Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
L'apprentissage profond est un type d'apprentissage automatique (ML) et d'intelligence artificielle (IA) qui forme les ordinateurs à apprendre à partir d'ensembles de données volumineux d'une manière qui simule les processus cognitifs humains.
Les modèles d'apprentissage profond peuvent être entraînés à effectuer des tâches de classification et à reconnaître des motifs dans des photos, des textes, des fichiers audio et d'autres types de données. L'apprentissage profond est également utilisé pour automatiser des tâches qui nécessitent normalement l'intelligence humaine, telles que la description d'images ou la transcription de fichiers audio.
Alors que le cerveau humain comporte des millions de neurones interconnectés qui travaillent ensemble pour apprendre des informations, l'apprentissage profond utilise des réseaux neuronaux constitués de plusieurs couches de nœuds logiciels qui fonctionnent ensemble. Les modèles d'apprentissage profond sont entraînés à l'aide d'un vaste ensemble de données étiquetées et d'architectures de réseaux neuronaux.
L'apprentissage profond permet à un ordinateur d'apprendre par l'exemple. Pour comprendre l'apprentissage profond, imaginez un enfant en bas âge dont le premier mot est « chien ». L'enfant apprend ce qu'est un chien (et ce qu'il n'est pas) en montrant des objets du doigt et en prononçant le mot « chien ». Le parent répond : « Oui, c'est un chien » ou « Non, ce n'est pas un chien ». À mesure que l'enfant continue à pointer des objets, il prend conscience des caractéristiques communes à tous les chiens. Sans le savoir, l'enfant clarifie une abstraction complexe : le concept de chien. Il y parvient en construisant une hiérarchie dans laquelle chaque niveau d'abstraction est créé à partir des connaissances acquises au niveau précédent de la hiérarchie.
Pourquoi l'apprentissage profond est-il important ?
Le deep learning trouve diverses applications dans le domaine des affaires, notamment pour l'analyse de données et la génération de prévisions. Il constitue également un élément important de la science des données, notamment des statistiques et de la modélisation prédictive. Il est donc extrêmement utile aux scientifiques des données chargés de collecter, d'analyser et d'interpréter de grandes quantités de données, car il leur permet d'accélérer et de faciliter leur travail.
L'apprentissage profond nécessite à la fois une grande quantité de données étiquetées et une puissance de calcul importante. Si une organisation peut répondre à ces deux besoins, l'apprentissage profond peut être utilisé dans des domaines tels que les assistants numériques, la détection des fraudes et la reconnaissance faciale. L'apprentissage profond offre également une grande précision de reconnaissance, ce qui est essentiel pour d'autres applications potentielles où la sécurité est un facteur majeur, comme les voitures autonomes ou les appareils médicaux.
Comment fonctionne l'apprentissage profond
Les programmes informatiques qui utilisent l'apprentissage profond suivent un processus similaire à celui d'un enfant qui apprend à identifier un chien, par exemple. Les programmes d'apprentissage profond comportent plusieurs couches de nœuds interconnectés, chaque couche s'appuyant sur la précédente pour affiner et optimiser les prédictions et les classifications. L'apprentissage profond effectue des transformations non linéaires sur ses entrées et utilise ce qu'il apprend pour créer un modèle statistique en sortie. Les itérations se poursuivent jusqu'à ce que la sortie atteigne un niveau de précision acceptable. C'est le nombre de couches de traitement que les données doivent traverser qui a inspiré le terme « profond ».
La rétropropagation est un autre algorithme crucial du deep learning qui entraîne les réseaux neuronaux en calculant les gradients de la fonction de perte. Elle ajuste les poids du réseau, ou paramètres qui influencent la sortie et les performances du réseau, afin de minimiser les erreurs et d'améliorer la précision.
