Qu'est-ce qu'un réseau neuronal convolutif (CNN) ?
Un réseau neuronal convolutif (CNN) est une catégorie de modèle d'apprentissage automatique. Plus précisément, il s'agit d'un type d'algorithme d'apprentissage profond qui convient particulièrement bien à l'analyse de données visuelles. Les CNN sont couramment utilisés pour traiter des tâches liées aux images et aux vidéos. Et, comme les CNN sont très efficaces pour identifier des objets, ils sont fréquemment utilisés pour des tâches de vision par ordinateur, telles que la reconnaissance d'images et la reconnaissance d'objets, avec des cas d'utilisation courants incluant les voitures autonomes, la reconnaissance faciale et l'analyse d'images médicales.
Les anciennes formes de réseaux neuronaux devaient souvent traiter les données visuelles de manière progressive, pièce par pièce, en utilisant des images d'entrée segmentées ou de faible résolution. L'approche globale d'un CNN en matière de reconnaissance d'images lui permet de surpasser un réseau neuronal traditionnel dans toute une série de tâches liées à l'image et, dans une moindre mesure, au traitement de la parole et du son.
L'architecture CNN s'inspire des schémas de connectivité du cerveau humain, en particulier du cortex visuel, qui joue un rôle essentiel dans la perception et le traitement des stimuli visuels. Les neurones artificiels d'un CNN sont disposés de manière à interpréter efficacement les informations visuelles, ce qui permet à ces modèles de traiter des images entières.
Les CNN utilisent également des principes issus de l'algèbre linéaire, en particulier les opérations de convolution, pour extraire des caractéristiques et identifier des motifs dans les images. Bien que les CNN soient principalement utilisés pour traiter des images, ils peuvent également être adaptés pour fonctionner avec des données audio et d'autres types de signaux.
Comment fonctionnent les réseaux neuronaux convolutifs ?
Les CNN comportent une série de couches, chacune détectant différentes caractéristiques d'une image d'entrée. En fonction de la complexité de son objectif, un CNN peut contenir des dizaines, des centaines et, dans des cas plus rares, même des milliers de couches, chacune s'appuyant sur les résultats des couches précédentes pour reconnaître des motifs détaillés.
Le processus commence par faire glisser un filtre conçu pour détecter certaines caractéristiques sur l'image d'entrée, un processus appelé opération de convolution, d'où le nom de réseau neuronal convolutif. Le résultat de ce processus est une carte des caractéristiques qui met en évidence la présence des caractéristiques détectées dans l'image. Cette carte des caractéristiques sert ensuite d'entrée pour la couche suivante, permettant à un CNN de construire progressivement une représentation hiérarchique de l'image.
Les filtres initiaux détectent généralement les caractéristiques de base, telles que les lignes ou les textures simples. Les filtres des couches suivantes sont plus complexes, combinant les caractéristiques de base identifiées précédemment pour reconnaître des motifs plus complexes. Par exemple, après qu'une couche initiale ait détecté la présence de bords, une couche plus profonde pourrait utiliser ces informations pour commencer à identifier des formes.
Entre ces couches, le réseau prend des mesures pour réduire les dimensions spatiales (hauteur et largeur) des cartes de caractéristiques afin d'améliorer l'efficacité et la précision. Dans les dernières couches d'un CNN, le modèle prend une décision finale (par exemple, classer un objet dans une image) en fonction des résultats des couches précédentes.
Décortiquer l'architecture d'un CNN
Un CNN se compose généralement de plusieurs couches, qui peuvent être classées en trois grands groupes : les couches convolutives, les couches de regroupement et les couches entièrement connectées. À mesure que les données traversent ces couches, la complexité du CNN augmente, ce qui lui permet d'identifier successivement des portions plus importantes d'une image, ainsi que des caractéristiques plus abstraites.
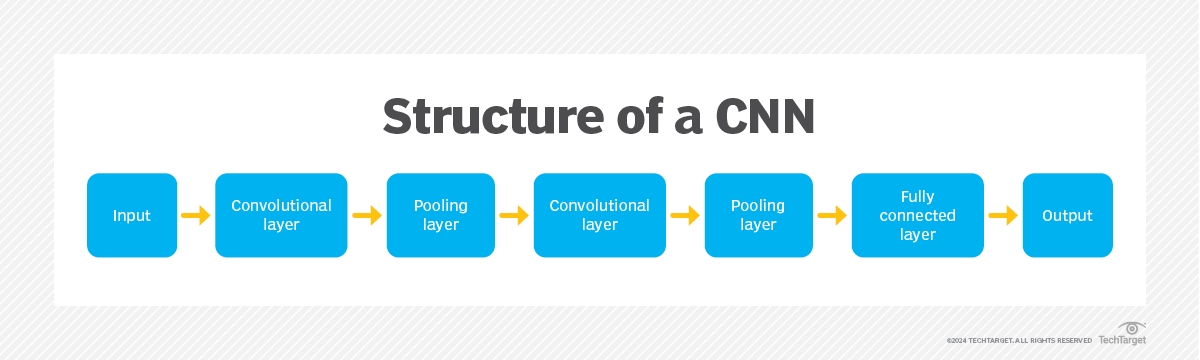
Couche convolutive
La couche convolutive est la partie fondamentale d'un CNN et c'est là que se déroule la majorité des calculs. Cette couche utilise un filtre ou un noyau (une petite matrice de poids) pour se déplacer à travers le champ réceptif d'une image d'entrée afin de détecter la présence de caractéristiques spécifiques.
