Data lakes, data warehouses : la tentative de Google Cloud pour les unifier
Avec BigLake, Google Cloud entend proposer une solution pour gouverner et analyser les données en provenance de data warehouses et de data lakes répartis sur différents clouds depuis un seul environnement, BigQuery.
La fédération de requêtes n’était finalement qu’une première étape. Google Cloud a annoncé le 6 avril la préversion de BigLake. Le service est présenté comme un moyen d’unifier les lacs et entrepôts de données à travers plusieurs clouds. GCP deviendrait alors la console centrale d’accès et de sécurisation de ces environnements.
« BigLake apporte la dizaine d’années d’expérience que nous avons avec BigQuery aux autres data lakes », déclare Gerrit Kazmaier, Vice-président et directeur général, base de données, analytiques et Looker chez Google Cloud lors d’une conférence de presse. « Cela vous permet de combiner les performances, la gouvernance, le niveau d’accès et la sécurité avec des fichiers aux formats ouverts », vante-t-il.
Sudhir Hasbe, directeur principal de la gestion des produits chez Google Cloud, cerne davantage le problème. « Historiquement, toutes les données étaient emmagasinées dans différents systèmes de stockage, certaines dans des entrepôts, et ceux-ci offraient différentes capacités et créaient des silos de données au sein des organisations », affirme-t-il.
Ces silos reposant sur diverses technologies ne bénéficient pas du même niveau de gouvernance, selon le responsable. Un data warehouse peut apporter un contrôle d’accès fin permettant une gouvernance cohérente, mais un data lake, qui renferme des volumes de données beaucoup plus importants ne disposent pas forcément de ce mécanisme.
« Et comme les organisations sont de plus en plus conscientes des politiques de gouvernance [à déployer], nous devons aller de l’avant et avoir une certaine cohérence entre ces différentes plateformes et stratégies », indique Sudhir Ashbe.
BigLake : un moteur de stockage « unifié » biberonné à l’open source
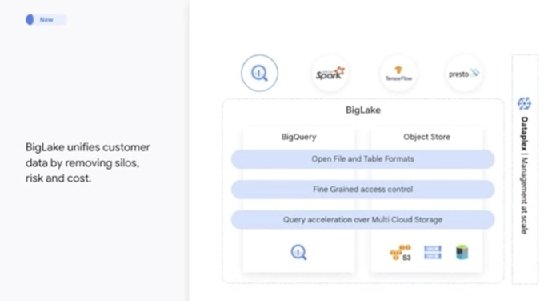
Les capacités de BigLake revendiquées par GCP.
Cela ne dit pas exactement ce que fait BigLake. Ce produit est en réalité un moteur de stockage « unifié » attenant à BigQuery qui doit simplifier l’accès et la gouvernance des tables dans des formats ouverts à travers plusieurs services cloud. Ces données doivent résider dans les services de stockage objet des trois géants du cloud, à savoir Google Cloud Storage, Amazon S3 et Azure Data Lake Storage Gen2. La promesse de GCP pour le client, c’est qu’il peut s’appuyer sur son infrastructure cloud existante.
Cependant, pour obtenir le niveau de gouvernance souhaitée, BigLake introduit de nouvelles tables. Il est toujours possible d’utiliser des « tables externes », ce qui réclame de stocker les métadonnées et les schémas de ces actifs dans BigQuery, mais GCP ne garantit pas la gouvernance et la cohérence des données associées. En revanche, une commande facilite la conversion des tables externes en tables BigLake. Ce mécanisme ressemble aux Governed Tables introduites dans Lake Formation par AWS.
En effet, le fournisseur a associé la création des tables BigLake avec la configuration des droits d’accès depuis Google IAM. Ainsi, il y a trois rôles : l’administrateur data lake qui gère les règles du IAM pour les objets et les buckets Cloud Storage, l’administrateur de data warehouse qui crée, efface et met à jour les tables BigLake (l’équivalent d’un administrateur BigQuery) et le data analyst, qui peut lire et interroger les données sous certaines conditions. Le contrôle d’accès se joue au niveau des lignes et des colonnes via des labels à éditer depuis l’éditeur de schéma des tables BigLake. Les règles d’accès sont appliquées à travers les API BigQuery. Pour les clients qui souhaitent gouverner les données de manière consistante entre les data lakes, les data warehouses, les data marts, GCP intégrera Dataplex, son service de data management unifié (et de gestion de data mesh) à BigLake.
Une table BigLake se comporte comme ses consœurs de BigQuery, elle répond aux mêmes limites, mais il y a différentes API pour les adresser. L’API BigQuery Storage Read reposant sur le protocole gRPC permet de lire les tables BigLake au format JSON, CSV, Avro et ORC depuis les moteurs de traitement open source tel Apache Spark. Il y a aussi des connecteurs spécifiques aux moteurs Spark, Hive et Trino hébergés sur des VM Dataproc ou sur des conteneurs pour traiter les données stockées dans Google Cloud Storage. Même la couche de transfert de données vers ces moteurs analytiques est open source : GCP s’appuie sur Apache Arrow pour accélérer le téléchargement des (gros) lots de données.
