Tutoriel MLOps : les premiers pas avec Kubeflow
Pour les équipes qui exécutent des flux de travail de machine learning avec Kubernetes, l’utilisation de Kubeflow peut conduire à des déploiements plus rapides et plus fluides. Commencez avec ce guide d’installation.

Vous n’êtes pas obligé d’utiliser Kubernetes pour mettre en œuvre des déploiements de modèles de machine learning. Mais si vous le faites – et il y a de nombreuses raisons de le faire –, Kubeflow est le moyen le plus simple et le plus rapide.
Kubeflow est un outil open source développé à l’origine par Google qui rationalise le déploiement de flux de travail de machine learning au-dessus de Kubernetes. L’objectif principal de Kubeflow est de simplifier la mise en place d’environnements pour construire, tester, entraîner et exploiter des modèles et des applications ML pour les équipes de data science et de MLOps.
Il est possible de déployer des frameworks tels que TensorFlow et PyTorch sur un cluster Kubernetes directement sans utiliser Kubeflow. Toutefois, Kubeflow automatise une grande partie du processus nécessaire à la mise en place et au fonctionnement de ces outils. Afin de décider si c’est le bon choix pour vos projets de machine learning, découvrez comment fonctionne Kubeflow, quand l’utiliser et comment l’installer.
Les avantages et les inconvénients de Kubernetes et de Kubeflow pour le machine learning
Avant de décider d’utiliser Kubeflow en particulier, il est important de comprendre les avantages et les inconvénients de l’exécution de flux de travail d’IA et d’apprentissage automatique sur Kubernetes en général.
Faut-il exécuter des modèles d’apprentissage automatique sur Kubernetes ?
En tant que plateforme d’hébergement de flux d’apprentissage automatique, Kubernetes offre plusieurs avantages.
Le premier est l’évolutivité. Avec Kubernetes, vous pouvez facilement ajouter ou supprimer des nœuds d’un cluster pour en modifier les ressources totales disponibles. Ceci est particulièrement avantageux pour les charges de travail d’apprentissage automatique, dont les exigences en matière de consommation de ressources peuvent fluctuer de manière significative. Par exemple, vous pourriez vouloir augmenter l’échelle de votre cluster pendant l’entraînement du modèle, qui nécessite généralement beaucoup de ressources, puis l’arrêter en attendant les phases de réentraînement.
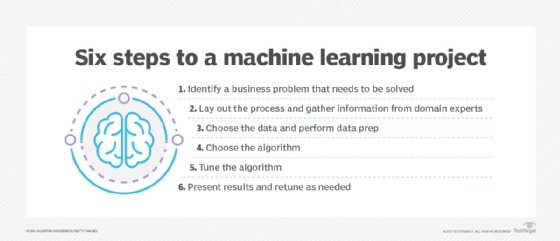
L’hébergement de workflows d’apprentissage automatique sur Kubernetes offre également l’avantage de permettre aux conteneurs d’accéder à du matériel bare-metal. Cela permet d’accélérer les performances de vos charges de travail à l’aide de GPU ou d’autres composants qui ne seraient pas accessibles sur une infrastructure virtuelle. Bien que vous puissiez accéder à une infrastructure bare-metal sans utiliser Kubernetes, en exécutant des charges de travail dans des conteneurs autonomes, l’orchestration de conteneurs avec Kubernetes facilite la gestion des charges de travail à l’échelle.
À l’inverse, l’une des raisons principales d’éviter Kubernetes est qu’il ajoute une couche de complexité supplémentaire à votre pile logicielle. Pour les petites charges de travail, un déploiement basé sur Kubernetes peut s’avérer excessif. Dans de telles situations, le recours direct à des VM dans le cloud ou des serveurs bare-metal peut s’avérer plus judicieux.
Quand choisir Kubeflow ?
Le principal avantage de l’utilisation de Kubeflow pour l’apprentissage automatique est la rapidité et la simplicité du processus de déploiement de l’outil. Avec seulement quelques commandes kubectl, vous obtenez un environnement prêt à l’emploi où vous pouvez commencer à déployer des workflows d’apprentissage automatique.
Kubeflow inclut six grandes familles de composants : les pipelines, les notebooks (des notebooks RStudio, Jupyter et Visual Studio Code exécutés sur les pods attenants à Kubeflow), un tableau de bord, une fonction AutoML assurée par le projet Katib, un opérateur d’entraînement (compatible avec TensorFlow, PyTorch, MPI, MXnet, PaddlePaddle et XGBoost) et une brique de « serving », de déploiement des modèles en production, assuré par le projet KServe (en option il est possible de passer par Seldon Core, BentoML, MLRun Serving, Nvidia Triton, TF Serving ou TF Batch Prediction). Par ailleurs, Kubeflow est compatible avec MinIO, la technologie de stockage objet, elle-même proche d’Amazon S3.
