
Warakorn - Fotolia
DSS 7.0 : Dataiku veut rapprocher les statisticiens des data scientists
L’éditeur français de la plateforme de data science DSS a annoncé la disponibilité de la version 7.0. Cette mise à jour majeure doit renforcer les fonctionnalités dédiées aux statisticiens et à l’explicabilité des modèles.

Après la version 6.0 publiée en décembre 2019, Dataiku annoncé sa dernière mise à jour majeure en date pour sa plateforme Data Science Studio (corrigée depuis en 7.0.1).
Encore une fois l’éditeur français met l’accent sur l’explicabilité des modèles. « Nous voulons que les utilisateurs puissent expliquer ce que font les modèles et pouvoir décrire aux organismes de conformité leur fonctionnalité et les résultats obtenus », explique Ludovic Blusseau, responsable avant-vente Europe du Sud chez Dataiku.
Cette volonté de transparence émergeait déjà dans la version 6.0. « La 6.0 permettait d’obtenir une description globale d’un modèle. Avec la 7.0 nous sommes au niveau de l’enregistrement », ajoute notre interlocuteur.
La transparence des algorithmes, toujours au cœur de la démarche de Dataiku
Pour apporter ce niveau d’interprétabilité, DSS dispose de deux méthodes de calcul : l’ICE (explications conditionnelles personnalisées) ou la valeur de Shapley.
Elles permettent d’obtenir des informations visuelles sur des modèles conçus à l’aide de Python, mais ne sont pas compatibles avec les modèles Keras ou TensorFlow.
« Dans l’écran des résultats du modèle, vous pouvez directement consulter les explications des prédictions “les plus extrêmes” sur le jeu de test. Vous pouvez également calculer des explications sur un jeu de données complet dans la “scoring recipe” », peut-on lire dans la documentation.
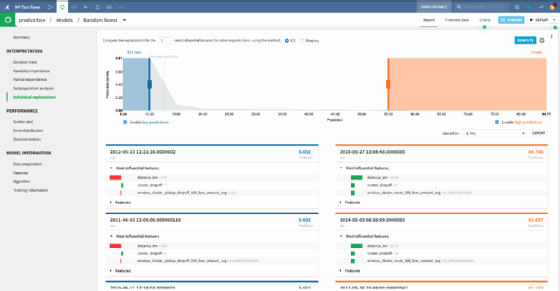
La méthode basée sur la formule mathématique nommée valeur de Shapley, estime l’impact moyen sur la prédiction du changement d’une valeur caractéristique sélectionnée à partir d’un échantillon aléatoire, par la valeur dans l’échantillon à expliquer après un nombre de répétitions aléatoires de cette opération.
L’ICE repose sur une simplification de la valeur de Shapley. « Cette méthode explique l’impact d’une caractéristique sur une prédiction de sortie en calculant la différence entre la prédiction et la moyenne des prédictions obtenues en changeant la valeur de la caractéristique de manière aléatoire » détaille la documentation de Dataiku. Celle-ci permet de tester un modèle plus rapidement que la valeur de Shapley, mais fonctionne mieux quand elle est appliquée sur les modèles linéaires.
Des fonctionnalités d’analyse visuelle pour les statisticiens
Les data scientists ne sont pas les seuls à bénéficier d’ajouts. Dataiku propose maintenant des solutions pour les statisticiens.
« Nous essayons d’intégrer des collaborateurs en provenance des statistiques. À cette fin, nous avons ajouté des fonctionnalités d’analyses et d’exploration visuelles de données », commente Ludovic Blusseau.
Ce que Dataiku a nommé statistiques interactives comprend un ensemble de fonctionnalités avancées pour réaliser diverses analyses visuelles liées aux statistiques descriptives, inférentielles et aux méthodes de réduction de la dimensionnalité. Cela peut aller de la production d’histogrammes, de tableaux de quantiles, en passant par des tests statistiques ou encore de matrices de corrélation multivariables.
Le responsable estime que les méthodes statistiques sont bien connues des clients de Dataiku. Il ne s’agit pas simplement d’attirer les statisticiens sur la plateforme, mais de les faire participer plus en profondeur aux projets de machine learning. « Avant de produire un modèle prédictif, il est préférable de savoir comment les données sont ventilées, comment elles sont structurées. C’est pour cette raison que nous ajoutons des fonctionnalités de statistiques », affirme Ludovic Blusseau.
