Qu'est-ce que l'étiquetage des données ?
L'étiquetage des données est le processus qui consiste à identifier et à marquer des échantillons de données couramment utilisés dans le cadre de la formation des modèles d'apprentissage automatique (ML). Ce processus peut être manuel, mais il est généralement effectué ou assisté par un logiciel. L'étiquetage des données aide les modèles d'apprentissage automatique à faire des prédictions précises. Il est également utile dans des processus tels que la vision par ordinateur, le traitement du langage naturel (NLP) et la reconnaissance vocale.
Le processus commence par la collecte de données brutes, telles que des images ou des données textuelles, puis une ou plusieurs étiquettes d'identification sont appliquées à chaque segment de données afin de préciser le contexte des données dans le modèle d'apprentissage automatique. Les étiquettes utilisées pour identifier les caractéristiques des données doivent être informatives, spécifiques et indépendantes afin de produire un modèle de qualité.
À quoi sert l'étiquetage des données ?
L'étiquetage des données est une partie importante du prétraitement des données pour l'apprentissage automatique, en particulier pour l'apprentissage supervisé. Dans l'apprentissage supervisé, un programme d'apprentissage automatique est entraîné sur un ensemble de données étiquetées. Les modèles sont entraînés jusqu'à ce qu'ils puissent détecter la relation sous-jacente entre les données d'entrée et les étiquettes de sortie. Dans ce contexte, l'étiquetage des données aide le modèle à traiter et à comprendre les données d'entrée.
Par exemple, un modèle entraîné à identifier des images d'animaux reçoit plusieurs images de différents types d'animaux à partir desquelles il apprend les caractéristiques communes à chacun. Cela permet au modèle d'identifier correctement les animaux dans des données non étiquetées.
Le marquage des données est également utilisé lors de la conception d'algorithmes d'apprentissage automatique pour les véhicules autonomes, tels que les voitures autonomes. Ceux-ci doivent être capables de faire la différence entre les objets qui pourraient se trouver sur leur chemin. Ces informations permettent à ces véhicules de traiter le monde extérieur et de rouler en toute sécurité. L'étiquetage des données permet à l'intelligence artificielle (IA) de la voiture de faire la différence entre une personne et une autre voiture ou entre la rue et le ciel. Les caractéristiques clés de ces objets ou points de données sont étiquetées et les similitudes entre eux sont identifiées.
Tout comme l'apprentissage automatique supervisé, la vision par ordinateur utilise également l'étiquetage des données pour aider à identifier les données brutes. La vision par ordinateur traite de la manière dont les ordinateurs interprètent les images et les vidéos numériques.
Le NLP, qui permet à un programme de comprendre le langage humain, utilise l'étiquetage des données pour extraire et organiser les données à partir de textes. Des éléments textuels spécifiques sont identifiés et étiquetés dans un modèle NLP afin d'être compris.
Comment fonctionne l'étiquetage des données ?
Les systèmes d'apprentissage automatique et d'apprentissage profond nécessitent d'énormes quantités de données pour établir une base de modèles d'apprentissage fiables. Les données qu'ils utilisent pour alimenter l'apprentissage actif doivent être étiquetées ou annotées en fonction de caractéristiques qui aident le modèle à organiser les données en modèles produisant la réponse souhaitée.
Le processus d'étiquetage des données commence par la collecte des données, puis passe au marquage des données et à l'assurance qualité (QA). Il se termine lorsque le modèle commence à s'entraîner. Ce processus comprend quatre étapes clés :
- Collecte des données. Au cours de cette étape, les données brutes utiles à l'entraînement d'un modèle sont collectées, nettoyées et traitées.
- Marquage des données. Que ce soit manuellement ou à l'aide d'un logiciel, les données sont ensuite marquées d'une ou plusieurs balises, qui fournissent au modèle d'apprentissage automatique le contexte des données.
- QA. La qualité du modèle d'apprentissage automatique dépend de la qualité et de la précision des balises. Les données correctement étiquetées deviennent ce que l'on appelle la vérité terrain.
- Entraînement. Le modèle d'apprentissage automatique est ensuite entraîné à l'aide des données étiquetées.
Un ensemble de données correctement étiqueté fournit une vérité terrain par rapport à laquelle le modèle ML vérifie l'exactitude de ses prédictions et continue d'affiner son algorithme. Un algorithme de haute qualité est très précis, ce qui fait référence à la proximité de certaines étiquettes dans l'ensemble de données par rapport à la vérité terrain.
Les erreurs dans l'étiquetage des données nuisent à la qualité de l'ensemble de données d'apprentissage et aux performances des modèles prédictifs qui l'utilisent. Pour atténuer ce problème et garantir des performances élevées, de nombreuses organisations adoptent une approche dite « human-in-the-loop » (intervention humaine dans la boucle). Dans ce cadre, des personnes participent à l'apprentissage et au test des données.
