
Looker_Studio - stock.adobe.com
Machine learning : différencier l’échantillonnage stratifié, en grappes et par quotas
Ce conseil brosse les grandes différences entre l’échantillonnage stratifié, en grappes et par quotas, des approches très populaires en statistique et en machine learning.
En analyse statistique, il existe plusieurs méthodes d’échantillonnage pour observer le comportement de populations. Elles s’avèrent particulièrement utiles pour réaliser des sondages, mais également pour effectuer des enquêtes marketing, de marché ou des études socioéconomiques.
En data science, ces procédés servent aussi à préparer des données à l’entraînement d’un algorithme de machine learning et à détecter ou d’éliminer des biais. D’un point de vue technique, cela permet d’alléger les traitements quand le jeu de données est trop volumineux pour des opérations en mémoire vive ou lorsque ce calcul coûte trop cher à une organisation.
Dans cet article, nous brossons les différences majeures entre trois méthodes : l’échantillonnage stratifié, en grappes et par quotas. Nos exemples s’appliquent à l’étude d’une population.
Quelle est la différence entre l’échantillonnage stratifié et l’échantillonnage en grappes ?
La principale différence entre l’échantillonnage stratifié (stratified sampling) et l’échantillonnage en grappes (ou cluster sampling) est qu’avec le second, des groupes naturels séparent votre population. Par exemple, vous pourriez être en mesure de scinder vos données suivant des critères innés tels que des pâtés de maisons, des circonscriptions électorales ou des districts scolaires. Avec l’échantillonnage aléatoire stratifié, ces ruptures peuvent ne pas exister*, vous subdivisez donc votre population cible en groupes (plus formellement appelés « strates »).
Avec l’échantillonnage stratifié, un panel est tiré de chaque strate en utilisant l’échantillonnage aléatoire simple (EAS) ou l’échantillonnage systématique. Avec l’EAS, une unité de la population a une chance égale d’être incluse dans ce panel. Avec l’approche systématique, chaque élément présent dans l’échantillon est choisi à intervalle régulier au sein de la population à étudier.
Dans l’image ci-dessous, disons que vous avez besoin d’un échantillon de 6 personnages. Deux membres de chaque groupe (jaune, rouge et bleu) sont sélectionnés aléatoirement. Avec cette méthode, la constitution des groupes doit être proportionnelle : dans cet exemple simple, 1 tiers des individus de chaque groupe (2 personnages jaunes sur six, 2/6 rouges et 2/6 bleues) a été échantillonné. Si vous avez un cluster d’une taille différente, veillez à ajuster vos proportions. Par exemple, si vous avez 9 personnages jaunes, 3 rouges et 3 bleus, un panel de 5 éléments sera composé de 3 jaunes sur 9, 1 rouge sur 3 et 1 bleu sur 3.
Avec le cluster sampling, l’unité d’échantillonnage est la grappe entière ; au lieu de sélectionner des individus dans chaque groupe, le data scientist étudiera des clusters entiers. Dans l’image ci-dessous, les strates sont des regroupements naturels par couleur de personnages bâtons (jaune, rouge, bleu). Un échantillon de 6 personnes est nécessaire, donc deux des strates complètes sont choisies au hasard (dans cet exemple, les groupes 2 et 4).
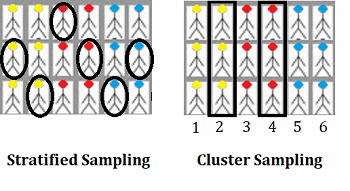
*Notez que nous écrivons que des ruptures « pourraient » ne pas exister ; la façon dont vous divisez vos données dépend de vous, vous pourriez donc ignorer les groupes existants et choisir l’échantillonnage aléatoire stratifié plutôt que celui en grappes.
Quelle est la différence entre l’échantillonnage stratifié et l’échantillonnage par quotas ?
La principale distinction entre l’échantillonnage stratifié et l’échantillonnage par quotas réside dans la méthode associée :
- Avec l’échantillonnage stratifié (et en grappes), vous utilisez une méthode d’échantillonnage aléatoire.
- Avec l’échantillonnage par quotas (quota sampling), les méthodes aléatoires ne sont pas manipulées (on parle d’échantillonnage « non probabiliste »).
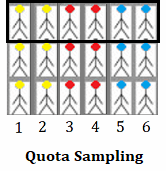
À titre d’exemple très simple, disons que vous prenez en compte le groupe de personnages (jaunes, rouges et bleues) pour votre échantillon par quotas. La couche supérieure des personnes est beaucoup plus proche, géographiquement, de votre emplacement. Par conséquent, il serait moins coûteux pour votre étude de sélectionner cet échantillon de la population. Pour autant, notez que la proportionnalité entre chaque strate d’individu doit toujours être respectée.
En condition réelle, il se peut que vous deviez atteindre des quotas au sein de vos échantillons (c’est pourquoi, techniquement, on parle d’échantillonnage par quotas). Par exemple, disons que vous réalisez une étude sur des promotions auprès de 600 personnes et que vous devez inclure 300 femmes. Votre quota (300 femmes) vous empêcherait d’utiliser une méthode de sélection aléatoire classique, comme l’EAS, car vous ne respecteriez sans doute pas ce prérequis. Par conséquent, votre méthode de sélection ne sera pas probabiliste, et vous effectuerez un échantillonnage par quotas.
Notez qu’il existe deux types d’échantillonnage par quotas : non contrôlé (les sujets sont choisis comme vous le souhaitez) et contrôlé (des restrictions sont exigées pour limiter votre choix). Dans les exemples ci-dessus, votre choix d’inclure des participants à proximité serait non contrôlé et les quotas imposés rendraient la méthode contrôlée.
Quand faut-il choisir une méthode particulière ?
Lorsque vous ne pouvez pas récolter des informations complètes sur votre population, mais que vous pouvez obtenir des données sur des groupes/clusters, sélectionnez l’échantillonnage en grappes. En supposant que vous ayez opté pour ce cluster sampling, vous pouvez être soumis à des contraintes budgétaires ou temporelles. Dans ce cas, il peut être plus pratique d’utiliser cette méthode pour désigner des personnes ou des entités qui sont plus proches, plus rapides à répondre ou moins coûteuses à atteindre.
| Méthode | Type | Usage |
| Echantillonnage aléatoire stratifié | Probabiliste | Population hétérogène, différentes strates sont concernées par l'étude |
| Echantillonnage en grappes | Probabiliste | Population composée d'unités et non d'individus |
| Echantillonnage par quotas | Non Probabiliste | Présence de strates, mais échantillonnage stratifié impossible à cause de contraintes |
L’échantillonnage par quotas doit permettre d’apporter de la représentativité dans un panel de commodité (où l’on sélectionne tous les exemples qui nous conviennent, sans contraintes, strates ou groupes). Enfin, si l’on vous donne un quota à respecter, vous n’aurez pas d’autre choix que d’employer cette technique.
Cet article est originellement paru dans les colonnes de DataScienceCentral.com, propriété de Techtarget, également propriétaire du MagIT.
Stephanie Glen est une contributrice à DataScienceCentral.com. Après avoir travaillé pendant plusieurs années à l'enseignement des mathématiques et des statistiques au niveau universitaire, elle a créé et développé le site Web StatisticsHowTo.com.