Dans le ML traditionnel, le processus d'apprentissage est supervisé, et le programmeur doit être extrêmement précis lorsqu'il indique à l'ordinateur les types d'éléments qu'il doit rechercher pour déterminer si une image contient ou non un chien. Il s'agit d'un processus laborieux appelé extraction de caractéristiques, et le taux de réussite de l'ordinateur dépend entièrement de la capacité du programmeur à définir avec précision un ensemble de caractéristiques pour un chien. L'avantage du deep learning est que le programme construit lui-même l'ensemble de caractéristiques grâce à un apprentissage non supervisé.
Au départ, le programme informatique peut être alimenté par des données d'apprentissage, c'est-à-dire un ensemble d'images pour lesquelles un humain a attribué à chacune d'elles une balise « chien » ou « pas chien ». Le programme utilise les informations qu'il reçoit des données d'apprentissage pour créer un ensemble de caractéristiques pour les chiens et construire un modèle prédictif. Dans ce cas, le modèle initialement créé par l'ordinateur peut prédire que tout ce qui a quatre pattes et une queue dans une image doit être étiqueté « chien ». Bien sûr, le programme n'a pas conscience des étiquettes « quatre pattes » ou « queue ». Il recherche simplement des motifs de pixels dans les données numériques. À chaque itération, le modèle prédictif devient plus complexe et plus précis.
Contrairement à un enfant en bas âge, qui met des semaines, voire des mois, à comprendre le concept de chien, un programme informatique utilisant des algorithmes d'apprentissage profond peut être alimenté par un ensemble de données d'entraînement et trier des millions d'images en quelques minutes, identifiant avec précision celles qui contiennent des chiens.
Pour atteindre un niveau de précision acceptable, les programmes d'apprentissage profond nécessitent l'accès à d'énormes quantités de données d'entraînement et à une puissance de traitement considérable, deux éléments qui n'étaient pas facilement accessibles aux programmeurs avant l'ère du big data et du cloud computing. Comme la programmation d'apprentissage profond peut créer des modèles statistiques complexes directement à partir de ses propres résultats itératifs, elle permet de créer des modèles prédictifs précis à partir de grandes quantités de données non étiquetées et non structurées.
