Qu'est-ce que le data mining ?
Le data mining consiste à trier de grands ensembles de données afin d'identifier des modèles et des relations pouvant aider à résoudre des problèmes commerciaux grâce à l'analyse des données. Les techniques et les outils de data mining aident les entreprises à prévoir les tendances futures et à prendre des décisions commerciales plus éclairées.
L'exploration de données est un élément clé de l'analyse de données et l'une des disciplines fondamentales de la science des données, qui utilise des techniques d'analyse avancées pour trouver des informations utiles dans des ensembles de données. À un niveau plus granulaire, l'exploration de données est une étape du processus de découverte de connaissances dans les bases de données (KDD), une méthodologie de science des données pour la collecte, le traitement et l'analyse des données. L'exploration de données et le KDD sont parfois utilisés de manière interchangeable, mais ils sont plus souvent considérés comme deux choses distinctes.
Le processus d'exploration de données repose sur la mise en œuvre efficace de la collecte, du stockage et du traitement des données. L'exploration de données peut être utilisée pour décrire un ensemble de données cible, prédire des résultats, détecter des fraudes ou des problèmes de sécurité, en savoir plus sur une base d'utilisateurs ou détecter des goulots d'étranglement et des dépendances. Elle peut également être effectuée de manière automatique ou semi-automatique.
Le data mining est aujourd'hui plus utile que jamais en raison de la croissance du big data et du stockage de données. Les spécialistes des données qui utilisent le data mining doivent avoir une expérience en codage et en langage de programmation, ainsi que des connaissances en statistiques pour nettoyer, traiter et interpréter les données.
Pourquoi l'exploration de données est-elle importante ?
L'exploration de données est un élément essentiel à la réussite des initiatives analytiques dans les organisations. Les spécialistes des données peuvent utiliser les informations qu'elle génère dans des applications de veille économique (BI) et d'analyse avancée qui impliquent l'analyse de données historiques, ainsi que dans des applications d'analyse en temps réel qui examinent les données en continu au fur et à mesure qu'elles sont créées ou collectées.
Une exploration efficace des données facilite divers aspects de la planification des stratégies commerciales et de la gestion des opérations. Cela inclut les fonctions en contact avec la clientèle, telles que le marketing, la publicité, les ventes et le service client, ainsi que la fabrication, la gestion de la chaîne d'approvisionnement (SCM), les finances et les ressources humaines (RH). L'exploration des données facilite la détection des fraudes, la gestion des risques, la planification de la cybersécurité et de nombreux autres cas d'utilisation critiques dans le domaine des affaires. Elle joue également un rôle important dans d'autres domaines, notamment les soins de santé, l'administration publique, la recherche scientifique, les mathématiques et le sport.
Le processus d'exploration de données : comment fonctionne l'exploration de données ?
Les data scientists et autres professionnels qualifiés en BI et en analyse de données effectuent généralement le data mining. Mais les analystes commerciaux, les cadres et les employés familiarisés avec les données qui agissent en tant que data scientists citoyens au sein d'une organisation peuvent également effectuer du data mining.
Les éléments fondamentaux du data mining comprennent l'apprentissage automatique et l'analyse statistique, ainsi que les tâches de gestion des données effectuées pour préparer les données en vue de leur analyse. L'utilisation d'algorithmes d'apprentissage automatique et d'outils d'intelligence artificielle (IA) a permis d'automatiser davantage le processus. Ces outils ont également facilité l'exploitation d'ensembles de données massifs, tels que les bases de données clients, les enregistrements de transactions et les fichiers journaux provenant de serveurs web, d'applications mobiles et de capteurs.
