Qu'est-ce que le fractionnement des données ?

Le fractionnement des données consiste à diviser les données en deux ou plusieurs sous-ensembles. Généralement, dans le cas d'un fractionnement en deux parties, une partie est utilisée pour évaluer ou tester les données et l'autre pour entraîner le modèle.
Le fractionnement des données est un aspect important de la science des données, en particulier pour la création de modèles basés sur les données. Cette technique permet de garantir la précision des modèles de données et des processus qui utilisent ces modèles, tels que l'apprentissage automatique.
Comment fonctionne le fractionnement des données
Dans un fractionnement de données basique en deux parties, l'ensemble de données d'apprentissage est utilisé pour former et développer des modèles. Les ensembles d'apprentissage sont couramment utilisés pour estimer différents paramètres ou pour comparer les performances de différents modèles.
L'ensemble de données de test est utilisé une fois la formation terminée. Les données de formation et de test sont comparées afin de vérifier que le modèle final fonctionne correctement. Avec l'apprentissage automatique, les données sont généralement divisées en trois ensembles ou plus. Avec trois ensembles, l'ensemble supplémentaire est l'ensemble de développement, qui est utilisé pour modifier les paramètres du processus d'apprentissage.
Il n'existe pas de règle ni de critère précis pour déterminer comment les données doivent être divisées ; cela peut dépendre de la taille du pool de données d'origine ou du nombre de prédicteurs dans un modèle prédictif. Les organisations et les modélisateurs de données peuvent choisir de séparer les données divisées en fonction de méthodes d'échantillonnage des données, telles que les trois méthodes suivantes :
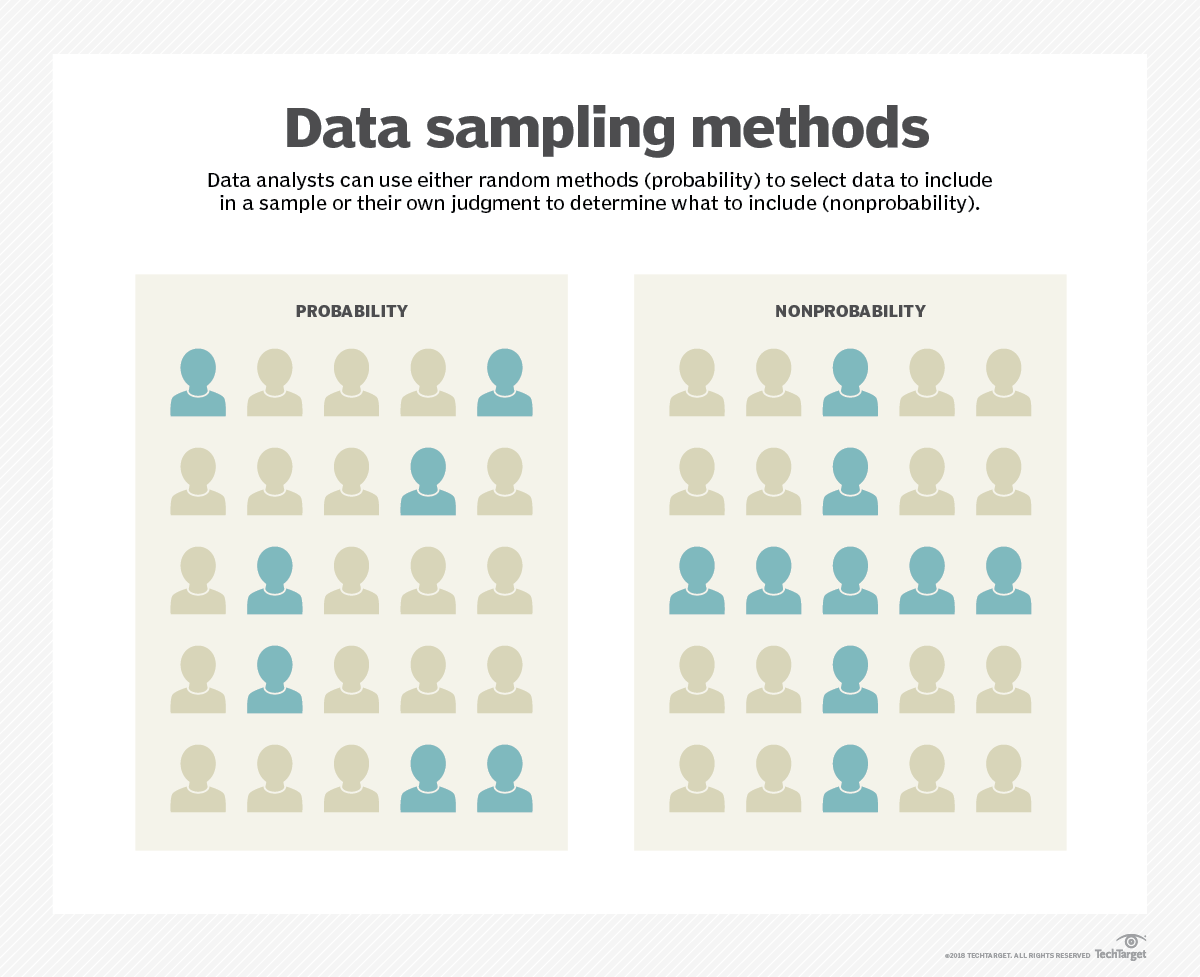
- Échantillonnage aléatoire. Cette méthode d'échantillonnage des données protège le processus de modélisation des données contre les biais liés aux différentes caractéristiques possibles des données. Cependant, le fractionnement aléatoire peut poser des problèmes liés à la répartition inégale des données.
