Les bases de l’administration d’un cluster Kubernetes
L’administration d’un cluster de containers est un peu plus complexe que celle d’un cluster de machines virtuelles. Cet article fait le point sur les différences et donne les commandes pour démarrer.
Kubernetes est une technologie d’orchestration de containers créée pour aider les entreprises à exécuter de grandes applications sur internet. Elle comporte de nombreuses pièces mobiles et son champ d’action est vaste. Elle est également réputée pour être difficile à comprendre et à mettre en œuvre.
Kubernetes est un outil permettant d’exécuter et de gérer un groupe de containers Docker. Les containers Docker, outre être des sortes de machines virtuelles ne contenant qu’une application, sans l’environnement d’exploitation sous-jacent tel que l’OS, permettent aux développeurs d’applications d’empaqueter les logiciels pour les déployer, d’abord à des fins de test, puis pour la production. L’équipe d’exploitation doit ensuite parvenir à faire fonctionner les applications en containers Docker sur des serveurs, en cloud, ou à cheval entre des clouds et des datacenters. Kubernetes sert cet objectif.
Les équipes de développement continueront à construire et à empaqueter des applications à l’aide de containers Docker – probablement avec des fichiers « manifestes » de Kubernetes. Les équipes d’exploitation déploieront et géreront les clusters Kubernetes où les containers s’exécutent.
De l’IT traditionnelle aux containers
Cela étant dit, les containers posent des contraintes qui n’existent pas avec les machines virtuelles. Tout d’abord, les containers Docker étaient initialement censés être éphémères (juste une fonction web, un « microservice », dont on active autant de copies en production que la demande à un instant T l’exige), sans données persistantes. Dans les faits, de nombreuses applications d’entreprises ont besoin qu’un stockage persistant, un volume de fichiers, soit attaché aux containers. C’est l’enjeu des pilotes de stockage CSI. Problème, les volumes de données sont plus difficiles à copier ou à déplacer entre les serveurs que les services fonctionnels.
Autre différence : le réseau. La vocation des containers étant d’être déployés partout où leurs micros-fonctions applicatives sont nécessaires, il est plus pertinent que les containers communiquent entre eux par familles fonctionnelles que par sous-réseaux géographiques. Dès lors, en place du traditionnel routage TCP/IP, un trouve un maillage de services, ou « réseau Mesh ».
Le réseau Mesh permet à divers microservices de se découvrir les uns les autres et limite la communication aux chemins autorisés entre eux. Au-delà des ports TCP/IP qui existent entre des services, les autorisations d’accès se feront plutôt sur le droit d’utiliser ou non certaines API. Toutes les applications sur Kubernetes n’auront pas besoin d’un maillage de services, mais la technologie devient une exigence standard des plateformes Kubernetes.
Enfin, Kubernetes complexifie l’administration de l’IT. En temps normal, les équipes d’exploitation surveillent la disponibilité et les performances des applications, puis à résolvent les éventuels problèmes qui surviennent. Kubernetes ajoute une autre couche d’abstraction qui nécessite une surveillance supplémentaire pour comprendre la santé globale de l’application.
Un déploiement Kubernetes comprend des serveurs de contrôle, qui exécutent l’orchestrateur Kubernetes et qui sont chacun responsables de la gestion d’un cluster de pods, et des serveurs de travail où s’exécutent pods et containers. Tous ces serveurs sont appelés des nœuds.
Les nœuds de travail sont physiques ou virtuels et ont un système d’exploitation qui servira pour tous les pods qu’ils hébergent. Le logiciel qui orchestre les pods depuis le système d’exploitation local, sorte d’hyperviseur dédié aux containers, s’appelle un CRI (Container Runtime Interface). Il s’agit dans la plupart des cas de Docker. On trouve également sur ce système d’exploitation un agent, appelé Kubelet, qui communique avec les nœuds de contrôle pour écouter leurs directives et les transmettre au CRI.
Un pod est un groupe de containers complémentaires. Par exemple, un pod peut comprendre le container applicatif et un container qui sert de firewall pour ce container applicatif (dans ce cas précis, le second container est appelé un side-car). Un pod peut aussi n’avoir qu’un seul container applicatif.
