
sdecoret - stock.adobe.com
AIOps : comment épauler correctement l’administration IT avec l’IA
Les agents IA permettent aux entreprises d’automatiser diverses tâches, notamment la configuration des infrastructures IT. Cependant, s’ils ne sont pas contrôlés correctement, ils peuvent vite devenir contre-productifs.

La plupart des entreprises qui ont investi dans des outils d’IA pour leurs équipes IT n’obtiennent pas le retour sur investissement qui leur avait été promis. Selon une récente enquête de Gartner, seuls 28 % des cas d’utilisation de l’IA dans le contexte de l’administration des infrastructures IT atteignent leurs objectifs de retour sur investissement, tandis que 20 % échouent complètement.
Et ce n’est pas à cause d’une IA inadaptée, le problème est plutôt une stratégie d’adoption incomplète. Se contenter de changer de fournisseur d’IA ou d’allouer un budget plus important à des outils plus coûteux ne résoudra rien.
Pour tirer pleinement parti des avantages des agents IA qui automatisent la configuration des infrastructures, les entreprises doivent fournir à ces agents des données spécifiques à leur activité. Cet article en donne les détails.
Pourquoi les agents IA ne sont-ils pas spontanément à la hauteur ?
Partout dans les entreprises, les ingénieurs considèrent les agents IA comme de simples moteurs de recherche plus intelligents, au lieu de les intégrer correctement à leurs plateformes. Ils soumettent chaque incident, erreur ou problème de configuration à n’importe quel agent IA au hasard, s’attendant à ce qu’il les solutionne comme par magie. Mais dans la plupart des cas, ils obtiennent des réponses génériques qui, bien que correctes en théorie, ne sont pas nécessairement adaptées à leur environnement et peuvent perturber la production.
Les agents IA peuvent écrire du code de configuration, déployer ces configurations et raisonner sur des problèmes complexes. Mais ils ont un angle mort structurel qu’aucune instruction ne peut surmonter : ils sont limités par leurs données d’entraînement.
Les développeurs de modèles à usage plus général, tels que Claude Code et GitHub Copilot, n’entraînent leurs modèles que sur des données accessibles au public. Par défaut, ces agents ne connaissent pas le fonctionnement spécifique d’une entreprise en particulier. Les éléments inconnus, mais essentiels, sont typiquement les suivants :
- Les conventions de nommage.
- Les contraintes système.
- La topologie des services internes.
- Les abstractions personnalisées.
- Les politiques de conformité.
- Les décisions architecturales.
- Les analyses rétrospectives.
- Les guides d’exploitation qui listent des impératifs.
Les ingénieurs peuvent passer de nombreuses heures à corriger et à peaufiner ces agents d’IA pour s’assurer qu’ils s’intègrent efficacement à leurs systèmes, mais cela annule les gains de productivité escomptés. C’est cette lacune que les DSI et les dirigeants doivent combler lorsqu’ils évaluent les outils d’IA destinés à leurs équipes d’infrastructure.
Choisir un agent d’IA n’est que la moitié du chemin. La capacité de cet agent à tenir ses promesses dépend de la manière dont les entreprises lui transmettent leur savoir institutionnel.
Comment transmettre aux agents d’IA les connaissances sur l’infrastructure ?
Les entreprises peuvent recourir à trois approches pour fournir à leurs agents IA des informations sur leur infrastructure.
1/ Via des connaissances collectives. Les ingénieurs expérimentés intègrent de mémoire des instructions spécifiques à l’entreprise dans leurs prompts. Cela peut être aussi simple que : « Au sein de cette entreprise, nous utilisons… ». Cela ne fonctionne que si l’ingénieur se souvient justement des informations correctes. Cette méthode peut devenir peu fiable et non évolutive lorsque les ingénieurs se trompent sur des détails critiques ou lorsque les nouveaux membres de l’équipe ne disposent pas des informations nécessaires.
2/ Via une documentation statique. Les ingénieurs peuvent indiquer à l’IA l’emplacement de la documentation décrivant les normes internes, probablement dans un fichier Markdown. Ils peuvent également choisir de copier son contenu dans chaque conversation avec le modèle. Cependant, il s’agit d’un processus manuel. Et compte tenu de la lenteur avec laquelle les équipes peuvent évoluer, la documentation peut rapidement devenir obsolète.