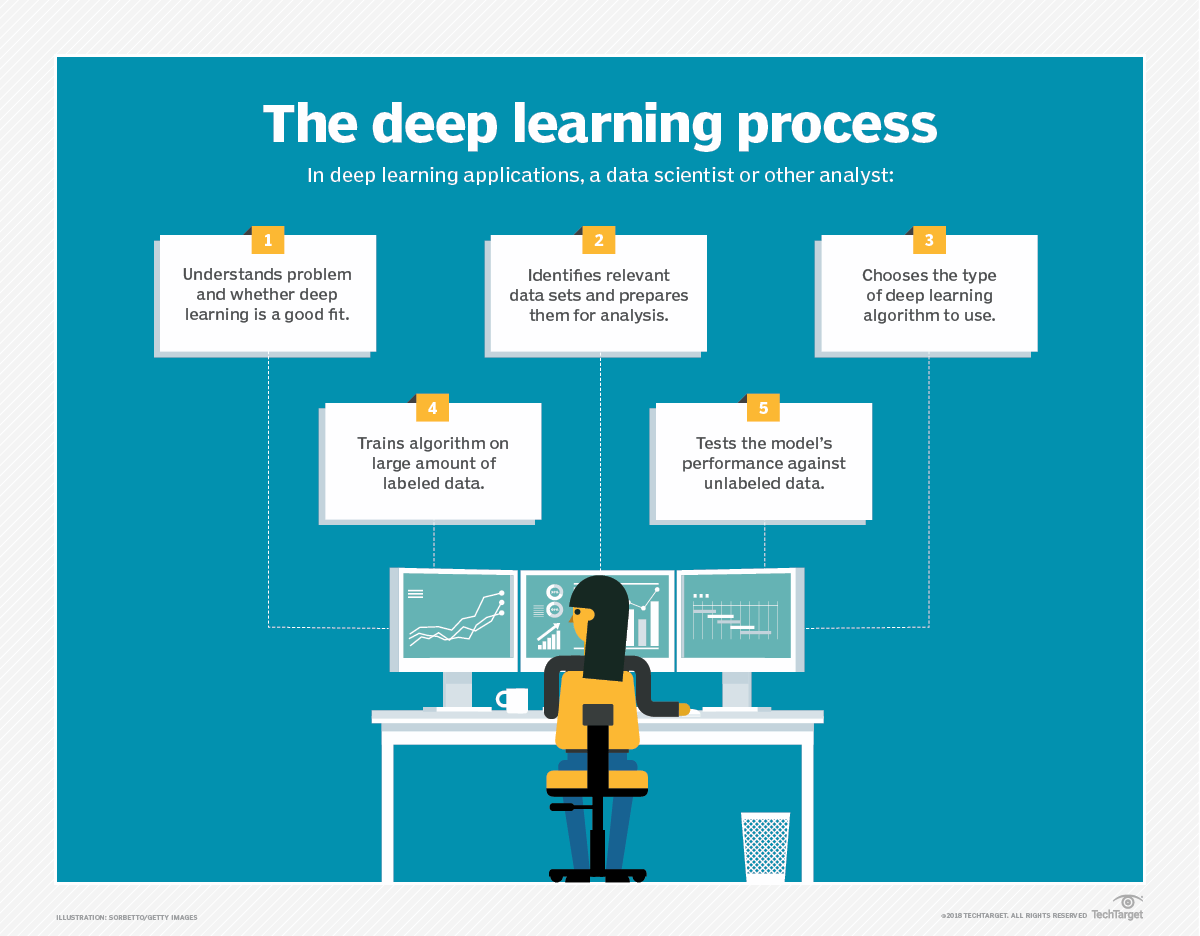
Méthodes d'apprentissage profond
Diverses méthodes peuvent être utilisées pour créer des modèles d'apprentissage profond performants. Ces techniques comprennent la décroissance du taux d'apprentissage, l'apprentissage par transfert, l'apprentissage à partir de zéro et le dropout.
Diminution du taux d'apprentissage
Le taux d'apprentissage est un hyperparamètre, c'est-à-dire un facteur qui définit le système ou fixe les conditions de son fonctionnement avant le processus d'apprentissage, et qui contrôle l'ampleur des changements subis par le modèle en réponse à l'erreur estimée chaque fois que les poids du modèle sont modifiés. Des taux d'apprentissage trop élevés peuvent entraîner des processus d'entraînement instables ou l'apprentissage d'un ensemble de poids sous-optimal. Des taux d'apprentissage trop faibles peuvent entraîner un processus d'entraînement long, susceptible de se bloquer.
La méthode de décroissance du taux d'apprentissage, également appelée « recuit du taux d'apprentissage » ou « taux d'apprentissage adaptatif », consiste à adapter le taux d'apprentissage afin d'améliorer les performances et de réduire le temps d'entraînement. Les adaptations les plus simples et les plus courantes du taux d'apprentissage pendant l'entraînement comprennent des techniques visant à réduire le taux d'apprentissage au fil du temps.
Les techniques courantes dans la méthode de décroissance du taux d'apprentissage comprennent les suivantes :
- Décroissance par paliers. Réduit le taux d'apprentissage d'un facteur à intervalles spécifiques.
- Décroissance exponentielle. Diminue continuellement le taux d'apprentissage à un rythme exponentiel.
- Décroissance 1/t. Réduit le taux d'apprentissage de manière inversement proportionnelle au nombre d'itérations.
Apprentissage par transfert
Ce processus consiste à perfectionner un modèle précédemment entraîné sur un problème nouveau mais connexe. Il nécessite une interface avec les composants internes d'un réseau préexistant. Tout d'abord, les utilisateurs alimentent le réseau existant avec de nouvelles données contenant des classifications précédemment inconnues. Une fois les ajustements apportés au réseau, de nouvelles tâches peuvent être effectuées avec des capacités de catégorisation plus spécifiques.
