée de fonds de 500 00 euros) qui servira de havre de paix à une nouvelle plateforme mise au point par la société (qui répond elle-aussi au nom de DataMC). Son objectif : pré-cabler et pré-configurer, par typologies d’usag,e des solutions clés du Big Data, comme Spark, Kafka, Zeppelin et bien sûr Cassandra, et de les faire tourner sur un socle bâti sur une architecture en conteneurs pour en faciliter le déploiement. Le tout dans une solution pré-packagée et managée, qui peut se déployer aussi bien dans sur Cloud public que sur un Cloud privé.
La création de cette solution a été motivée par plusieurs constats, résume en substance Julien Dubois, directeur de l’innovation chez Ippon Technologies. Si ces outils Open Source sont au cœur des stacks Big Data dans les entreprises, il apparait qu’elles sont plutôt complexes à configurer et à déployer en cluster. DataMC, explique-t-il, propose dont différents stacks centrés sur les usages, auxquels ont été associées des configuration spécifiques et adaptées de Cassandra -une base de données dite NoSQL reconnue sur le marché pour sa capacité à gérer de grands volumes de données.
« Ces composants ne sont pas faciles à mettre en production », poursuit-il. Ippon entend donc miser sur son expérience dans l’intégration de ces composants dans les entreprises, pour proposer une solution où « l’intégration est déjà pré-câblée, et ce avec un monitoring commun et centralisé ». Il s’agit de faire fonctionner de pair ces briques essentielles que sont Spark, Kafka et Zeppelin aux côtés de Cassandra et de mâcher le travail des entreprises en proposant leurs configurations optimisées.
4 solutions calées sur les usages
Assis sur un socle Open Source Blackfish, qui s’adosse à Docker et Swarm, DataMC distille ces composants en 4 piliers pré-câblés : Apps Stack, une Cassandra hébergée et optimisée pour la haute disponibilité ; IoT Stack, une configuration de Cassandra « optimisée pour le stockage en masse des événements IoT couplée dans le Cloud à des disques SSD haute performance », explique Ippon ; Streaming Stack qui associe Spark à Kafka ; et enfin Analytic Stack qui couple Spark à Zeppelin pour réaliser des traitements distribués sur grands clusters.
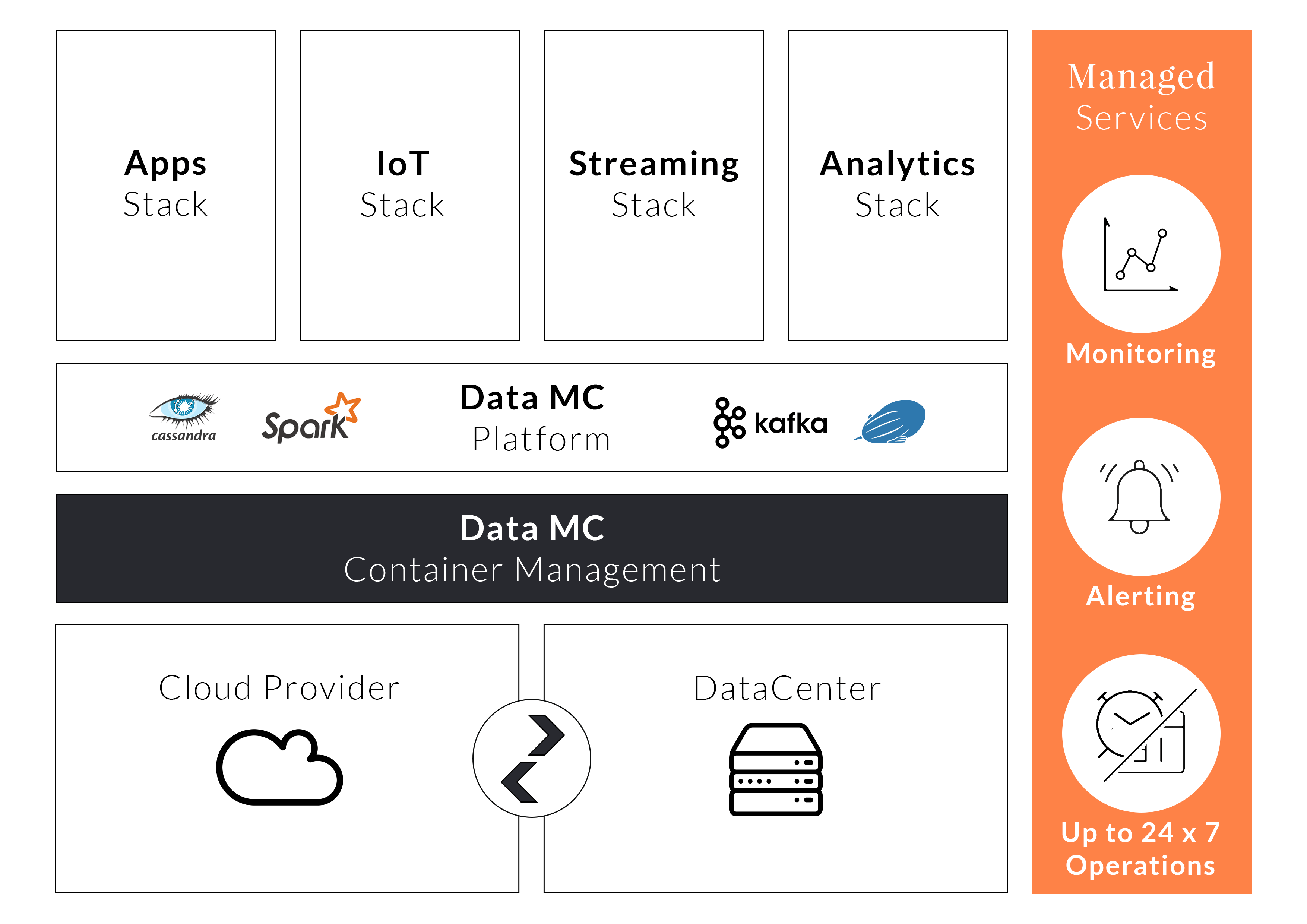
« L’utilisateur installe les stacks dont ils ont besoin ; chaque stack peut être adapté en fonction des besoins et les ajouter à la volée », précise-t-il. Cette capacité de provisioning et de dé-provisioning, et de mise en place accélérée de cluster est rendu possible par ce socle bâti sur les conteneurs.
Logiquement, et c’est aussi là qu’est l’intérêt de cette plateforme, Ippon a développé d’autres composants dont la vocation est de proposer une console d’administration et de monitoring centrale pour gérer les déploiements et l’ensemble des stacks. Ce qui jusqu’alors était plutôt compliqué, soutient encore Julien Dubois. Des travaux autour de l’intégration de Spark à Cassandra ont également été réalisés ainsi qu’autour d’un système d’alertes - utile en cas de plantage.
Pour l’heure en béta test, la plateforme DataMC sera commercialisée courant 2017 sous la forme d’un abonnement mensuel de services managés qui comprend un support 24/7 par les équipes de DataMC.
Pour approfondir sur Base de données
-
![]()
DataStax Astra : une nouvelle étoile dans la galaxie DbaaS
Par: Gaétan Raoul
-
![]()
AIOps : Dynatrace ajuste sa plateforme pour surveiller les infrastructures cloud
Par: Gaétan Raoul
-
![]()
DataStax présente une offre de support pour Cassandra
Par: Cyrille Chausson
-
![]()
DataStax veut facturer à la seconde son cloud managé
Par: Cyrille Chausson