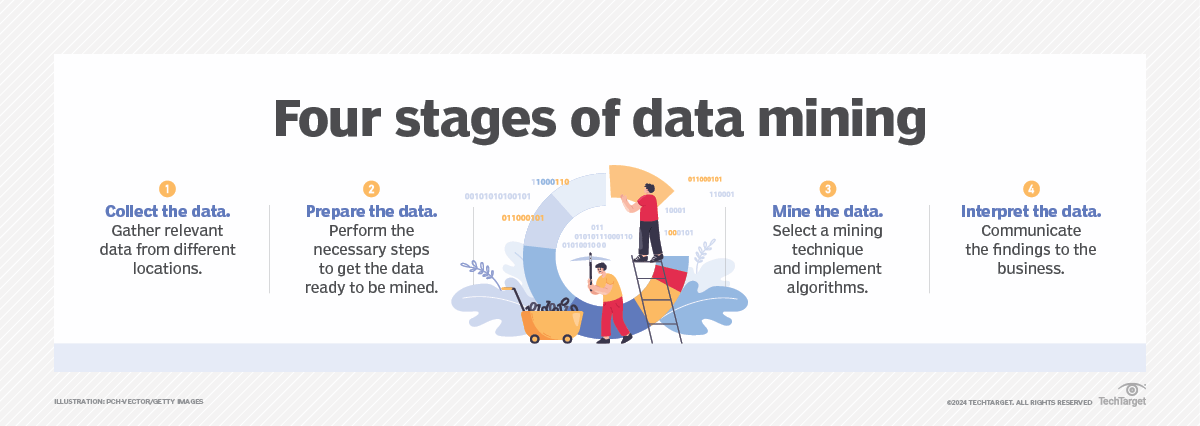
Bien que le nombre d'étapes puisse varier en fonction du niveau de détail souhaité par l'organisation pour chaque étape, le processus d'exploration de données peut généralement être divisé en quatre étapes principales :
- Collecte de données. Identifier et rassembler les données pertinentes pour une application analytique. Les données peuvent se trouver dans différents systèmes sources, un entrepôt de données ou un lac de données, un référentiel de plus en plus courant dans les environnements Big Data qui contiennent un mélange de données structurées et non structurées. Des sources de données externes peuvent également être utilisées. Quelle que soit la provenance des données, un data scientist les transfère souvent vers un lac de données pour les étapes restantes du processus.
- Préparation des données. Cette étape comprend une série d'opérations visant à préparer les données en vue de leur exploitation. La préparation des données commence par leur exploration, leur profilage et leur prétraitement, puis se poursuit par leur nettoyage afin de corriger les erreurs et autres problèmes liés à leur qualité, tels que les doublons ou les valeurs manquantes. La transformation des données est également effectuée afin d'assurer la cohérence des ensembles de données, sauf si un data scientist souhaite analyser des données brutes non filtrées pour une application particulière.
- Exploration de données. Une fois les données préparées, un data scientist choisit la technique d'exploration de données appropriée, puis met en œuvre un ou plusieurs algorithmes pour effectuer l'exploration. Ces techniques peuvent, par exemple, analyser les relations entre les données et détecter des modèles, des associations et des corrélations. Dans les applications d'apprentissage automatique, les algorithmes doivent généralement être entraînés sur des ensembles de données échantillons afin de rechercher les informations souhaitées avant d'être exécutés sur l'ensemble complet des données.
- Analyse et interprétation des données. Les résultats de l'exploration des données sont utilisés pour créer des modèles analytiques qui peuvent aider à prendre des décisions et à mener d'autres actions commerciales. Le data scientist ou un autre membre de l'équipe de science des données doit également communiquer les résultats aux dirigeants et aux utilisateurs, souvent par le biais de la visualisation des données et de l'utilisation de techniques de narration des données.
Types de techniques d'exploration de données
Diverses techniques peuvent être utilisées pour extraire des données à des fins d'applications scientifiques. La reconnaissance de formes est un cas d'utilisation courant du data mining, tout comme la détection d'anomalies, qui permet d'identifier les valeurs aberrantes dans les ensembles de données. Parmi les techniques de data mining les plus courantes, on peut citer les suivantes :
- Exploration des règles d'association. Dans l'exploration de données, les règles d'association sont des déclarations « si-alors » qui identifient les relations entre les éléments de données. Les critères de support et de confiance sont utilisés pour évaluer ces relations. Le support mesure la fréquence à laquelle les éléments liés apparaissent dans un ensemble de données, tandis que la confiance reflète le nombre de fois où une déclaration « si-alors » est exacte.
- Classification. Cette approche attribue les éléments des ensembles de données à différentes catégories définies dans le cadre du processus d'exploration de données. Les arbres de décision, les classificateurs naïfs de Bayes, les k plus proches voisins (KNN) et la régression logistique sont des exemples de méthodes de classification.
- Regroupement. Dans ce cas, les éléments de données qui partagent des caractéristiques particulières sont regroupés en clusters dans le cadre d'applications d'exploration de données. Parmi les exemples, on peut citer le regroupement par la méthode des k-moyennes, le regroupement hiérarchique et les modèles de mélange gaussien.
- Régression. Cette méthode permet de trouver des relations dans des ensembles de données en calculant des valeurs prédites à partir d'un ensemble de variables. La régression linéaire et la régression multivariée en sont des exemples. Les arbres de décision et d'autres méthodes de classification peuvent également être utilisés pour effectuer des régressions.
- Analyse des séquences et des chemins. Les données peuvent également être exploitées pour rechercher des modèles dans lesquels un ensemble particulier d'événements ou de valeurs conduit à d'autres événements ou valeurs ultérieurs.