Cette méthode présente l'avantage de nécessiter beaucoup moins de données que les autres, ce qui réduit le temps de calcul à quelques minutes ou quelques heures.
Formation à partir de zéro
Cette méthode nécessite qu'un développeur collecte un ensemble de données volumineux et étiqueté, puis configure une architecture réseau capable d'apprendre les caractéristiques et le modèle. Cette technique est particulièrement utile pour les nouvelles applications, ainsi que pour les applications comportant de nombreuses catégories de sortie. Cependant, il s'agit d'une approche moins courante, car elle nécessite des quantités excessives de données et de ressources informatiques, ce qui fait que la formation peut prendre des jours, voire des semaines.
Dropout
Cette méthode tente de résoudre le problème du surajustement dans les réseaux comportant un grand nombre de paramètres en supprimant de manière aléatoire des unités et leurs connexions du réseau neuronal pendant l'apprentissage.
Il a été prouvé que la méthode de dropout peut améliorer les performances des réseaux neuronaux dans les tâches d'apprentissage supervisé dans des domaines tels que la reconnaissance vocale, la classification de documents et la biologie computationnelle.
Réseaux neuronaux d'apprentissage profond
Un type d'algorithme ML avancé, connu sous le nom de réseau neuronal artificiel, est à la base de la plupart des modèles d'apprentissage profond. Par conséquent, l'apprentissage profond peut parfois être appelé apprentissage neuronal profond ou réseau neuronal profond.
Les DDN sont composés de couches d'entrée, cachées et de sortie. Les nœuds d'entrée servent à placer les données d'entrée. Le nombre de couches de sortie et de nœuds requis varie en fonction de la sortie. Par exemple, les sorties oui ou non ne nécessitent que deux nœuds, tandis que les sorties comportant davantage de données requièrent davantage de nœuds. Les couches cachées sont des couches multiples qui traitent et transmettent les données à d'autres couches du réseau neuronal.
Les réseaux neuronaux se présentent sous plusieurs formes différentes, notamment les suivantes :
- Réseaux neuronaux récurrents. Les RNN sont souvent utilisés dans la reconnaissance vocale et le traitement du langage naturel (NLP).
- Réseaux neuronaux convolutifs. Les CNN sont souvent utilisés pour analyser des données visuelles.
- Réseaux antagonistes génératifs. Les GAN sont souvent utilisés pour la détection d'anomalies, l'augmentation des données et la traduction d'image à image.
- Perceptrons multicouches. Les MLP sont souvent utilisés pour la reconnaissance d'images, le traitement du langage naturel et les prévisions de séries chronologiques.
- Réseaux neuronaux feedforward. Dans un réseau neuronal feedforward, les informations circulent dans un seul sens, des couches d'entrée vers les couches de sortie.
Chaque type de réseau neuronal présente des avantages pour des cas d'utilisation spécifiques. Cependant, ils fonctionnent tous de manière assez similaire : ils sont alimentés en données et laissent le modèle déterminer lui-même s'il a correctement interprété ou pris la bonne décision concernant un élément de données donné.
Les réseaux neuronaux impliquent un processus d'essais et d'erreurs, ils ont donc besoin d'énormes quantités de données pour s'entraîner. Ce n'est pas un hasard si les réseaux neuronaux ne sont devenus populaires qu'après que la plupart des entreprises aient adopté l'analyse des mégadonnées et accumulé de grandes quantités de données. Étant donné que les premières itérations du modèle impliquent des suppositions quelque peu éclairées sur le contenu d'une image ou de parties du discours, les données utilisées pendant la phase d'entraînement doivent être étiquetées afin que le modèle puisse vérifier si ses suppositions étaient exactes. Cela signifie que les données non structurées sont moins utiles.