Plusieurs pods, complémentaires ou redondants, sont, de manière purement logique, regroupés au sein d’un service applicatif. D’un côté, un service applicatif est potentiellement exécuté depuis plusieurs serveurs virtuels ou physiques. De l’autre, Kubernetes déploie ces serveurs sur plusieurs clusters physiques. Les clusters physiques qui communiquent entre eux en TCP/IP et les services abstraits qui communiquent via des API coexistent dans l’administration de Kubernetes, mais ils sont indépendants les uns des autres.
Un cluster de pods, potentiellement à cheval sur plusieurs serveurs (physiques ou virtuels), peut-être segmenté. On peut par exemple définir un namespace par serveur, ce qui permet de mieux répartir les utilisateurs entre les ressources physiques. Dans ce cas, un service sur un serveur donné a un nom de type service.namespace dans le DNS exposé par Kubernetes.
On peut aussi définir un label pour regrouper plusieurs pods qui pourraient être administrés ensemble (mises à jour communes, etc.)
Différentes implémentations de Kubernetes
L’objectif principal de Kubernetes est d’héberger des applications sur un cluster de serveurs avec des fonctions sophistiquées d’équilibrage de charge et d’allocation des ressources. Cela permet de garantir le bon fonctionnement des applications, même si certains serveurs tombent en panne. Dans les déploiements de production, l’utilisation de plusieurs serveurs pour Kubernetes est essentielle. C’est le propos de distributions Kubernetes tout-en-un telles qu’OpenShift de Red Hat, ou Tanzu de VMware.
VMware vSphere with Tanzu, par exemple, permet de déployer un cluster de plusieurs machines virtuelles Kubernetes (orchestration) et de plusieurs serveurs de travail, physiques ou virtuels, qui hébergent eux-mêmes plusieurs pods. Il déploie dans les nœuds de travail un Linux minimaliste Photon OS censé être particulièrement optimisé pour servir d’environnement d’exécution aux containers. De plus, la partie vSphere permet de centraliser la maintenance et les mises à jour pour tous les serveurs, de contrôle comme de travail, et tous les pods.
Il existe aussi des versions « minimes » de Kubernetes qui permettent d’exécuter un environnement de plusieurs containers depuis une seule machine, typiquement le poste de travail Windows, Linux ou Mac d’un informaticien.
Citons Minikube, de la communauté Open source, MicroK8s de Canonical (qui édite par ailleurs le Linux Ubuntu), ou encore K3s de l’éditeur Rancher. Ces trois solutions permettent également d’exécuter des containers depuis des machines installées en edge, par exemple sur un NUC ou un Raspberry Pi qui feraient office de serveurs de caméras de vidéosurveillances.
Installation générique de Kubernetes
Si l’on en reste aux versions purement communautaires, Kubernetes s’installe sur un cluster de serveurs qui fonctionnent déjà sous Linux. La première étape est d’installer Docker sur chaque machine pour que leur Linux supporte l’exécution de containers. De manière alternative, la communauté derrière Kubernetes a déployé son propre moteur de containers, containerd.
Il faut ensuite installer sur chaque serveur les logiciels kubeadm (l’agent d’installation de Kubernetes) et kubelet (le démon qui fait l’interface entre les commandes envoyées par les nœuds de contrôle et les containers). On finira en installant la commande kubectl sur chaque machine susceptible de piloter le cluster.
Une fois que tous les logiciels sont installés, il faut configurer le cluster. Pour cela, on choisit l’un des serveurs pour en faire le nœud maître et l’on y exécute la commande de configuration suivante, en précisant la plage d’adresses IP dans laquelle se trouvent tous les nœuds :
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
Cette commande a la délicatesse d’afficher les étapes suivantes à effectuer, avec les commandes correspondantes à taper. Sur la machine maître, on copie les fichiers de configuration de Kubernetes dans le répertoire de l’administrateur du cluster. Et, sur chaque serveur de travail, on tape la commande kubeadm join <adresse IP du serveur maître> :<port réseau> pour rejoindre le cluster Kubernetes. La documentation officielle détaille toute la procédure.