- Réseaux neuronaux. Un réseau neuronal est un ensemble d'algorithmes qui simule l'activité du cerveau humain, où les données sont traitées à l'aide de nœuds. Les réseaux neuronaux sont particulièrement utiles dans les applications complexes de reconnaissance de formes impliquant l'apprentissage profond, une branche plus avancée de l'apprentissage automatique.
- Arbres de décision. Ce processus classe ou prédit les résultats potentiels à l'aide de méthodes de classification ou de régression. Des structures arborescentes sont utilisées pour représenter les résultats potentiels des décisions.
- KNN. Cette méthode d'exploration de données classe les données en fonction de leur proximité avec d'autres points de données. En partant du principe que les points de données proches sont plus similaires entre eux que les autres points de données, KNN est utilisé pour prédire les caractéristiques d'un groupe.
Logiciels et outils d'exploration de données
De nombreux fournisseurs proposent des outils d'exploration de données, généralement dans le cadre de plateformes logicielles qui comprennent également d'autres types d'outils de science des données et d'analyse avancée. Les logiciels d'exploration de données offrent des fonctionnalités clés, notamment des capacités de préparation des données, des algorithmes intégrés, une prise en charge de la modélisation prédictive, un environnement de développement basé sur une interface utilisateur graphique et des outils permettant de déployer des modèles et d'évaluer leurs performances.
Voici quelques exemples de fournisseurs proposant des outils pour l'exploration de données : Alteryx, Dataiku, H2O.ai, IBM, Knime, Microsoft, Oracle, RapidMiner, SAP, SAS Institute et Tibco Software.
Diverses technologies open source gratuites peuvent également être utilisées pour extraire des données, notamment DataMelt, Elki, Orange, Rattle, scikit-learn et Weka. Certains éditeurs de logiciels proposent également des options open source. Par exemple, Knime combine une plateforme d'analyse open source avec un logiciel commercial pour la gestion des applications de science des données, tandis que des entreprises telles que Dataiku et H2O.ai proposent des versions gratuites de leurs outils.
Avantages de l'exploration de données
En général, les avantages commerciaux du data mining proviennent de la capacité accrue d'une organisation à découvrir des modèles, des tendances, des corrélations et des anomalies cachés dans des ensembles de données. Elle peut utiliser ces informations pour améliorer la prise de décision commerciale et la planification stratégique en combinant l'analyse de données conventionnelle et l'analyse prédictive.
Les avantages spécifiques du data mining sont les suivants :
- Marketing et ventes plus efficaces. L'exploration de données aide les spécialistes du marketing à mieux comprendre le comportement et les préférences des clients, ce qui leur permet de créer des campagnes marketing et publicitaires ciblées. De même, les équipes commerciales peuvent utiliser les résultats de l'exploration de données pour améliorer les taux de conversion des prospects et vendre des produits et services supplémentaires aux clients existants.
- Meilleur service client. L'exploration de données aide les entreprises à identifier plus rapidement les problèmes potentiels liés au service client et à fournir aux agents des centres de contact des informations à jour à utiliser lors des appels et des discussions en ligne avec les clients.
- SCM amélioré. Les organisations peuvent repérer les tendances du marché et prévoir la demande de produits avec plus de précision, ce qui leur permet de mieux gérer leurs stocks de marchandises et de fournitures. Les responsables de la chaîne d'approvisionnement peuvent également utiliser les informations issues de l'exploration de données pour optimiser l'entreposage, la distribution et d'autres opérations logistiques.
- Augmentation du temps de fonctionnement de la production. L'exploitation des données opérationnelles provenant des capteurs installés sur les machines de fabrication et autres équipements industriels facilite les applications de maintenance prédictive afin d'identifier les problèmes potentiels avant qu'ils ne surviennent, ce qui permet d'éviter les temps d'arrêt imprévus.
- Une gestion des risques plus efficace. Les gestionnaires des risques et les dirigeants d'entreprise peuvent mieux évaluer les risques financiers, juridiques, liés à la cybersécurité et autres auxquels une entreprise est exposée, et élaborer des plans pour les gérer.
- Réduction des coûts. L'exploration de données permet de réaliser des économies grâce à l'optimisation des processus opérationnels et à la réduction des redondances et du gaspillage dans les dépenses de l'entreprise.
En fin de compte, les initiatives de data mining peuvent générer une augmentation du chiffre d'affaires et des bénéfices, ainsi que des avantages concurrentiels qui permettent aux entreprises de se démarquer de leurs concurrents.
Exemples d'exploitation des données dans l'industrie
Les organisations des secteurs suivants utilisent l'exploration de données dans le cadre de leurs applications analytiques :
- Commerce de détail. Les détaillants en ligne exploitent les données clients et les historiques de navigation Internet pour cibler leurs campagnes marketing, leurs publicités et leurs offres promotionnelles sur chaque acheteur individuel. L'exploration de données et la modélisation prédictive alimentent également les moteurs de recommandation qui suggèrent des achats potentiels aux visiteurs des sites Web, ainsi que les activités d'inventaire et de gestion de la chaîne logistique.