Les données non structurées ne peuvent être analysées par un modèle d'apprentissage profond qu'une fois qu'il a été entraîné et atteint un niveau de précision acceptable, mais les modèles d'apprentissage profond ne peuvent pas s'entraîner sur des données non structurées.
Avantages de l'apprentissage profond
Les avantages de l'apprentissage profond sont les suivants :
- Apprentissage automatique des caractéristiques. Les systèmes d'apprentissage profond peuvent extraire automatiquement les caractéristiques, ce qui signifie qu'ils ne nécessitent aucune supervision pour ajouter de nouvelles caractéristiques.
- Découverte de modèles. Les systèmes d'apprentissage profond peuvent analyser de grandes quantités de données et découvrir des modèles complexes dans des images, des textes et des fichiers audio, et peuvent en tirer des conclusions pour lesquelles le système n'a peut-être pas été formé.
- Traiter des ensembles de données volatiles. Les systèmes d'apprentissage profond peuvent classer et trier des ensembles de données présentant de grandes variations, comme dans les systèmes de transaction et de fraude.
- Traitez plusieurs types de données. Les systèmes d'apprentissage profond peuvent traiter à la fois des données structurées et non structurées.
- Précision. Des couches de nœuds supplémentaires contribuent à optimiser la précision des modèles d'apprentissage profond.
- Peut faire plus que les autres méthodes d'apprentissage automatique. Comparé aux processus d'apprentissage automatique classiques, l'apprentissage profond nécessite moins d'intervention humaine et peut analyser des données que les autres processus d'apprentissage automatique ne peuvent pas traiter aussi bien.
- Évolutivité grâce aux données. Les modèles d'apprentissage profond sont de plus en plus performants à mesure que le volume de données augmente. Contrairement aux algorithmes d'apprentissage automatique traditionnels, qui peuvent atteindre un plateau de performance après un certain seuil, les modèles d'apprentissage profond continuent de s'améliorer avec davantage de données, ce qui les rend particulièrement adaptés aux applications impliquant de grands ensembles de données.
- Rentabilité. Bien que la formation des modèles d'apprentissage profond puisse être coûteuse, elle aide les entreprises à réduire leurs dépenses en diminuant considérablement les erreurs et les défauts dans tous les secteurs. Le coût des prévisions inexactes dépasse souvent les frais de formation, et la capacité de l'apprentissage profond à minimiser les erreurs surpasse celle des modèles d'apprentissage automatique traditionnels.
Principales utilisations du deep learning
Comme les modèles d'apprentissage profond traitent les informations de manière similaire au cerveau humain, ils peuvent être appliqués à de nombreuses tâches effectuées par les humains. L'apprentissage profond est actuellement utilisé dans la plupart des outils courants de reconnaissance d'images, les logiciels de traitement du langage naturel (NLP) et de reconnaissance vocale.
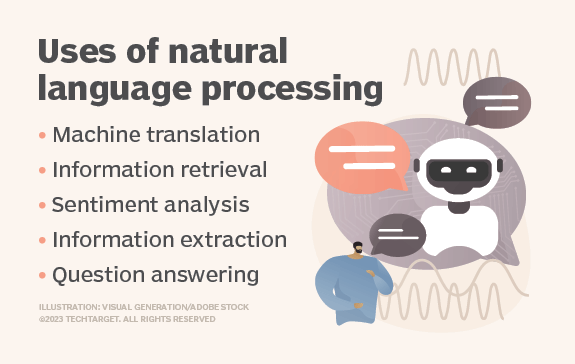
Les cas d'utilisation actuels du deep learning comprennent tous les types d'applications d'analyse de mégadonnées, en particulier celles axées sur la traduction linguistique, l'imagerie et le diagnostic médicaux, les signaux boursiers, la sécurité des réseaux et la reconnaissance d'images.