Étiquetage des données, classification des données et annotation des données
L'étiquetage, la classification et l'annotation des données sont trois méthodes utilisées pour préparer les données qui alimentent les modèles d'apprentissage automatique. Elles sont également pratiques pour traiter de grands volumes de données brutes qui doivent être organisées. Cependant, ces trois méthodes sont mises en œuvre de différentes manières et à des fins différentes.
Étiquetage des données
Avec cette approche, un expert en données prédéfinit des étiquettes et les applique à chaque point de données d'un ensemble de données. Le processus fournit au modèle le contexte nécessaire dans ses données d'apprentissage pour tirer des enseignements de ces données et produire des résultats, tels que des informations ou des prévisions.
Classification des données
La classification des données consiste à catégoriser les données, soit de manière catégorique, soit à l'aide d'une approche binaire. Une classification réussie des données dépend de bonnes pratiques d'étiquetage des données. Par exemple, une tâche de classification binaire peut trier les e-mails, en déterminant s'ils sont des spams ou non, en examinant les données étiquetées. La classification des données est principalement utilisée dans l'apprentissage supervisé pour enseigner au modèle ML à faire des prédictions.
Annotation des données
L'annotation des données fournit des informations spécifiques sur les entrées de données, ce qui permet aux modèles d'apprentissage automatique de mieux comprendre ces entrées. Par exemple, l'annotation des données peut être appliquée dans les systèmes de véhicules autonomes où un modèle doit examiner de nombreux objets différents dans son environnement. L'annotation de différents objets avec plus de contexte et de détails améliore la compréhension du système de son environnement.
Quels sont les types courants d'étiquetage des données ?
Les différents types d'étiquetage des données sont définis par le support sur lequel les données sont étiquetées :
- Étiquetage d'images et de vidéos. Un exemple de ce type d'étiquetage de données est un modèle de vision par ordinateur, dans lequel des balises sont ajoutées à des images individuelles ou à des images vidéo. Ce type de classification d'images est utilisé dans les diagnostics médicaux, la reconnaissance d'objets et les voitures automatisées.
- Étiquetage de texte. Le NLP utilise ce type, en ajoutant des balises aux mots pour l'interprétation des langues humaines. Le NLP est utilisé dans les chatbots et l'analyse des sentiments.
- Étiquetage audio. Ce type d'étiquetage de données est utilisé dans la reconnaissance vocale, où les segments audio sont décomposés et étiquetés. L'étiquetage audio est utile pour les assistants vocaux et les transcriptions de la parole en texte.
Avantages de l'étiquetage des données
Les avantages liés à l'étiquetage des données sont les suivants :
- Des prédictions précises. Si les scientifiques des données saisissent des données correctement étiquetées, un modèle d'apprentissage automatique entraîné peut utiliser ces données comme référence pour faire des prédictions précises lorsqu'il est confronté à de nouvelles données.
- Utilisation des données. Les développeurs réduisent le nombre de variables d'entrée afin d'optimiser les modèles de manière à obtenir de meilleures analyses et prédictions. Il est important que les données d'entrée soient étiquetées de manière à spécifier les caractéristiques et les variables de données les plus pertinentes ou les plus importantes pour l'apprentissage du modèle. Cela aide le modèle à se concentrer sur les données les plus utiles et les plus pertinentes et le rend plus apte à accomplir les tâches qui lui sont assignées.
- Innovation et rentabilité accrues. Une fois qu'une approche de l'étiquetage des données est mise en place, les employés peuvent consacrer moins de temps aux tâches fastidieuses d'étiquetage des données et se concentrer plutôt sur la recherche de nouvelles utilisations pratiques ou génératrices de revenus pour les données étiquetées.
Les défis liés à l'étiquetage des données
Les entreprises chargées de l'étiquetage de données à grande échelle sont confrontées à plusieurs défis évidents :
- Coûts. L'étiquetage des données peut être coûteux, en particulier lorsqu'il est effectué manuellement. Même avec une approche automatisée, l'achat et la mise en place de l'infrastructure technologique nécessaire entraînent des coûts initiaux.
- Temps et efforts. Le marquage manuel des données prend inévitablement plus de temps qu'une approche automatisée. Cependant, même avec l'automatisation, les employés possédant l'expertise nécessaire doivent consacrer du temps à la mise en place de l'infrastructure, au détriment de leurs tâches habituelles.
- Erreur humaine. Les erreurs sont inévitables. Par exemple, les données peuvent être mal étiquetées en raison d'erreurs de codage ou de saisie manuelle. Cela peut entraîner un traitement inexact des données, une modélisation erronée ou un biais dans l'apprentissage automatique.
