Qu'est-ce qu'un algorithme d'apprentissage automatique ? 12 types expliqués
Un algorithme d'apprentissage automatique est la méthode par laquelle le système d'intelligence artificielle accomplit sa tâche, généralement en prédisant les valeurs de sortie à partir de données d'entrée données. Les deux principaux processus impliqués dans les algorithmes d'apprentissage automatique (ML) sont la classification et la régression.
Un algorithme de ML est un ensemble de processus ou de techniques mathématiques par lesquels un système d'intelligence artificielle (IA) effectue ses tâches. Ces tâches consistent notamment à glaner des informations importantes, des modèles et des prédictions sur l'avenir à partir des données d'entrée sur lesquelles l'algorithme est entraîné. Un professionnel de la science des données alimente un algorithme de ML en données d'entraînement afin qu'il puisse apprendre à partir de ces données pour améliorer ses capacités de prise de décision et produire les résultats souhaités.
Le ML est un sous-ensemble de l'IA et de l'informatique. Son utilisation s'est développée ces dernières années en même temps que d'autres domaines de l'IA, tels que les algorithmes d'apprentissage profond (deep learning) utilisés pour les données volumineuses (big data) et le traitement du langage naturel (natural language processing) pour la reconnaissance vocale. L'importance des algorithmes de ML réside dans leur capacité à passer au crible des milliers de points de données pour produire des résultats d'analyse de données plus efficacement que les humains.

Comment fonctionnent les algorithmes de ML
Un data scientist ou un analyste transmet des ensembles de données à un algorithme de ML et lui demande d'examiner des variables spécifiques afin d'identifier des modèles ou de faire des prédictions. L'idée est que l'algorithme apprenne au fil du temps et de manière autonome. Plus il analyse de données, plus il devient capable de faire des prédictions précises sans être explicitement programmé pour le faire, comme le feraient les humains.
Ces données d'apprentissage sont également appelées données d'entrée. La classification des données ou les prédictions produites par l'algorithme sont appelées sorties. Les développeurs et les experts en données qui construisent des modèles de ML doivent sélectionner les bons algorithmes en fonction des tâches qu'ils souhaitent accomplir. Par exemple, certains algorithmes se prêtent à des tâches de classification qui conviendraient à des diagnostics de maladies dans le domaine médical. D'autres sont idéaux pour les prédictions requises dans les transactions boursières et les prévisions financières.
Algorithmes supervisés et non supervisés
La plupart des algorithmes de ML sont classés en deux grandes catégories : supervisés et non supervisés. La différence fondamentale entre les algorithmes d'apprentissage supervisé et non supervisé réside dans la manière dont ils traitent les données. Les algorithmes semi-supervisés et les algorithmes de renforcement constituent deux autres catégories.
Algorithmes supervisés
Ces algorithmes traitent des données clairement étiquetées, sous la supervision directe d'un scientifique des données. Les données d'entrée et les données de sortie souhaitées leur sont fournies par le biais de l'étiquetage.
Les algorithmes supervisés ont généralement deux objectifs : la classification ou la régression. Dans les problèmes de classification, un algorithme peut classer avec précision des données différentes dans des catégories spécifiques (chiens et chats, par exemple), ce qui devient possible avec des données étiquetées.
Il existe de nombreux cas d'utilisation dans le monde réel pour les algorithmes supervisés, notamment les soins de santé et les diagnostics médicaux, ainsi que la reconnaissance d'images. Dans les deux cas, une classification des données est nécessaire.
Dans les problèmes de régression, un algorithme est utilisé pour prédire la probabilité qu'un événement se produise - connu sous le nom de variable dépendante - sur la base de connaissances et d'observations préalables à partir de données d'entraînement - les variables indépendantes. Parmi les cas d'utilisation des algorithmes de régression, on peut citer les prévisions de séries temporelles utilisées dans le domaine des ventes.
Données non supervisées
Les algorithmes non supervisés traitent des données non classées et non étiquetées. Ils fonctionnent donc différemment des algorithmes supervisés. Par exemple, les algorithmes de regroupement sont un type d'algorithme non supervisé utilisé pour regrouper des données non triées en fonction des similitudes et des différences, compte tenu de l'absence d'étiquettes.
Les algorithmes non supervisés peuvent également être utilisés pour identifier des associations, ou des connexions et des relations intéressantes, entre les éléments d'un ensemble de données. Par exemple, ces algorithmes peuvent déduire qu'un groupe de personnes qui achètent un certain produit achètent également certains autres produits.
Algorithmes semi-supervisés
Cependant, de nombreuses techniques d'apprentissage automatique peuvent être décrites de manière plus précise comme semi-supervisées, où des données étiquetées et non étiquetées sont utilisées.