Les cas d'utilisation du deep learning comprennent les suivants :
- Expérience client. Les modèles d'apprentissage profond sont déjà utilisés pour les chatbots. Et, à mesure que la technologie continue de mûrir, l'apprentissage profond devrait être mis en œuvre dans diverses entreprises afin d'améliorer l'expérience client et d'accroître la satisfaction des clients.
- Génération de texte. On enseigne aux machines la grammaire et le style d'un texte, puis elles utilisent ce modèle pour créer automatiquement un texte entièrement nouveau qui respecte l'orthographe, la grammaire et le style du texte original.
- Aérospatiale et militaire. Le deep learning est utilisé pour détecter des objets à partir de satellites qui identifient les zones d'intérêt, ainsi que les zones sûres ou dangereuses pour les troupes.
- Automatisation industrielle. Le deep learning améliore la sécurité des travailleurs dans certains environnements, notamment les usines et les entrepôts, en fournissant des services d'automatisation industrielle qui détectent automatiquement lorsqu'un travailleur ou un objet s'approche trop près d'une machine.
- Ajouter de la couleur. Il est possible d'ajouter de la couleur à des photos et vidéos en noir et blanc à l'aide de modèles d'apprentissage profond. Auparavant, ce processus manuel était extrêmement long.
- Vision par ordinateur. L'apprentissage profond a considérablement amélioré la vision artificielle, offrant aux ordinateurs une précision extrême pour la détection d'objets et la classification, la restauration et la segmentation d'images.
- Moteurs de recommandation. Les applications peuvent utiliser l'apprentissage profond pour suivre le comportement des utilisateurs et générer des suggestions personnalisées afin d'aider les consommateurs à découvrir de nouveaux produits et services. Par exemple, Netflix, Peacock et d'autres organisations médiatiques et de divertissement utilisent l'apprentissage profond pour fournir des recommandations vidéo personnalisées.
- Sécurité en ligne. Les algorithmes d'apprentissage profond peuvent protéger contre la fraude en identifiant les problèmes de sécurité. Par exemple, ces algorithmes peuvent détecter les tentatives de connexion suspectes, envoyer des notifications et alerter les utilisateurs si le mot de passe qu'ils ont choisi n'est pas suffisamment sûr.
Limites et défis
Les systèmes d'apprentissage profond présentent également les inconvénients suivants :
- Apprendre uniquement par l'observation. Les systèmes d'apprentissage profond ne connaissent que les données sur lesquelles ils ont été entraînés. Si un utilisateur dispose d'une petite quantité de données ou si celles-ci proviennent d'une source spécifique qui n'est pas nécessairement représentative de l'ensemble du domaine fonctionnel, les modèles n'apprennent pas de manière généralisable.
- Risque de biais. Si un modèle est entraîné à partir de données contenant des biais, il reproduira ces biais dans ses prédictions. Les biais dans l'apprentissage automatique constituent un problème épineux pour les programmeurs spécialisés dans l'apprentissage profond, car les modèles apprennent à différencier les éléments à partir de variations subtiles dans les données. Souvent, les facteurs qu'ils jugent importants ne sont pas clairement expliqués au programmeur. Cela signifie, par exemple, qu'un modèle de reconnaissance faciale peut déterminer les caractéristiques d'une personne en fonction de critères tels que la race ou le sexe sans que le programmeur en soit conscient.
- Taux d'apprentissage élevé. Si le taux est trop élevé, le modèle converge trop rapidement, produisant une solution loin d'être optimale. Si le taux est trop faible, le processus peut se bloquer, et il est alors encore plus difficile d'aboutir à une solution.
- Configuration matérielle requise. Des processeurs graphiques (GPU) multicœurs haute performance et d'autres processeurs similaires sont nécessaires pour garantir une efficacité accrue et une réduction du temps nécessaire. Cependant, ces processeurs sont coûteux et consomment beaucoup d'énergie. La configuration matérielle requise comprend également de la mémoire vive (RAM) et un disque dur ou un disque SSD basé sur la mémoire vive.