Meilleures pratiques pour l'étiquetage des données
Les meilleures pratiques à suivre en matière d'étiquetage des données sont les suivantes :
- Collectez des données variées. Lorsque vous collectez des données à étiqueter, les ensembles de données doivent être aussi variés que possible afin d'éviter tout biais.
- Veiller à ce que les données soient représentatives. Les données collectées doivent être claires et précises si les développeurs de modèles veulent que leurs modèles soient exacts.
- Donnez votre avis. Des commentaires réguliers permettent de garantir la qualité des étiquettes de données.
- Créer un consensus sur les étiquettes. Cela devrait permettre de mesurer le taux d'accord entre les étiqueteurs humains et les étiqueteurs automatiques.
- Étiquettes d'audit. Les audits sont effectués afin de vérifier l'exactitude des étiquettes.
Méthodes d'étiquetage des données
Une entreprise peut utiliser plusieurs méthodes pour structurer et étiqueter ses données. Les options vont du recours à du personnel interne au crowdsourcing et aux services d'étiquetage des données :
- Crowdsourcing. Une plateforme de crowdsourcing tierce permet à une entreprise d'accéder à de nombreux travailleurs à la fois.
- Externalisation. Une entreprise peut embaucher des travailleurs indépendants temporaires pour traiter et étiqueter les données.
- Équipes gérées. Une entreprise peut faire appel à une équipe gérée pour traiter les données. Les équipes gérées sont formées, évaluées et gérées par un organisme tiers.
- Personnel interne. Une entreprise peut utiliser ses employés existants pour traiter les données.
- Étiquetage synthétique. De nouvelles données de projet sont générées à partir d'ensembles de données existants. Ce processus améliore la qualité des données et le gain de temps, mais nécessite davantage de puissance de calcul.
- Étiquetage programmatique. Des scripts sont utilisés pour automatiser le processus d'étiquetage des données.
Il n'existe pas de méthode optimale unique pour l'étiquetage des données. Les entreprises doivent utiliser la méthode ou la combinaison de méthodes qui correspond le mieux à leurs besoins. Certaines questions doivent être prises en compte lors du choix d'une méthode d'étiquetage des données de haute qualité, telles que les suivantes :
- S'agit-il d'une grande entreprise ou d'une petite ou moyenne entreprise ?
- Quelle est la taille de l'ensemble de données qui nécessite un étiquetage ?
- Quel est le niveau de compétence des employés ?
- Y a-t-il des contraintes financières ?
- Quel est l'intérêt d'enrichir le modèle ML avec des données étiquetées ?
Une bonne équipe de étiquetage des données devrait idéalement posséder des connaissances spécialisées dans le domaine d'activité de l'entreprise. Les étiqueteurs humains qui disposent d'un contexte extérieur pour les guider sont plus précis que ceux qui n'en ont pas, et ils ont également des perspectives diverses. Ils doivent également faire preuve de flexibilité et d'agilité, car l'étiquetage des données et l'apprentissage automatique sont des processus itératifs, en constante évolution à mesure que de nouvelles informations sont intégrées.
L'importance de l'étiquetage des données
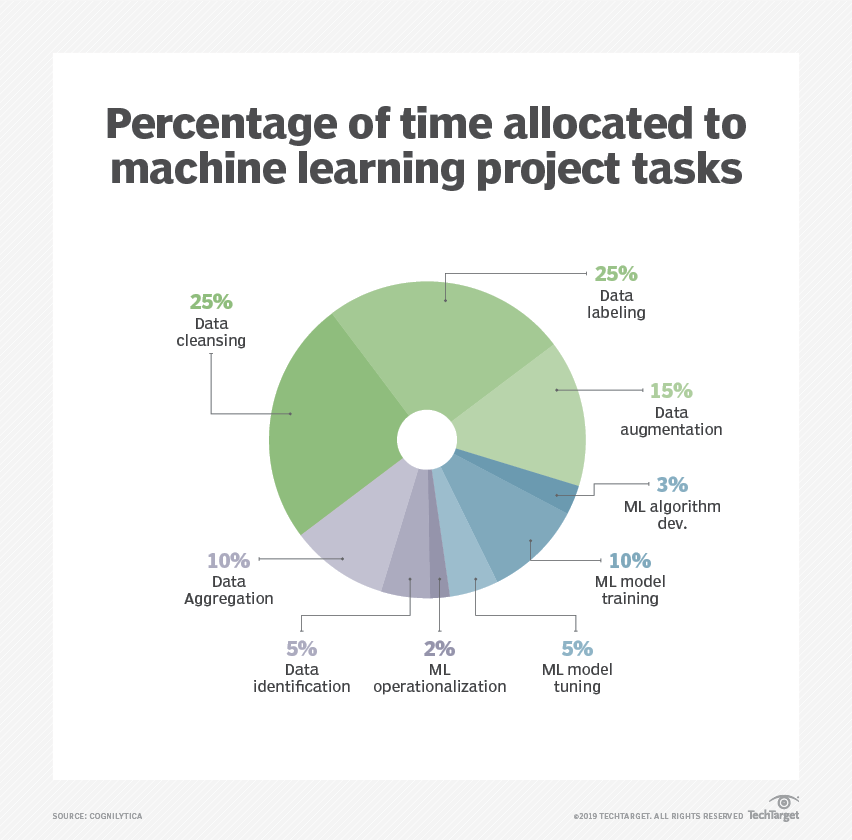
Les dépenses consacrées aux projets d'IA servent généralement à préparer, nettoyer et étiqueter les données. L'étiquetage manuel des données est la méthode la plus longue et la plus coûteuse, mais elle peut s'avérer justifiée pour des applications importantes.