Kubectl, la commande pour piloter Kubernetes
Il existe pléthore de consoles graphiques pour administrer un cluster Kubernetes, mais la base standard de toutes les implémentations de Kubernetes est la ligne de commande kubectl. Avec kubectl, les administrateurs peuvent effectuer un large éventail de tâches de gestion et d’orchestration de containers, telles que : appliquer un changement de configuration à une ressource, attacher Kubernetes à un container en cours d’exécution, accéder aux journaux de containers ou encore déployer une image donnée sur le cluster.
Les commandes Kubectl suivent une structure commune – ou syntaxe – qui permet aux administrateurs de lire et de valider chaque commande kubectl saisie dans la fenêtre du terminal. Chaque appel kubectl comporte quatre paramètres principaux :
kubectl <fonction> <type> <nom> <flags>
Le paramètre <fonction> est l’opération qui doit être effectuée sur une ressource. Kubectl prend en charge des dizaines de fonctions, notamment create (créer), get (obtenir), describe (décrire), execute (exécuter) et delete (supprimer).
Le paramètre <type> indique le type de ressource, comme les bindings, les nœuds et les pods. Les désignations des types de ressources utilisent généralement des abréviations pour simplifier la ligne de commande. Par exemple, le type persistentvolumeclaims peut être abrégé en pvc. Le paramètre <type> est puissant, car il existe des dizaines de types de ressources possibles, parmi lesquels des espaces de noms, des contrôleurs de réplication, des quotas de ressources, des services, des travaux, des baux ou encore des événements. Les développeurs et les administrateurs Kubernetes doivent connaître la liste complète des types de ressources.
Le paramètre <nom> précise le nom de la ressource dans l’environnement. Si le paramètre <nom> est omis, les détails de toutes les ressources sont renvoyés – un peu comme un joker en Shell. En outre, les administrateurs peuvent spécifier plusieurs types et noms de ressources dans la même ligne de commande, comme indiqué ci-dessous :
kubectl <commande> <type> <nom1> <nom2> ... <nomX>
Ceci est utile lorsque les noms sont tous du même type de ressource, par exemple :
kubectl get pod test-pod1 test-pod2
Enfin, le paramètre <flags> active des options facultatives à la commande. Les options varient en fonction de la commande, ce qui signifie que toutes les options ne sont pas disponibles pour toutes les commandes. Par exemple, les options -s (un tiret, notation abrégée) ou --server (deux tirets, notation abrégée) indiquent le port et l’adresse du serveur de l’API Kubernetes.
Les fonctions de Kubectl prennent en charge des dizaines d’opérations d’administration. L’aide-mémoire kubectl ci-dessous offre un aperçu des fonctions disponibles, classées par ordre alphabétique. Pour connaître leur syntaxe, il est possible d’utiliser la fonction help suivie du nom de la fonction désirée. Pour plus d’informations, consultez la documentation de Kubernetes.
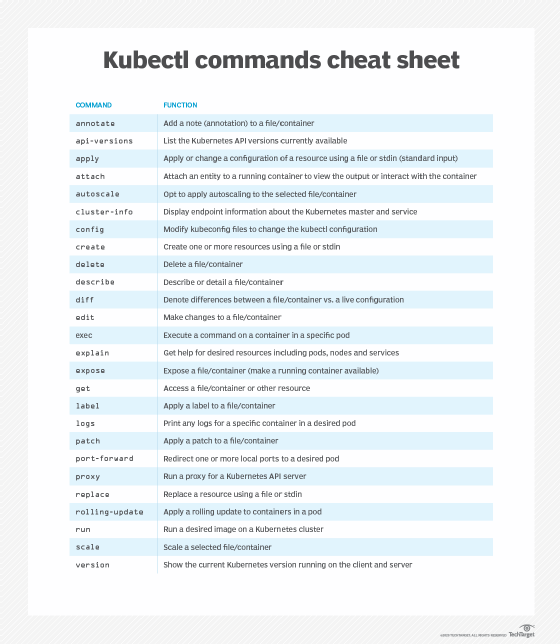
Déployer des ressources avec Kubectl
Parmi toutes ses fonctions de pilotage, Kubectl sert surtout à créer des ressources, les effacer, lancer l’applicatif d’un pod et explorer les logs d’un pod.