« Nous voulons que Dataiku soit le centre de référence de tous les projets analytiques. Cela inclut beaucoup d’utilisateurs d’horizon différent », estime-t-il.
Les organisations ne disposent pas du même niveau d’expertise en data science. Certaines entreprises se reposent largement sur de la BI et des modèles statistiques. « Peut-être que certains clients ne sont pas aussi mûrs que les autres concernant des aspects de modélisation prédictive et de data science à proprement parler, mais nous leur apportons une courbe d’apprentissage. Nous les amenons à évoluer et à réaliser des projets de data science beaucoup plus complexes » vante Ludovic Blusseau.
Le responsable estime que les clients de Dataiku les plus avancés dans le domaine proviennent du e-commerce et de l’assurance. Les industriels qui cherchent à adopter la maintenance prédictive nécessitent « un peu plus d’accompagnement ».
Une meilleure gestion des versions de projets
« Nous voulons également renforcer les fonctionnalités de collaboration pour les développeurs et les data scientists ». C’est par cette phrase que le responsable avant-vente introduit la troisième fonctionnalité majeure de DSS 7.0, l’amélioration de l’intégration avec les dépôts Git.
Les équipes de data science peuvent extraire des changements depuis un dépôt distant (GitLab, GitHub, Bitbucket ou autres), créer plusieurs branches d’un même projet et travailler sur plusieurs versions simultanément, à la manière d’un MLFlow. Il est également possible de fusionner des projets. L’éditeur recommande aux développeurs un bon niveau de connaissances du fonctionnement des branches Git.
L’outil de contrôle de version permet de suivre toutes les actions effectuées dans DSS, d'obtenir un historique des objets, d’annuler des changements au sein d’un projet (jeux de données, applications, dashboards, etc.). Toutefois cette dernière fonctionnalité comporte des risques. Dataiku conseille de le faire pour des modifications mineures.
Les macros de DSS 7 doivent apporter davantage de contrôle sur la mise en place de projets. Cela permet d’automatiser le déploiement d’un environnement de développement, de configuration d’exécution de containers, de gestion des autorisations ou encore la création d’une base de données Hive. Après avoir installé les plugins nécessaires et paramétré le fichier JSON et le bout de code Python associé, les administrateurs peuvent ensuite déléguer les droits d’accès à ces macros qui doivent permettre de déployer plus rapidement les projets.
Kubernetes et Spark 2, des standards pour Dataiku
Dataiku a aussi renforcé la compatibilité de son outil avec Kubernetes. DSS permet maintenant de déployer des webapps « élastiques » à l’aide de l’orchestrateur. Les développeurs d’options d’exposition « plus avancées » pour les services API et les webapps ainsi que des améliorations pour la gestion des containers sur AKS (Azure) et EKS (AWS). Par ailleurs, la version 7.0 ajoute le support d’Hortonworks HDP 3.1.4.
« Nos clients expriment un besoin de scalabilité du nombre de projets, d’utilisateurs, de la volumétrie afin de pouvoir décentrer le traitement sur le cloud », affirme Ludovic Blusseau.
Cette nouvelle version de Data Science Studio entraîne également des arrêts de compatibilité. Comme promis, Dataiku déprécie le support de Spark 1.6 et préconise de passer à Spark 2 avant la montée en version de DSS 8. L’éditeur ne prendra bientôt plus en compte Microsoft HDInsight, Hive CLI, Apache Pig et Vertica Advanced Analytics.
« Microsoft a tendance à pousser d’autres solutions de calcul que HDInsight comme des versions de Spark managées. Nous souhaitons davantage nous intégrer avec ce type de technologies qui sont utilisées par nos clients », estime le responsable avant-vente.
Dataiku propose de piloter depuis son outil une version de Spark sur Kubernetes. Les clients peuvent aussi utiliser les services managés de Microsoft ou de Databricks. « Il est possible de déployer Databricks en dessous de Dataiku, mais nous ouvrons Databricks à des populations qui ne sont pas expertes en Spark », conclut Ludovic Blusseau.
Pour approfondir sur Outils décisionnels et analytiques
-
![]()
Dataiku entend centraliser la gestion des projets d’IA agentique
-
![]()
LLM Guard Services : Dataiku pose des garde-fous pour les projets d’IA générative
Par: Gaétan Raoul
-
![]()
Dataiku étend son écosystème LLM Mesh
Par: Gaétan Raoul
-
![]()
Data science : le Français Datategy lance sa plateforme en mode SaaS
Par: Gaétan Raoul