Les détracteurs de l'IA pensent que l'automatisation va mettre en péril les emplois peu qualifiés, comme ceux dans les centres d'appels, les chauffeurs routiers et les chauffeurs Uber. Les machines auront plus de facilité à faire ce genre de tâches répétitives.
Cependant, certains experts estiment que l'étiquetage des données constituera en soi une nouvelle opportunité d'emploi peu qualifié pour les personnes déplacées par l'automatisation. Il y aura un surplus toujours croissant de données et de machines qui devront être formées pour traiter ces données. Des étiqueteurs de données qualifiés seront nécessaires pour étiqueter correctement les données et former les modèles avancés d'IA et d'apprentissage automatique.
Exemples d'entreprises utilisant l'étiquetage des données
Les entreprises qui ont intégré l'étiquetage des données dans leurs modèles commerciaux sont notamment les suivantes :
- Alibaba utilise l'étiquetage des données pour sa plateforme de commerce électronique. Les données relatives aux achats des clients sont étiquetées et annotées afin d'être intégrées à un modèle d'IA qui propose des recommandations de produits à ces clients sur la base de ces données.
- Amazon utilise une approche similaire pour générer des recommandations de produits aux consommateurs grâce à son moteur de recommandation alimenté par l'IA.
- Facebook. Facebook peut prendre des photos du visage de ses utilisateurs et les étiqueter dans le but d'entraîner des algorithmes à proposer des suggestions de balises pour ces photos.
- Microsoft. L'étiquetage des données a joué un rôle essentiel dans le développement des services Microsoft Azure, en particulier Azure Machine Learning, lors de l'utilisation de données d'entraînement pour former le modèle.
- Constructeurs de véhicules autonomes. Tesla a développé des capacités autonomes pour ses véhicules en étiquetant et en annotant les objets dans le monde environnant. Waymo a effectué un entraînement similaire avec ses véhicules autonomes, en s'appuyant également fortement sur l'étiquetage des objets dans le monde physique.
- Développeurs d'assistants vocaux. Google Assistant, Siri d'Apple et Alexa d'Amazon ont tous été développés à l'aide d'un apprentissage automatique qui a étiqueté des données vocales et des échantillons audio.
L'avenir de l'étiquetage des données
À mesure que les technologies avancées, telles que l'IA et le ML, se généralisent dans tous les secteurs pour des utilisations concrètes, les outils de marquage des données basés sur l'IA deviennent de plus en plus courants. La collecte de mégadonnées devenant également plus courante, les algorithmes de ML sont alimentés par de grands volumes de données d'apprentissage afin d'acquérir de nouvelles informations. Les algorithmes devraient également s'améliorer en matière de catégorisation ou de classification. L'objectif est de marquer efficacement les volumes de données afin que les utilisateurs n'aient plus à effectuer ces tâches fastidieuses.
Parmi les autres tendances, on note l'expansion du crowdsourcing, qui consiste à mettre en commun les travailleurs afin qu'ils étiquettent collectivement les données. Les grands ensembles de données tirent profit du fait que des personnes issues de divers horizons et possédant des domaines d'expertise variés ajoutent des informations détaillées aux points de données.
Enfin, les préoccupations relatives à la confidentialité des données se sont accrues à mesure que les modèles d'IA et d'apprentissage automatique sont alimentés par de grands ensembles de données, qui comprennent souvent des données personnelles. Les entreprises doivent donc faire preuve de prudence lorsqu'elles étiquettent les données afin de ne pas enfreindre les lois locales, régionales et fédérales en matière de protection des données et de garantir la confidentialité des personnes concernées.
L'étiquetage des données est un sous-ensemble du prétraitement des données. Découvrez divers outils de science des données, notamment ceux utilisés pour le prétraitement des données.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que la détection d'anomalies ? Présentation et explication
Par: George Lawton
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
L'apprentissage par renforcement à partir du feedback humain (RLHF) ?
Par: Andy Patrizio
-
![]()
Qu'est-ce que l'apprentissage par renforcement à partir du feedback humain (RLHF) ?