Le processus commence par faire glisser le noyau sur la largeur et la hauteur de l'image, pour finalement balayer l'ensemble de l'image en plusieurs itérations. À chaque position, un produit scalaire est calculé entre les poids du noyau et les valeurs des pixels de l'image sous le noyau. Cela transforme l'image d'entrée en un ensemble de cartes de caractéristiques ou de caractéristiques convoluées, chacune représentant la présence et l'intensité d'une certaine caractéristique à différents points de l'image.
Les CNN comprennent souvent plusieurs couches convolutives empilées. Grâce à cette architecture en couches, le CNN interprète progressivement les informations visuelles contenues dans les données brutes de l'image. Dans les premières couches, le CNN identifie les caractéristiques de base, telles que les contours, les textures ou les couleurs. Les couches plus profondes reçoivent les données des cartes de caractéristiques des couches précédentes, ce qui leur permet de détecter des motifs, des objets et des scènes plus complexes.
Couche de mise en commun
La couche de regroupement d'un CNN est un composant essentiel qui suit la couche convolutive. À l'instar de la couche convolutive, les opérations de la couche de regroupement impliquent un processus de balayage de l'image d'entrée, mais sa fonction est différente.
La couche de regroupement vise à réduire la dimensionnalité des données d'entrée, tout en conservant les informations essentielles, améliorant ainsi l'efficacité globale du réseau. Cela s'obtient généralement par le sous-échantillonnage, qui correspond au nombre de points de données dans l'entrée.
Pour les CNN, cela signifie généralement réduire le nombre de pixels utilisés pour représenter l'image. La forme la plus courante de pooling est le max pooling, qui conserve la valeur maximale dans une certaine fenêtre (c'est-à-dire la taille du noyau) tout en rejetant les autres valeurs. Une autre technique courante, connue sous le nom de pooling moyen, adopte une approche similaire, mais utilise la valeur moyenne au lieu de la valeur maximale.
Le sous-échantillonnage réduit considérablement le nombre total de paramètres et de calculs. En plus d'améliorer l'efficacité, cela renforce la capacité de généralisation du modèle. Les modèles moins complexes avec des caractéristiques de plus haut niveau sont généralement moins sujets au surajustement, un phénomène qui se produit lorsqu'un modèle apprend le bruit et les détails trop spécifiques dans ses données d'entraînement, ce qui nuit à sa capacité à généraliser à des informations nouvelles et inconnues.
La réduction de la taille spatiale de la représentation présente toutefois un inconvénient potentiel, à savoir la perte de certaines informations. Cependant, l'apprentissage des seules caractéristiques les plus marquantes des données d'entrée est généralement suffisant pour des tâches telles que la détection d'objets et la classification d'images.
Couche entièrement connectée
La couche entièrement connectée joue un rôle essentiel dans les dernières étapes d'un CNN, où elle est chargée de classer les images en fonction des caractéristiques extraites dans les couches précédentes. Le terme « entièrement connectée » signifie que chaque neurone d'une couche est connecté à chaque neurone de la couche suivante.
La couche entièrement connectée intègre les différentes caractéristiques extraites dans les couches convolutives et de regroupement précédentes et les associe à des classes ou des résultats spécifiques. Chaque entrée provenant de la couche précédente est connectée à chaque unité d'activation de la couche entièrement connectée, ce qui permet au CNN de prendre en compte simultanément toutes les caractéristiques lors de la prise de décision finale en matière de classification.
Toutes les couches d'un CNN ne sont pas entièrement connectées. Les couches entièrement connectées comportant de nombreux paramètres, l'application de cette approche à l'ensemble du réseau crée une densité inutile, augmente le risque de surajustement et rend le réseau coûteux à entraîner en termes de mémoire et de calcul. Limiter le nombre de couches entièrement connectées permet d'équilibrer l'efficacité computationnelle et la capacité de généralisation avec la capacité d'apprendre des modèles complexes.