Algorithmes de renforcement
Les algorithmes de renforcement - qui utilisent des techniques d'apprentissage par renforcement - sont considérés comme une quatrième catégorie. Leur approche unique est basée sur la récompense des comportements souhaités et la punition des comportements non souhaités afin de diriger l'entité formée à l'aide de récompenses et de pénalités.
Types d'algorithmes d'apprentissage automatique
Il existe plusieurs types d'algorithmes d'apprentissage automatique, dont les suivants :
1. Régression linéaire
Un algorithme de régression linéaire est un algorithme supervisé utilisé pour prédire des valeurs numériques continues qui fluctuent ou changent au fil du temps. Il peut apprendre à prédire avec précision des variables telles que l'âge ou les chiffres de vente sur une période donnée.
2. Régression logistique
Dans l'analyse prédictive, un algorithme d'apprentissage automatique fait généralement partie d'une modélisation prédictive qui utilise des connaissances et des observations antérieures pour prédire la probabilité d'événements futurs. Les régressions logistiques sont également des algorithmes supervisés qui se concentrent sur des classifications binaires comme résultats, tels que "oui" ou "non".
3. Arbre de décision
Il s'agit d'un algorithme d'apprentissage supervisé utilisé pour les problèmes de classification et de régression. Les arbres de décision divisent les ensembles de données en différents sous-ensembles à l'aide d'une série de questions ou de conditions qui déterminent à quel sous-ensemble appartient chaque élément de données. Lorsqu'elles sont tracées, les données semblent être divisées en branches, d'où l'utilisation du mot "arbre".
4. Machine vectorielle de soutien (SVM)
Les SVM sont utilisés pour la classification, la régression et la détection d'anomalies dans les données. Un SVM s'applique le mieux aux classifications binaires, où les éléments d'un ensemble de données sont classés en deux groupes distincts.
5. Naïve Bayes
Cet algorithme effectue des classifications et des prédictions. Cependant, il s'agit de l'un des algorithmes d'apprentissage supervisé les plus simples et il suppose que toutes les caractéristiques des données d'entrée sont indépendantes les unes des autres ; un point de données n'aura pas d'incidence sur un autre lors de l'élaboration des prédictions.
6. Forêt aléatoire
Ces algorithmes combinent plusieurs arbres décisionnels de données non liées, organisant et étiquetant les données à l'aide de méthodes de régression et de classification.
7. K-means
Cet algorithme d'apprentissage non supervisé identifie des groupes de données dans des ensembles de données non étiquetées. Il regroupe les données non étiquetées en différents groupes ; c'est l'un des algorithmes de regroupement les plus populaires.
8. K-voisins les plus proches
Les KNN classent les éléments de données en fonction de leur proximité ou de leur similarité. Le groupe de données existant qui ressemble le plus à un nouvel élément de données est celui avec lequel cet élément sera regroupé.
9. Réseaux neuronaux artificiels
Les ANN, ou simplement les réseaux neuronaux, sont des groupes d'algorithmes qui reconnaissent des modèles dans les données d'entrée à l'aide de blocs de construction appelés neurones. Ces neurones ressemblent vaguement aux neurones du cerveau humain. Ils sont formés et modifiés au fil du temps grâce à des méthodes de formation supervisées.
10. Réduction de la dimensionnalité
Lorsqu'un ensemble de données comporte un grand nombre de caractéristiques, on dit qu'il a une dimensionnalité élevée. La réduction de la dimensionnalité consiste à diminuer le nombre de caractéristiques afin de ne conserver que les informations les plus significatives. L'analyse en composantes principales est un exemple de cette méthode.
11. Renforcement du gradient
Cet algorithme d'optimisation réduit la fonction de coût d'un réseau neuronal, qui mesure la taille de l'erreur produite par le réseau lorsque sa sortie réelle s'écarte de la sortie prévue.
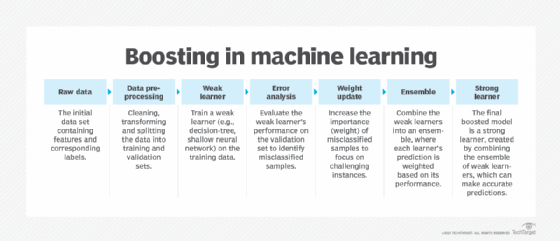
12. AdaBoost
Également appelée boosting adaptatif, cette technique d'apprentissage supervisé augmente les performances d'un algorithme de classification ou de régression ML peu performant en le combinant avec des algorithmes plus faibles pour former un algorithme plus fort qui produit moins d'erreurs.
Les scientifiques des données doivent comprendre la préparation des données en tant que précurseur de l'alimentation des ensembles de données aux modèles d'apprentissage automatique pour l'analyse. Découvrez les six étapes du processus de préparation des données.