- Échantillonnage aléatoire stratifié. Cette méthode sélectionne des échantillons de données au hasard selon des paramètres spécifiques. Elle garantit que les données sont correctement réparties dans les ensembles d'entraînement et de test.
- Échantillonnage non aléatoire. Cette approche est généralement utilisée lorsque les modélisateurs de données souhaitent utiliser les données les plus récentes comme ensemble de test.
Grâce au fractionnement des données, les organisations n'ont plus à choisir entre utiliser les données à des fins d'analyse ou d'analyse statistique, car les mêmes données peuvent être utilisées dans différents processus.
Utilisations courantes du fractionnement des données
Les données sont fractionnées notamment dans les cas suivants :
- Modélisation des données. Cette technique utilise le fractionnement des données pour entraîner les modèles. On en trouve un exemple dans la modélisation des tests de régression, où un développeur utilise un modèle pour prédire la réponse d'un système lorsqu'il est exploité avec des valeurs fictives. À partir de cet ensemble de valeurs, le développeur sélectionne une partie des données qui serviront de données d'entraînement. Il compare ensuite ces résultats aux données de test soumises au modèle de régression. Cela permet au développeur de se faire une idée de la précision du modèle.
- Apprentissage automatique. Cette technique utilise également le fractionnement des données pour entraîner les modèles. Les données d'entraînement sont ajoutées au modèle afin de mettre à jour ses paramètres de phase d'entraînement. Une fois la phase d'entraînement terminée, les données de l'ensemble de test sont comparées à la manière dont le modèle traite les nouvelles observations.
- Fractionnement cryptographique. Il s'agit d'un processus différent des utilisations du fractionnement des données mentionnées ci-dessus. Il s'agit d'une technique utilisée pour sécuriser les données sur un réseau informatique. Le fractionnement cryptographique vise à protéger les systèmes contre les failles de sécurité et consiste à crypter les données, à les fractionner en petits morceaux et à stocker ces morceaux dans différents emplacements de stockage. Les données sont à nouveau cryptées lorsqu'elles sont stockées dans leur nouvel emplacement.