Couches supplémentaires
Les couches convolutives, de regroupement et entièrement connectées sont toutes considérées comme les couches centrales d'un CNN. Cependant, un CNN peut comporter des couches supplémentaires :
- La couche d'activation est une couche couramment ajoutée et tout aussi importante dans un CNN. La couche d'activation permet la non-linéarité, ce qui signifie que le réseau peut apprendre des modèles plus complexes (non linéaires). Cela est essentiel pour résoudre des tâches complexes. Cette couche vient souvent après les couches convolutives ou entièrement connectées. Les fonctions d'activation courantes comprennent les fonctions ReLU, Sigmoid, Softmax et Tanh.
- La couche de dropout est une autre couche ajoutée. L'objectif de la couche de dropout est de réduire le surajustement en supprimant des neurones du réseau neuronal pendant l'entraînement. Cela réduit la taille du modèle et aide à prévenir le surajustement.
Les CNN par rapport aux réseaux neuronaux traditionnels
Une forme plus traditionnelle de réseaux neuronaux, connue sous le nom de perceptrons multicouches, est entièrement composée de couches entièrement connectées. Ces réseaux neuronaux, bien que polyvalents, ne sont pas optimisés pour les données spatiales, telles que les images. Cela peut créer un certain nombre de problèmes lorsqu'on les utilise pour traiter des données d'entrée plus volumineuses et plus complexes.
Pour une image plus petite avec moins de canaux de couleur, un réseau neuronal traditionnel peut produire des résultats satisfaisants. Cependant, à mesure que la taille et la complexité de l'image augmentent, les ressources informatiques nécessaires augmentent également. Un autre problème majeur est la tendance au surajustement, car les architectures entièrement connectées ne donnent pas automatiquement la priorité aux caractéristiques les plus pertinentes et sont plus susceptibles d'apprendre le bruit et d'autres informations non pertinentes.
Les CNN diffèrent des réseaux neuronaux traditionnels sur plusieurs points essentiels. Il est important de noter que dans un CNN, tous les nœuds d'une couche ne sont pas connectés à chaque nœud de la couche suivante. Comme leurs couches convolutives ont moins de paramètres que les couches entièrement connectées d'un réseau neuronal traditionnel, les CNN sont plus efficaces pour les tâches de traitement d'images.
Les CNN utilisent une technique appelée « partage de paramètres » qui les rend beaucoup plus efficaces dans le traitement des données d'images. Dans les couches convolutives, le même filtre (avec des poids fixes) est utilisé pour analyser l'ensemble de l'image, ce qui réduit considérablement le nombre de paramètres par rapport à une couche entièrement connectée d'un réseau neuronal traditionnel. Les couches de regroupement réduisent encore davantage la dimensionnalité des données afin d'améliorer l'efficacité globale et la généralisation d'un CNN.
CNN vs RNN
Les réseaux neuronaux récurrents (RNN) sont un type d'algorithme d'apprentissage profond conçu pour traiter des données séquentielles ou chronologiques. Ils sont capables de reconnaître les caractéristiques séquentielles des données et d'utiliser des modèles pour prédire le scénario probable suivant. Les RNN sont couramment utilisés dans la reconnaissance vocale et le traitement du langage naturel (NLP).
Les RNN et les CNN sont tous deux des formes d'algorithmes d'apprentissage profond. Ils ont également constitué des avancées importantes dans le domaine de l'intelligence artificielle (IA). Et, bien qu'ils aient des acronymes similaires, ils excellent dans des tâches distinctes. Les RNN sont bien adaptés à une utilisation dans le traitement du langage naturel (NLP), l'analyse des sentiments, la traduction linguistique, la reconnaissance vocale et la légende d'images, où la séquence temporelle des données est particulièrement importante. Les CNN, en revanche, sont principalement spécialisés dans le traitement des données spatiales, telles que les images. Ils excellent dans les tâches liées à l'image, telles que la reconnaissance d'images, la classification d'objets et la reconnaissance de formes.
Leurs architectures sont également différentes. Les CNN utilisent des réseaux neuronaux à propagation directe qui utilisent des filtres et diverses couches, tandis que les RNN renvoient les résultats dans le réseau.

Avantages de l'utilisation des CNN pour l'apprentissage profond
Le deep learning, une sous-catégorie du machine learning, utilise des réseaux neuronaux multicouches qui offrent plusieurs avantages par rapport aux réseaux monocouches plus simples. Les CNN, en particulier, offrent divers avantages en tant que processus de deep learning :
- Performant dans les tâches de vision par ordinateur. Les CNN sont particulièrement utiles pour les tâches de vision par ordinateur, telles que la reconnaissance et la classification d'images, car ils sont conçus pour apprendre les hiérarchies spatiales des caractéristiques en capturant les caractéristiques essentielles dans les couches supérieures et les modèles complexes dans les couches plus profondes.