- Nécessite de grandes quantités de données. Les modèles les plus puissants et les plus précis nécessitent davantage de paramètres, ce qui implique davantage de données ou de grandes quantités de données continues.
- Absence de multitâche. Une fois entraînés, les modèles d'apprentissage profond deviennent rigides et ne peuvent pas gérer plusieurs tâches à la fois. Ils peuvent fournir des résultats efficaces et précis, mais uniquement pour un problème spécifique. Même pour résoudre un problème similaire, il faudrait ré-entraîner le système.
- Manque de raisonnement. Pour toute application qui nécessite un raisonnement, comme la programmation ou l'application de la méthode scientifique, la planification à long terme et la manipulation de données de type algorithmique dépassent complètement les capacités des techniques actuelles d'apprentissage profond, même avec de grandes quantités de données.
Apprentissage profond sur site ou dans le cloud
Lorsqu'elles envisagent de mettre en place une infrastructure d'apprentissage profond, les entreprises hésitent souvent entre les services cloud et les solutions sur site. Les deux options présentent des avantages et des inconvénients.
Le deep learning basé sur le cloud offre une évolutivité et un accès à du matériel avancé, tel que des GPU et des unités de traitement tensoriel, ce qui le rend adapté aux projets aux exigences variables et au prototypage rapide. Il élimine également le besoin d'investissements initiaux importants dans le matériel.
Les options d'apprentissage profond sur site offrent un meilleur contrôle sur la sécurité des données et peuvent s'avérer plus rentables à long terme pour des besoins constants et de grande capacité. Ces configurations permettent également des personnalisations.
De nombreuses organisations optent également pour une troisième option, dite hybride, dans laquelle les modèles sont testés sur site mais déployés dans le cloud afin de tirer parti des avantages des deux environnements. Cependant, le choix entre l'apprentissage profond sur site et dans le cloud dépend de facteurs tels que le budget, l'évolutivité, la sensibilité des données et les exigences spécifiques du projet.
Apprentissage profond vs apprentissage automatique
Le deep learning et le ML(Machine learning) sont tous deux des sous-ensembles de l'IA, mais ils ont des approches différentes. Les principales différences entre les deux sont les suivantes :
- L'apprentissage profond est un sous-ensemble du ML qui se distingue par sa manière de résoudre les problèmes.
- Le ML consiste à entraîner des algorithmes à apprendre à partir de données et à faire des prédictions ou prendre des décisions sans être explicitement programmés pour des tâches spécifiques.
- Le ML nécessite un expert du domaine pour identifier les caractéristiques les plus appliquées.
- Le deep learning comprend les caractéristiques de manière incrémentielle, éliminant ainsi le besoin d'une expertise dans le domaine. Cependant, les algorithmes de deep learning prennent plus de temps à entraîner que les algorithmes de ML, qui ne nécessitent que quelques secondes à quelques heures. Mais l'inverse est vrai pendant les tests. Les algorithmes de deep learning prennent moins de temps à exécuter les tests que les algorithmes de ML, dont le temps de test augmente avec la taille des données.
- Le ML ne nécessite pas les mêmes machines haut de gamme coûteuses et les mêmes GPU hautement performants que le deep learning.
- Le deep learning est particulièrement recommandé dans les situations où il y a une grande quantité de données, un manque de compréhension du domaine pour l'introspection des caractéristiques ou des problèmes complexes, tels que la reconnaissance vocale et le traitement du langage naturel.
- De nombreux scientifiques des données préfèrent le ML traditionnel au deep learning en raison de sa meilleure interprétabilité, ou de sa capacité à donner un sens aux résultats générés. Les algorithmes ML sont également privilégiés lorsque la quantité de données est faible.