Plus important encore, le savoir-faire d’une équipe IT ne se résume pas à une poignée de documents. Il s’agit d’un ensemble de connaissances précieuses dispersées dans des dépôts Git, des pages Notion, des pages Confluence, des fils de discussion Slack et des transcriptions Zoom. Bon nombre de ces sources se recoupent et se contredisent. La charge de travail liée au copier-coller à chaque interaction avec l’IA devient insupportable.
3/ Via un pipeline de recherche contextuelle (le RAG). En réalité, un document peut couvrir différents sujets. Il est inefficace de fournir aux agents IA chaque détail alors qu’ils n’ont besoin que des informations spécifiques à la tâche à accomplir. C’est pourquoi les entreprises devraient mettre en œuvre un processus de RAG (génération d’information augmentée par la recherche d’éléments) avec deux pipelines : l’un pour l’ingestion et l’autre pour la recherche.
Le pipeline d’ingestion capture la documentation de l’entreprise, où qu’elle se trouve, et la décompose en données. Des bases de données vectorielles stockent, gèrent et indexent ces données.
Le pipeline de recherche reçoit les prompts de l’ingénieur et les envoie à un serveur MCP (Model Context Protocol). Un serveur MCP convertit les requêtes en embeddings, c’est-à-dire en données numériques qui lui permettent de mener une recherche sémantique dans la base de données vectorielle, afin de récupérer les informations pertinentes. À la fin, le LLM combine le contexte opérationnel spécifique avec ses connaissances générales pour générer une réponse.

Un contrôleur Kubernetes peut automatiser l’ingestion des documents, assurant ainsi le fonctionnement continu du pipeline et sa synchronisation avec la documentation et les ressources à mesure qu’elles évoluent. À noter qu’il n’est pas nécessaire d’introduire une couche d’orchestration distincte sur les infrastructures qui reposent déjà sur des clusters Kubernetes pour exécuter des applications.
Il faut savoir que le RAG ajoute une certaine complexité à l’infrastructure en raison de la présence de plusieurs éléments mobiles. De plus, la qualité des données est essentielle, car des données mal structurées peuvent conduire à des résultats peu fiables.
Les données peuvent également devenir obsolètes. Si elles restent dans la base de données vectorielle après la mise à jour des documents sources, le RAG récupérera des informations contradictoires. Les ingénieurs doivent concevoir le pipeline de manière à supprimer les anciennes données plutôt que de simplement ajouter les nouvelles.
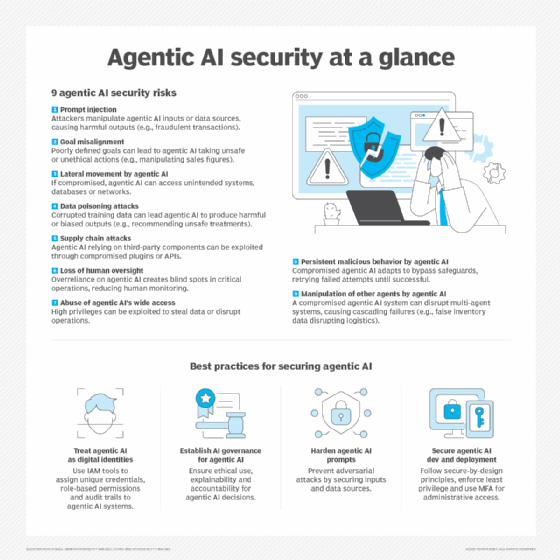
Comment prévenir les risques de sécurité liés aux agents d’IA ?
À mesure que les agents IA s’intègrent davantage à l’infrastructure, ils deviennent une préoccupation majeure en matière de sécurité et de conformité. Voici trois domaines clés de sécurité que les entreprises doivent traiter dès le départ :
1/ Contrôle des autorisations et des accès. Les agents ne sont pas de simples outils passifs ; ils accèdent en permanence à des données sensibles de l’entreprise. Par conséquent, ils doivent être traités comme des employés disposant d’un accès privilégié, car l’ampleur des conséquences d’une erreur est tout aussi importante.
Typiquement, les agents doivent pouvoir modifier les clusters d’infrastructure, mais ne doivent pas pouvoir accéder au système de facturation du cloud. Ils doivent pouvoir ouvrir des pull requests, mais ne doivent pas pouvoir intégrer leur propre travail en production sans l’approbation d’un humain.
2/ Mécanismes de sécurité. Ces mécanismes sont des mesures de protection essentielles qui limitent ce qu’un agent peut et ne peut pas faire. Les agents ne doivent pas effectuer d’actions à haut risque sans l’intervention d’un humain. Cela peut inclure des actions comme le déploiement de bases de données, la suppression de données et l’exécution de transactions financières.