D’un autre côté, Kubeflow vous limite aux outils et frameworks qu’il prend en charge et peut inclure certaines ressources que vous n’utiliserez pas en fin de compte. Si vous n’avez besoin que d’un ou deux outils d’apprentissage automatique spécifiques, vous trouverez peut-être plus simple de les déployer individuellement plutôt qu’avec Kubeflow. Mais pour tous ceux qui ont besoin d’un environnement de machine learning polyvalent sur Kubernetes, il est difficile d’argumenter contre l’utilisation de Kubeflow.
Tutoriel Kubeflow : Installation et configuration
Sur la plupart des distributions Kubernetes, l’installation de Kubeflow se résume à quelques commandes.
Ce tutoriel présente le processus en utilisant K3s, une distribution Kubernetes légère que vous pouvez exécuter sur un ordinateur portable ou un PC, mais vous devriez être en mesure de suivre les mêmes étapes sur n’importe quelle plateforme Kubernetes courante. D’ailleurs, la documentation de Kubeflow redirige les utilisateurs vers les versions prises en charge par AWS, Canonical, GCP, Azure, Nutanix, Red Hat (Openshift), VMware (vSphere) et Aranui Solutions.
Étape 1. Créer un cluster Kubernetes
Commencez par créer un cluster Kubernetes si vous n’en avez pas déjà un en cours d’exécution. Pour mettre en place un cluster à l’aide de K3s, téléchargez d’abord K3s à l’aide de la commande suivante.
curl -sfL https://get.k3s.io | sh -
Ensuite, exécutez la commande ci-dessous pour démarrer un cluster.
sudo k3s server &
Pour vérifier que tout fonctionne comme prévu, exécutez la commande ci-dessous.
sudo k3s kubectl get node
Le résultat devrait ressembler à ceci :
NAME STATUS ROLES AGE VERSION chris-gazelle Ready control-plane,master 2m7s v1.25.7+k3s1
Étape 2. Installer Kubeflow
Une fois votre cluster opérationnel, l’étape suivante consiste à installer Kubeflow.
Utilisez les commandes suivantes pour le faire sur une machine locale utilisant K3s.
sudo -s
export PIPELINE_VERSION=1.8.5
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-pns?ref=$PIPELINE_VERSION"
Si vous installez Kubeflow sur un cluster Kubernetes non local, les commandes ci-dessous fonctionneront dans la plupart des cas.
export PIPELINE_VERSION=<kfp-version-between-0.2.0-and-0.3.0>
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/base/crds?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
Étape 3. Vérifier que les conteneurs fonctionnent
Même après avoir installé Kubeflow, il n’est pas complètement opérationnel tant que tous les conteneurs qui le composent ne sont pas en cours d’exécution. Vérifiez l’état de vos conteneurs avec la commande suivante.
kubectl get pods -n kubeflow
Si les conteneurs ne fonctionnent pas correctement après plusieurs minutes, consultez leurs logs pour en déterminer la cause.
Étape 4. Commencer à utiliser Kubeflow
Kubeflow fournit un tableau de bord web pour créer et déployer des pipelines. Pour accéder à ce tableau de bord, assurez-vous d’abord que la redirection de port est correctement configurée en exécutant la commande ci-dessous.
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80
Si vous exécutez Kubeflow localement, vous pouvez accéder au tableau de bord en ouvrant un navigateur web à l’URL http://localhost/8080. Si vous avez installé Kubeflow sur une machine distante, remplacez localhost par l’adresse IP ou le nom d’hôte du serveur sur lequel vous exécutez Kubeflow. Il faudra tout de même déployer le SDK Python ou le mettre à jour et déployer un notebook avant de commencer. Les pipelines eux-mêmes dépendent de scripts Python préinstallés. Notons que les pipelines peuvent être bâtis à partir du CLI de Kubeflow.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
Gestion multicluster avec Kubernetes : Mirantis confie deux projets à la CNCF
Par: Gaétan Raoul
-
![]()
Comment déployer (simplement) Redis sur Kubernetes
Par: Chris Tozzi
-
![]()
Administration Kubernetes : les 5 dépannages à connaître
Par: Chris Tozzi
-
![]()
AIOps : quand l’IA générative s’invite dans la supervision de Kubernetes
Par: Gaétan Raoul


