HortonWorks place Yarn au cœur de sa distribution Hadoop.
Pour HortonWorks, Hadoop est en passe de s’imposer comme une plate-forme universelle de traitement de données grâce à l’arrivée de Yarn, présente comme un « Data Operating System ».

A l’occasion du dernier IT Press Tour, LeMagIT a pu rencontrer le Président d’HortonWorks, Herb Cunitz, et son vice-président en charge de la gestion produit, Tim Hall, pour faire le point sur la stratégie de la firme mais aussi sur sa dernière distribution Hadoop, HDP 2.1.
Fondée en 2011 par l’équipe Hadoop de Yahoo, HortonWorks compte Aujourd’hui plus de 300 clients parmi lesquels Yahoo, bien sûr (environ 32000 nœuds sur plusieurs clusters), Spotify (1000 nœuds), Samsung (400 nœuds), mais aussi eBay, EDF, Expedia, Macy’s ou Paypal. Spotify est de l’aveu même de la firme son principal client en Europe, tandis qu’EDF R & D utilise la distribution de la firme pour des prévisions de consommation mais aussi pour l’analyse de l’e-reputation de l’électricien.
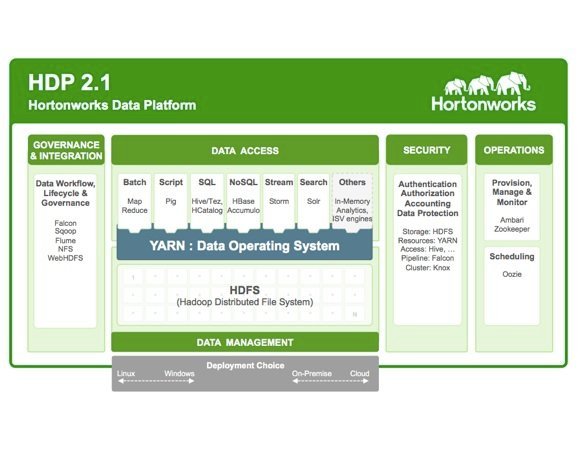
Architecture d'HDP 2.1
Herb Cunitz a insisté sur l’engagement open-source d’HortonWorks, un engagement qui le différencie de ses concurrents MapR et Cloudera qui tous deux ajoutent au cœur open-source d’Hadoop des modules propriétaires (comme le file system pour MapR ou Impala pour Cloudera). Cet engagement permet à la firme d’être alignée avec la version open source et de suivre de très près ses évolutions. Une centaine des quelque 400 employés de la firme sont ainsi des contributeurs au projet Apache Hadoop, ce qui fait d’HortonWorks le principal contributeur au projet.
Pour Herb Cunitz, Hadoop est en passe de s’imposer comme une plate-forme universelle de traitement de données grâce à l’arrivée de Yarn que la firme présente comme un « Data Operating System ». Yarn, au développement duquel HortonWorks a beaucoup contribué a pour objectif de servir de courroie de transmission entre le lac de données stockées sur le système de fichier HDFS et les différents moteurs de traitement d’Hadoop.
Les différents moteurs analytiques comme Mapreduce, Pig, Hive, et Hbase tournent désormais au-dessus de Yarn et Hortonworks a récemment validé Storm et le moteur de recherche Solr au-dessus de Yarn. Le dernier arrivé est le framework in-memory Spark qu’Hortonworks a qualifié sur Yarn le 26 juin et qui permet d’apporter à Hadoop des capacités de traitement en quasi-temps-réel. Des travaux sont aussi en cours autour d’Hive et de Spark pour réimplémenter Hive au-dessus de Spark et doper ainsi ses performances.
Pour approfondir sur Big Data et Data lake
-
![]()
Big Data : Cloudera désormais dirigé par un ex d’Hortonworks spécialiste des fusions
Par: Sean Kerner
-
![]()
MapR se vend à HPE : vers l’hiver des pure-players du Big Data
Par: Brian McKenna
-
![]()
Cloudera et Hortonworks font désormais front commun dans une fusion de 5,2 Md de dollars
Par: Cyrille Chausson
-
![]()
Hadoop : à son tour, IBM se range derrière Hortonworks
Par: Cyrille Chausson