À noter que Google Cloud Storage ne supporte pas encore les formats Avro et ORC. GCP promet de prendre en charge les formats de table de Delta Lake (Parquet) et plus tard d’Apache Iceberg et d’Apache Hudi.
Si les données ne viennent pas à Google Cloud, Google Cloud ira aux données
Par défaut, sur Amazon S3 et Azure Data Lake Storage Gen2, les tables externes peuvent être lues via l’API de BigQuery Omni, la version multicloud et distribuée de BigQuery. GCP a également rendu les tables BigLake compatibles avec ce service. Le mécanisme de conversion s’avère alors particulièrement utile.
Pour traiter les données, GCP déploie et gère le plan de contrôle de BigQuery sur GCP. Ce control plane pilote les plans de données sur les instances cloud d’AWS (S3) ou de Microsoft Azure (Azure Blob Storage), data planes qui exécutent le moteur de requêtes de BigQuery, puis entreposent les résultats des interrogations dans les services de stockage objet de l’usager ou les renvoient vers l’instance maîtresse, sur GCP. L’utilisateur, lui, s’occupe de câbler les connexions externes et d’écrire les requêtes. BigQuery Omni est entièrement managé par GCP, le client ne paie pas de coût d’egress auprès des fournisseurs tiers.
« BigQuery Omni est un grand différenciateur, parce que nous n’obligeons pas à facturer des coûts importants d’ETL », assure Gerrit Kazmeier.
« Nous aimerions beaucoup que plus de données soient créées sur BigQuery, mais nous savons très bien que nos clients ont des données réparties à travers plusieurs data lakes dans plusieurs clouds, dont AWS et Azure ».
Sudhir HasbeDirecteur principal de la gestion des produits, Google Cloud
« Nous aimerions beaucoup que plus de données soient créées sur BigQuery, mais nous savons très bien que nos clients ont des données réparties à travers plusieurs data lakes dans plusieurs clouds, dont AWS et Azure », ajoute Sudhir Ashbe qui insiste sur le fait que GCP croit au fait de placer le calcul au plus proche des données au lieu de les déplacer. « Nous acceptons le fait que les fichiers soient à différents endroits et nous allons aux données plutôt que de les rassembler à un seul endroit ».
BigQuery Omni est en disponibilité générale depuis décembre 2021. Il est sans doute un peu trop tôt pour vérifier si le déploiement de la solution et son modèle de tarification sont plus avantageux que de multiplier les jobs ETL, coût de sortie des données inclus.
Data Cloud Alliance : des engagements, pas encore de feuille de route
Dans tous les cas, BigLake doit limiter sinon empêcher les mouvements et la multiplication des copies de données. Cette unification des usages est vantée par Snowflake, d’un côté, avec sa plateforme propriétaire multicloud, et surtout par Databricks qui a été le premier à miser sur le terme un brin marketing de Lakehouse, la combinaison d’un data lake et d’un data warehouse (et qui est moins convaincu par le principe de multicloud). « Je pense que la plus grande différence est que nous croyons en l’ouverture de l’architecture des données », affirme Gerrit Kazmaier pour différencier l’approche de GCP de celle d’acteurs comme Snowflake. « Avec BigLake, nous ne nous attendons pas à ce que les clients fassent un compromis entre le stockage propriétaire ou ouvert, entre les moteurs de traitements open source ou propriétaires ». Par exemple, GCP anticipe le fait que les clients qui emploient la solution analysent les données en provenance de différentes sources telles des logiciels SaaS (Salesforce, Workday ou Marketo), et les visualisent avec Looker, Power BI ou Tableau.
« Les clients ne veulent pas se retrouver enchaînés à un vendeur, y compris à nous-mêmes ».
Gerrit KazmaierVice-président et directeur général, base de données, analytiques et Looker, Google Cloud
Quant à Databricks, c’est un partenaire qui partage « la même philosophie » que GCP, indique Sudhir Ashbe. « Nous travaillons avec Databricks, leur moteur Spark s’intègre avec BigQuery et nous continuerons à collaborer avec cette entreprise pour résoudre ensemble les problèmes des clients de manière cohérente avec les formats open source ».
En ce sens, Google a annoncé la création de la Data Cloud Alliance. Databricks est un des membres de ce regroupement tout comme Startbust, MongoDB, Elastic, Fivetran, Neo4J, Redis, Dataiku Accenture et Deloitte. Ces partenaires « s’engagent » à accélérer l’adoption des modèles et des standards ouverts de données, à réduire la complexité de la gouvernance, de conformité et de sécurité et à favoriser la formation des talents et des praticiens dans ces domaines.
« Les clients ne veulent pas se retrouver enchaînés à un vendeur, y compris à nous-mêmes », reconnaît Gerrit Kazmaier. « Il s’agit de réunir le meilleur de tous ceux-là et résoudre les problèmes de nos clients communs », ajoute-t-il. Cela ne rend pas l’initiative beaucoup plus limpide pour le moment. Les responsables promettent que ce « moment fondateur » sera suivi d’annonces, mais aucun agenda n’a été dévoilé au lancement. De son côté, Databricks évoque le fait de contribuer à cette initiative pour améliorer l’échange de données, l’une de ces priorités actuellement.