- Performant dans les processus automatiques. L'un des principaux avantages des CNN réside dans leur capacité à extraire ou à apprendre automatiquement des caractéristiques. Cela élimine le besoin d'extraire manuellement les caractéristiques, un processus historiquement laborieux et complexe.
- Réutilisables. Les CNN sont également bien adaptés à l'apprentissage par transfert, dans lequel un modèle pré-entraîné est affiné pour de nouvelles tâches. Cette réutilisabilité rend les CNN polyvalents et efficaces, en particulier pour les tâches avec des données d'entraînement limitées. S'appuyer sur des réseaux préexistants permet aux développeurs d'apprentissage automatique de déployer des CNN dans divers scénarios réels, tout en minimisant les coûts de calcul.
- Efficaces. Comme décrit ci-dessus, les CNN sont plus efficaces sur le plan informatique que les réseaux neuronaux traditionnels entièrement connectés, grâce à leur utilisation du partage de paramètres. Grâce à leur architecture rationalisée, les CNN peuvent être déployés sur une large gamme d'appareils, y compris les appareils mobiles, tels que les smartphones, et dans des scénarios d'informatique de pointe.
Inconvénients liés à l'utilisation des CNN
Les difficultés liées aux CNN peuvent toutefois inclure les éléments suivants :
- Difficile à entraîner. L'entraînement d'un CNN nécessite beaucoup de ressources informatiques et peut nécessiter un réglage approfondi.
- Grande quantité de données d'entraînement requises. Les CNN nécessitent généralement une grande quantité de données étiquetées pour atteindre un niveau de performance acceptable.
- Interprétabilité. Il peut être difficile de comprendre comment un CNN parvient à une prédiction ou à un résultat spécifique.
- Surajustement. Sans couche de dropout, un CNN peut être sujet au surajustement.
Applications des réseaux neuronaux convolutifs
Le traitement et l'interprétation des données visuelles étant des tâches très courantes, les CNN ont de nombreuses applications concrètes, allant du secteur de la santé à celui de l'automobile, en passant par les réseaux sociaux et le commerce de détail.
Les domaines dans lesquels les CNN sont le plus couramment utilisés sont les suivants :
- Santé. Dans le secteur de la santé, les CNN sont utilisés pour faciliter les diagnostics médicaux et l'imagerie. Par exemple, un CNN peut analyser des images médicales, telles que des radiographies ou des lames de pathologie, afin de détecter des anomalies indiquant une maladie, facilitant ainsi le diagnostic et la planification du traitement.
- Automobile. L'industrie automobile utilise les CNN dans les voitures autonomes pour naviguer dans leur environnement en interprétant les données fournies par les caméras et les capteurs. Les CNN sont également utiles dans les fonctionnalités basées sur l'IA des véhicules non autonomes, telles que le régulateur de vitesse automatique et l'aide au stationnement.
- Réseaux sociaux. Sur les plateformes de réseaux sociaux, les CNN sont utilisés dans diverses tâches d'analyse d'images. Par exemple, une entreprise de réseaux sociaux peut utiliser un CNN pour suggérer des personnes à taguer sur des photos ou pour signaler des images potentiellement offensantes afin qu'elles soient modérées.
- Commerce de détail. Les détaillants en ligne utilisent les CNN dans les systèmes de recherche visuelle qui permettent aux utilisateurs de rechercher des produits à l'aide d'images plutôt que de texte. Les détaillants en ligne peuvent également utiliser les CNN pour améliorer leurs systèmes de recommandation en identifiant les produits qui ressemblent visuellement à ceux qui ont suscité l'intérêt d'un acheteur.
- Assistants virtuels. Bien que les CNN soient le plus souvent utilisés pour traiter des données image, les assistants virtuels constituent un bon exemple d'application des CNN aux problèmes de traitement audio. Les CNN peuvent reconnaître des mots-clés prononcés et aider à interpréter les commandes des utilisateurs, améliorant ainsi la capacité d'un assistant virtuel à comprendre et à répondre à son utilisateur.
Les CNN peuvent être utiles dans de nombreux cas différents. Découvrez comment les CNN et d'autres types de méthodes d'apprentissage profond sont utilisés dans le domaine de la santé.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que l'apprentissage automatique (AutoML) ?
Par: Ben Lutkevich
-
![]()
Qu'est-ce que le filigrane IA (AI Watermarking) ?
Par: Lev Craig
-
![]()
Qu'est-ce que l'art de l'IA et comment est-il créé ?
Par: Sean Kerner