Division des données dans l'apprentissage automatique
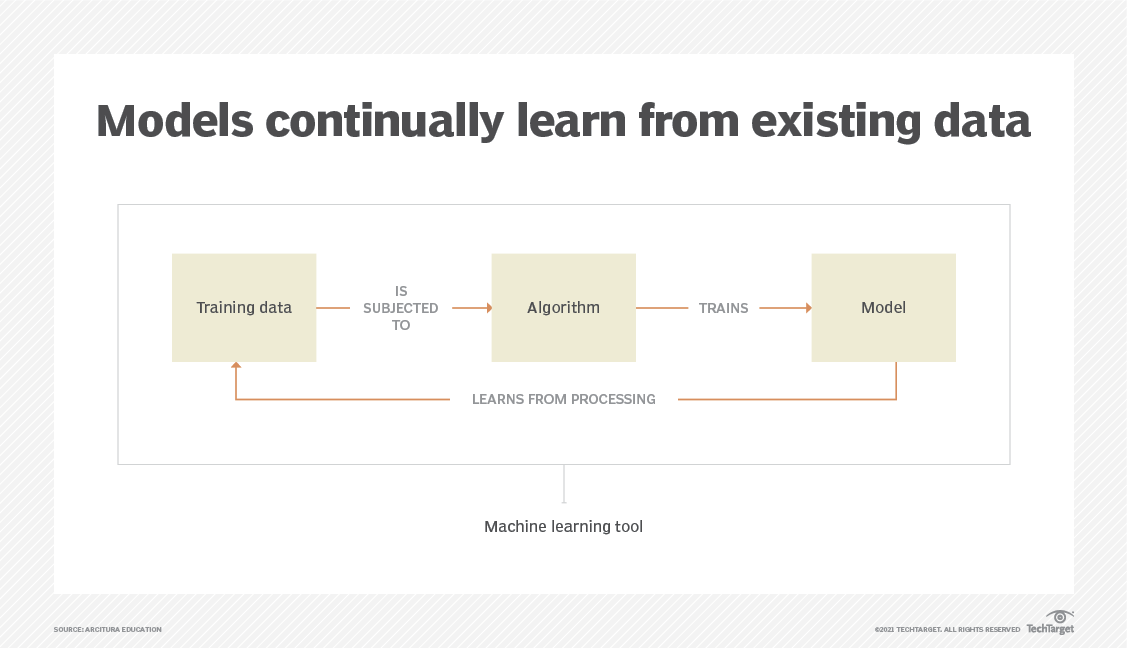
Dans l'apprentissage automatique, le fractionnement des données est généralement effectué pour éviter le surapprentissage. Il s'agit d'un cas où un modèle d'apprentissage automatique s'adapte trop bien à ses données d'entraînement et ne parvient pas à s'adapter de manière fiable à des données supplémentaires.
Les données originales d'un modèle d'apprentissage automatique sont généralement divisées en trois ou quatre ensembles. Les trois ensembles couramment utilisés sont l'ensemble d'apprentissage, l'ensemble de développement et l'ensemble de test :
- L'ensemble d'apprentissage est la partie des données utilisée pour entraîner le modèle. Le modèle doit observer et apprendre à partir de l'ensemble d'apprentissage, en optimisant tous ses paramètres.
- L'ensemble de développement est un ensemble de données d'exemples utilisé pour modifier les paramètres du processus d'apprentissage. Il est également appelé ensemble de validation croisée ou ensemble de validation du modèle. Cet ensemble de données a pour objectif de classer la précision du modèle et peut aider à la sélection du modèle.
- L'ensemble de test est la partie des données qui est testée dans le modèle final et comparée aux ensembles de données précédents. L'ensemble de test sert à évaluer le mode et l'algorithme finaux.
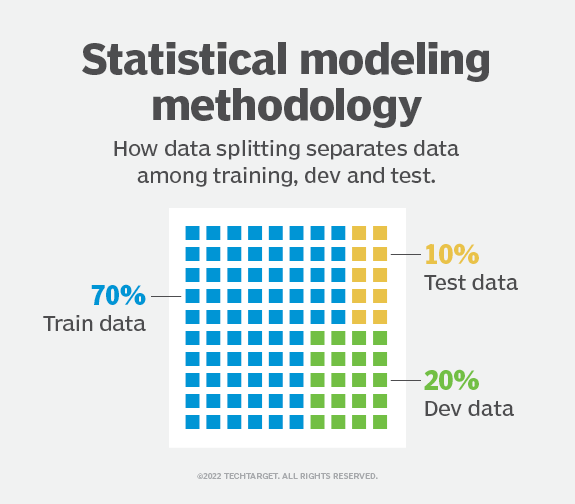
Les données doivent être divisées de manière à ce que les ensembles de données puissent contenir une grande quantité de données d'apprentissage. Par exemple, les données peuvent être divisées selon un ratio de 80-20 ou 70-30 entre les données d'apprentissage et les données de test. Le ratio exact dépend des données, mais un ratio de 70-20-10 pour les divisions d'apprentissage, de développement et de test est optimal pour les petits ensembles de données.
Pour en savoir plus sur la création de modèles d'apprentissage automatique et les sept étapes du processus, cliquez ici.