On crée une ressource depuis un fichier descriptif (un « manifeste » dans la nomenclature Kubernetes) avec la fonction apply. La commande kubectl apply -f mynewservice.yaml utilise un fichier YAML – format ici spécifié par l’option -f – nommé mynewservice.yaml pour déployer un service. Les utilisateurs peuvent opter pour une commande plus large, telle que kubectl apply -f nameofdirectory, qui déploie tous les services et toutes les ressources définis par les tous les fichiers YAML ou JSON situés dans le répertoire spécifié.
Voici un exemple de fichier descriptif en YAML :
apiVersion: v1
kind: Pod
metadata:
name: nicepod
labels:
App: dev
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
Voici son explication :
apiVersion spécifie une version particulière d’un objet API. Il est important de le préciser, car différentes versions peuvent avoir un comportement légèrement différent.
kind indique à Kubernetes le type d’objet que vous souhaitez créer. Ici, nous créons un Pod. On pourrait aussi créer un Deployment, un StatefulSet, une ConfigMap, etc.
metadata inclut certains attributs qui peuvent être utilisés pour identifier le pod de manière unique, tels que le nom, le label auquel il appartient et l’espace de noms. Si aucun espace de noms n’est spécifié, le pod est placé dans l’espace de noms par défaut.
spec contient une série de champs décrivant le pod. Dans cet exemple, il n’y a qu’un container, dont on indique le nom (web), le fichier image (nginx, dans le répertoire courant) et des paramètres supplémentaires propres à ce container, en l’occurrence son port et son protocole sur un réseau TCP/IP, nginx étant un serveur web.
Il est possible de déployer un pod plus directement avec la fonction run suivie de paramètres. Par exemple :
kubectl run nicepod --image=nginxDans les deux cas, on pourra vérifier que le pod est actif avec la commande kubectl get pods qui liste tous les pods en cours de fonctionnement. Si la fonction run est bien plus rapide à taper que la procédure avec apply, on notera tout de même qu’avoir un fichier descriptif est utile en cas d’audit et pour automatiser les mises à jour suivantes. La bonne pratique consiste à stocker les fichiers descriptifs sur un dépôt qui gère les versions successives, comme git ou github.
Généralement, on déploie un pod en plusieurs exemplaires, pour répartir la charge de travail. Cela se fait avec trois commandes. La première sert à créer un « déploiement », c’est-à-dire un jeu de plusieurs pods redondants. La seconde sert à préciser le nombre d’instances redondantes. La troisième, enfin, active la répartition de charge entre les pods redondants :
kubectl create deploy cooldeploy --image nginx
kubectl scale --replicas=3 deployment/cooldeploykubectl expose deployment cooldeploy --port=8080 --target-port=80 --type=LoadBalancerDans la troisième ligne, la fonction expose crée un service qui expose sur le réseau une ressource de type deployment, dont le nom est cooldeploy, avec des options. Les options de cette fonction expose comprennent elles-mêmes un --type.
D’autres usages courants de Kubectl
Pour décommissionner des services, on utilise la fonction delete. Ainsi, la commande kubectl delete pods --all supprimera tous les pods. Il est généralement plus souhaitable – et plus sûr – d’utiliser les types et les noms spécifiés dans un fichier YAML séparé pour supprimer un pod.
Par exemple, si un administrateur crée un pod avec le fichier testpod1.yaml, il peut supprimer ce même pod avec la commande kubectl delete -f testpod1.yaml. Kubectl peut également supprimer des pods et des services qui partagent un label spécifique, précédemment assigné avec l’opération kubectl label. Par exemple, la commande kubectl delete pods,services -l name=testbed1 supprime tous les pods et services portant le label testbed1.
Pour exécuter un applicatif au sein d’un pod, ou même d’un container, on utilise la fonction exec. Par exemple, la commande kubectl exec mypod date exécutera la commande date sur le pod appelé mypod et affichera sa sortie. La commande s’exécute par défaut sur le premier container du pod. Autre exemple, la commande kubectl exec mypod -c container1 date exécute la commande date dans le container nommé container1 au sein du pod nommé mypod et affiche ensuite la sortie.