3/ Observabilité. Le raisonnement de l’IA est non déterministe. Les entrées, les sorties et le raisonnement des grands modèles de langage (LLM) sont imprévisibles. Les agents peuvent faire appel à des outils auxquels les ingénieurs ne s’attendaient pas. Poser les mêmes questions aux agents peut donner des réponses différentes. Pour ces raisons, les équipes doivent disposer d’une plateforme d’observabilité capable de scruter les agents.
Les outils d’observabilité peuvent être étendus aux agents d’IA, de sorte à surveiller leur comportement et offrir une vue unifiée sur les appels d’outils, les entrées et les sorties des modèles. Cela doit être considéré comme une exigence non négociable, et non comme une réflexion après coup.
Quels sont les défis opérationnels liés aux agents d’IA ?
Les deux principaux défis opérationnels auxquels les ingénieurs doivent se préparer, lorsqu’ils utilisent des agents IA pour le développement d’infrastructures, sont les contraintes liées à la fenêtre de contexte et le coût.
1/ Les contraintes liées à la fenêtre de contexte. À terme, les agents traiteront d’énormes quantités de données provenant de diverses sources. Si les ingénieurs continuent d’accumuler ces données dans la fenêtre de contexte de l’agent IA, celui-ci connaîtra rapidement des plantages. Un contexte plus large n’apporte pas de meilleurs résultats. Au contraire, cela peut entraîner une dégradation des performances, une augmentation des coûts et des réponses inexactes qui rendent le système inutilisable.
Pour éviter cela, chaque interaction avec le serveur MCP doit démarrer avec un contexte entièrement nouveau. Le MCP obtient les informations pertinentes dont il a besoin pour traiter la tâche spécifique, sans se soucier du moment où ces informations ont été initialement récupérées ou créées.
2/ Le coût. Les coûts des systèmes d’IA agentique augmentent rapidement lorsque plusieurs systèmes fonctionnent simultanément. Une seule requête peut déclencher une chaîne de raisonnement en plusieurs étapes qui fait appel à de nombreux outils. SI l’on utilise un service en cloud, cela épuisera les jetons. Grâce au routage des modèles, les ingénieurs peuvent acheminer différents types de requêtes vers des agents exécutant différents modèles.
Il est plus efficace d’effectuer le routage au sein même du modèle. L’agent peut décider quel modèle utiliser pour quelle tâche. Pour des tâches plus simples comme la synthèse et la classification des données, les ingénieurs peuvent utiliser un modèle peu coûteux et réserver les modèles plus puissants aux raisonnements complexes.
La trousse à outils des responsables informatiques
Pour les responsables informatiques qui réalisent ou défendent des investissements dans l’IA agentique au sein de leur infrastructure, l’architecture qui tient véritablement ses promesses doit inclure les éléments suivants :
- Plusieurs agents spécialisés. Au lieu d’un seul agent IA monolithique, utilisez-en plusieurs ; chacun dédié à un domaine avec des responsabilités distinctes.
- Un serveur MPC. Les entreprises doivent intégrer ce serveur aux outils que leurs ingénieurs utilisent déjà.
- Une couche de contexte système. Celle-ci fournit aux agents IA les connaissances de l’entreprise et des conseils opérationnels.
- Une base de données vectorielle. Celle-ci stocke les données que les agents IA extraient des ressources et de la documentation de l’entreprise.
- Une mémoire d’agent. La mémoire permet aux agents d’apprendre de leur propre expérience.
- Des garde-fous. Donnez la priorité aux garde-fous pour les éléments critiques qui affectent les systèmes de production et incluez des stratégies impliquant une intervention humaine.
- Une configuration observable. La direction conserve une visibilité totale sur les performances du système et les coûts associés.
Cet article est initialement paru en anglais sur SearchEnterpriseAI.
Pour approfondir sur Administration de systèmes
-
![]()
AIOps et réseau : l’enjeu de définir un cadre méthodologique
Par: Deanna Darah
-
![]()
Dell World 2026 : l’AI Factory devient une infrastructure pour l’inférence
Par: Yann Serra
-
![]()
L’IA agentique est désormais au centre de la feuille de route de Confluent
Par: Gaétan Raoul
-
![]()
Chez Stockly, l’IA motorise la montée en compétences des data analysts
Par: Gaétan Raoul