Applications potentielles du deep learning à l'avenir
L'apprentissage profond est utilisé à la fois dans les technologies émergentes et courantes. Voici quelques domaines clés dans lesquels l'apprentissage profond devrait faire des progrès :
- Innovations dans le domaine de la santé. L'apprentissage profond est utilisé dans le domaine médical pour détecter le délire chez les patients gravement malades. Les chercheurs en cancérologie utilisent l'apprentissage profond pour détecter automatiquement la présence de cellules cancéreuses. L'apprentissage profond est également appelé à transformer les soins de santé en améliorant la précision des diagnostics et en proposant des traitements personnalisés. À titre d'exemple, les applications futures pourraient inclure l'analyse prédictive des épidémies, la surveillance de la santé en temps réel via des appareils portables et des assistants de santé virtuels basés sur l'IA offrant des conseils médicaux personnalisés.
- Voitures autonomes. Les voitures autonomes utilisent l'apprentissage profond pour détecter automatiquement des objets, tels que les panneaux de signalisation ou les piétons.
- Réseaux sociaux. Les plateformes de réseaux sociaux peuvent utiliser l'apprentissage profond pour modérer les contenus, en passant au crible les images et les fichiers audio.
- Apprentissage par transfert et apprentissage en quelques essais. L'apprentissage par transfert, qui consiste à appliquer un modèle entraîné sur une tâche à une tâche connexe, est de plus en plus populaire. Le domaine émergent de l'apprentissage en quelques essais, qui se concentre sur l'entraînement de modèles avec un minimum de données étiquetées, pourrait réduire le besoin d'un prétraitement approfondi des données et de grands ensembles de données d'entraînement.
- Villes intelligentes. L'apprentissage profond peut stimuler le développement des villes intelligentes en optimisant la gestion du trafic, la consommation d'énergie et la sécurité publique. Les systèmes d'IA peuvent analyser les schémas de circulation afin de réduire les embouteillages, gérer plus efficacement les ressources énergétiques et renforcer la surveillance pour améliorer la sécurité.
- IA en périphérie. La puissance de calcul des appareils ayant augmenté, on observe une tendance croissante à déployer l'IA en périphérie (Edge). Par exemple, les modèles d'apprentissage profond sont de plus en plus utilisés sur les appareils mobiles, les appareils connectés à l'Internet des objets et les serveurs sur site. Cela réduit la latence et renforce la confidentialité en permettant le traitement local des données.
- Rêves profonds. L'industrie des rêves profonds utilise des réseaux neuronaux profonds pour générer de nouvelles images à partir d'un ensemble d'images d'entrée. Les résultats sont souvent surréalistes ou oniriques, ce qui les rend idéaux pour créer de nouvelles œuvres d'art ou améliorer des images existantes.
- Intelligence émotionnelle. Bien que les ordinateurs ne puissent pas reproduire les émotions humaines, l'apprentissage profond peut améliorer leur capacité à comprendre les humeurs en analysant des modèles tels que les changements de ton et les expressions faciales. Certaines entreprises utilisent l'apprentissage profond pour interpréter les signaux vocaux et faciaux, tandis que d'autres analysent les interactions du service client afin d'évaluer l'intelligence émotionnelle et de fournir un retour d'information en temps réel pour un meilleur engagement.
- IA interprétable. L'IA interprétable est l'avenir du deep learning. Elle désigne les modèles et les systèmes d'IA dont les processus décisionnels peuvent être compris et expliqués par les humains. L'IA interprétable renforce la transparence, la confiance et la responsabilité dans les systèmes d'IA. Elle permet aux utilisateurs de comprendre comment les modèles parviennent à leurs conclusions, ce qui facilite l'identification et la correction des erreurs ou des biais. À mesure que le deep learning s'intègre davantage dans les applications critiques, l'interprétabilité deviendra essentielle pour une utilisation éthique et efficace.
Découvrez les différences entre le deep learning, le machine learning et d'autres formes d'IA.