- Services financiers. Les banques et les sociétés émettrices de cartes de crédit utilisent des outils d'exploration de données pour élaborer des modèles de risque financier, détecter les transactions frauduleuses et examiner les demandes de prêt et de crédit. L'exploration de données joue également un rôle clé dans le marketing et l'identification d'opportunités potentielles de vente incitative auprès des clients existants.
- Assurance. Les assureurs s'appuient sur l'exploration de données pour établir le prix des polices d'assurance et décider d'approuver ou non les demandes de souscription, ainsi que pour modéliser les risques et gérer les clients potentiels.
- Fabrication. Les applications d'exploration de données pour les fabricants comprennent des efforts visant à améliorer le temps de fonctionnement et l'efficacité opérationnelle des usines de production, les performances de la chaîne d'approvisionnement et la sécurité des produits.
- Divertissement. Les services de streaming analysent ce que les utilisateurs regardent ou écoutent et leur font des recommandations personnalisées en fonction de leurs habitudes. De même, les particuliers peuvent exploiter des logiciels d'exploration de données pour en savoir plus à leur sujet.
- Santé. L'exploration de données aide les médecins à diagnostiquer des pathologies, à traiter des patients et à analyser des radiographies et autres résultats d'imagerie médicale. La recherche médicale dépend également fortement de l'exploration de données, de l'apprentissage automatique et d'autres formes d'analyse.
- RH. Les services RH traitent généralement de grandes quantités de données. Cela inclut les données relatives à la fidélisation, aux promotions, aux salaires et aux avantages sociaux. L'exploration de données compare ces données afin d'améliorer les processus RH.
- Réseaux sociaux. Les entreprises de réseaux sociaux utilisent l'exploration de données pour collecter de grandes quantités d'informations sur les utilisateurs et leurs activités en ligne. Ces données sont utilisées de manière controversée soit pour la publicité ciblée, soit pour être vendues à des tiers.
Exploration de données vs analyse de données et entreposage de données
Le data mining est parfois considéré comme synonyme d'analyse de données. Mais il est principalement considéré comme un aspect spécifique de l'analyse de données qui automatise l'analyse de grands ensembles de données afin de découvrir des informations qui, autrement, ne pourraient être détectées. Ces informations peuvent ensuite être utilisées dans le processus de science des données et dans d'autres applications de BI et d'analyse.
Le stockage des données facilite les efforts d'exploration de données en fournissant des référentiels pour les ensembles de données. Traditionnellement, les données historiques étaient stockées dans des entrepôts de données d'entreprise ou dans des data marts plus petits, conçus pour des unités commerciales individuelles ou pour contenir des sous-ensembles de données spécifiques. Aujourd'hui, cependant, les applications d'exploration de données sont souvent alimentées par des lacs de données qui stockent à la fois des données historiques et des données en continu et qui s'appuient sur des plateformes de mégadonnées, telles que Hadoop et Spark, des bases de données NoSQL ou des services de stockage d'objets dans le cloud.
Historique et origines du data mining
Les technologies d'entreposage de données, d'informatique décisionnelle et d'analyse ont commencé à apparaître à la fin des années 1980 et au début des années 1990, améliorant ainsi la capacité des organisations à analyser les quantités croissantes de données qu'elles créaient et collectaient. Le terme « exploration de données » (data mining) a été utilisé pour la première fois en 1983 par l'économiste Michael Lovell et s'est généralisé en 1995, lors de la première conférence internationale sur la découverte de connaissances et l'exploration de données qui s'est tenue à Montréal.
Cet événement était parrainé par l'Association for the Advancement of Artificial Intelligence, qui a également organisé la conférence chaque année pendant les trois années suivantes. Depuis 1999, c'est principalement le Special Interest Group for Knowledge Discovery and Data Mining (groupe d'intérêt spécial pour la découverte de connaissances et l'exploration de données) au sein de l'Association for Computing Machinery qui organise la conférence ACM SIGKDD.
La revue technique Data Mining and Knowledge Discovery a publié son premier numéro en 1997. Elle paraît tous les deux mois et contient des articles évalués par des pairs sur les théories, les techniques et les pratiques du data mining et de la découverte de connaissances. Une autre publication évaluée par des pairs, l'American Journal of Data Mining and Knowledge Discovery, a été lancée en 2016.
Le data mining et le process mining peuvent tous deux aider les organisations à améliorer leurs performances. Mais comment ces technologies se comparent-elles ? Découvrez leurs similitudes et leurs différences.