Enfin, on utilise la fonction logs pour afficher les journaux des pods indiqués. Par exemple, la commande kubectl logs pod1 affiche les journaux du premier container du pod nommé pod1. Si le pod exécute plusieurs containers, la commande kubectl logs pod1 --all-containers=true génère des journaux pour tous les containers du pod. La fonction logs permet également aux utilisateurs d’obtenir les journaux des containers qui portent des étiquettes spécifiques. Par exemple, la commande kubectl logs -lapp=tests --all-containers=true renvoie les journaux de tous les containers portant l’étiquette tests, précédemment appliquée avec la fonction label.
Quelques astuces d’administration de Kubernetes
Voici une liste d’astuces qui permettent de mieux administrer un cluster Kubernetes.
Exécuter un pod « démon » sur chaque nœud. Cela est possible grâce au type DaemonSet. Un DaemonSet est un objet API dans lequel une copie d’un pod donné est exécutée sur chaque nœud d’un cluster Kubernetes. La journalisation est un bon exemple de l’utilité d’un DaemonSet. Un système de journalisation utilise généralement une application appelée collecteur pour rassembler toutes les informations de journalisation générées sur chaque machine, puis transmet ces informations à un emplacement central où elles sont agrégées. La configuration d’un collecteur de journaux en tant que DaemonSet Kubernetes garantit que le collecteur est installé sur chaque nœud.
Exécuter un pod sur un nœud spécifique. Par défaut, Kubernetes décide tout seul sur quel serveur il déploie un nouveau pod, en tenant compte de la charge actuelle de chacun des serveurs. Pour obliger un pod à se déployer sur un serveur de travail en particulier, il suffit d’attribuer un label à ce serveur, puis, dans la rubrique spec du fichier YAML qui décrit le pod, de paramétrer la rubrique nodeAffinity de sorte qu’elle pointe sur ce label.
Exécuter un container init en premier dans un pod. Un container init est un container que Kubernetes exécute avant que les autres containers d’un pod ne soient créés. L’exemple ci-dessous montre comment créer un container init qui attend qu’un service de base de données soit en ligne avant de créer le container qui utilisera la base de données.
apiVersion: v1kind: Podmetadata: name: myapp-pod labels: app: myappspec: containers: - name: myapp-container image: busybox:1.31 command: ['sh', '-c', 'echo The app is running! && sleep 3600'] initContainers: - name: init-myservice image: busybox:1.31 command: ['sh', '-c', 'until nslookup redis-master; do echo waiting for redis-master; sleep 2; done;']Accompagner un container applicatif d’un side-car. Dans un modèle de sidecar, un container est créé dans un pod pour fournir un service à un autre container dans ce pod. Le container sidecar fonctionne sur la même machine et sous la même adresse IP que tous les autres containers qui fonctionnent dans le pod. Il est donc très efficace de déplacer le trafic entre le container principal et le container sidecar. Le sidecar fournit des fonctionnalités étendues au container principal tout en étant indépendant ; de sorte qu’il permet des mises à jour sans arrêter le container principal.
Lorsque vous avez besoin de fournir des fonctionnalités ou des services supplémentaires à un container de manière polyvalente et avec une faible latence, le modèle sidecar est une bonne solution.
Déployer des pods qui conservent leurs données. Pour qu’un pod sauvegarde son état sur disque (comprendre avec les données qu’il a créées depuis son démarrage) de sorte que cet état puisse être restauré dans un pod similaire en cas de défaillance, il faut utiliser le type StatefulSet. En pratique, StatefulSet est similaire au type deployment, dans le sens où l’on définit une collection de plusieurs pods.
Pour approfondir sur Linux
-
![]()
Administration Kubernetes : ScaleOps chasse les ressources gaspillées
Par: Yann Serra
-
![]()
Administration : les clés de la mise en réseau des containers
Par: Wisdom Ekpotu
-
![]()
Comment déployer (simplement) Redis sur Kubernetes
Par: Chris Tozzi
-
![]()
Administration Kubernetes : les 5 dépannages à connaître
Par: Chris Tozzi



