La frugalité de l’IA : un impératif et des solutions
Le développement de l’IA se heurtera à court terme aux limites de l’énergie et des données disponibles. Il est donc critique d’agir en faveur d’une plus grande frugalité. Une solution consiste à favoriser de petits modèles spécialisés.
Les discussions sur la frugalité de l’IA ont semblé être reléguées au second plan avec l’émergence de l’intelligence artificielle générative. Priorité était donnée aux usages et au ROI. Deux après la sortie de ChatGPT, la thématique refait néanmoins surface.
Le mur de l’énergie et des données disponibles
Pour nombre de spécialistes, le sujet de l’impact environnemental de l’IA n’a jamais cessé d’être d’actualité. Ainsi, le 1er juillet était publiée par l’Afnor la première version du référentiel général pour l’IA frugale. Au CEA, la frugalité est également un domaine de recherche continue, comme en témoignait François Terrier le 16 octobre lors de la conférence Big Data & AI Paris 2024.
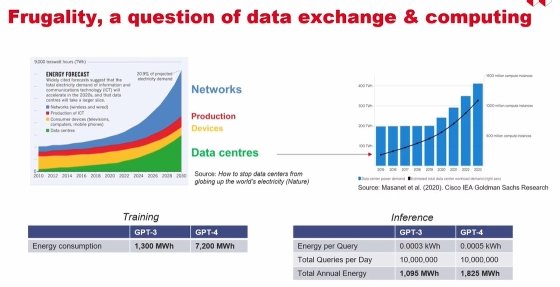
Le directeur des programmes du CEA List y rappelait d’entrée que cet enjeu ne se cantonne pas au domaine de l’IA générative. Certes, la GenAI « prend tout l’espace médiatique […] À date, c’est 15 % du marché… et les prévisions tendent à dire que cela restera 15 % du marché », déclare-t-il. « N’oublions pas les 85 % restants », invite-t-il.
Dans les entreprises, la thématique de la valeur de l’IA préoccupe probablement plus les comités de direction. Mais l’IA frugale devrait aussi les concerner. Car François Terrier insiste : un mur se rapproche à grande vitesse en raison de la convergence entre consommation et production d’énergie. « On ne pourra pas continuer à croître au rythme actuel », prévient-il.
Gourmands en données pour l’apprentissage, les modèles sont en quête permanente de nouvelles sources. Or là aussi, la saturation approche selon les chercheurs du CEA List. Et son directeur de programmes de rappeler que l’infini n’existe pas dans l’univers des technologies.
Raisonner différemment et s’intéresser à des approches alternatives
Ces limitations militent « pour raisonner différemment et s’intéresser à des approches alternatives » dans l’intelligence artificielle. Et attention, il importe d’agir sur l’ensemble du processus de développement.
« Cela ne sert à rien de se focaliser sur un aspect », considère le chercheur. Les mesures doivent concerner par conséquent l’apprentissage, mais également la gestion des données, le model engineering, et l’adaptation au matériel pour l’embarqué.
De même, ralentir ou diminuer la consommation des datacenters – dont les usages auraient basculé au fil des années du stockage au calcul – ne peut constituer le seul axe d’optimisation dans le cadre d’une stratégie de frugalité de l’IA.
En matière de consommation, les chiffres montreraient que « la part des réseaux est équivalente, voire supérieure à celle des datacenters ». Cette réalité traduit un « vrai sujet sur l’utilisation intensive des réseaux », notamment au profit des usages de l’IA.
François Terrier en tire une conclusion : « tout dans le cloud, cela ne tiendra pas ».
Conscients de ce risque, les grands fournisseurs de cloud semblent vouloir réagir en s’alimentant grâce à de nouvelles centrales nucléaires.
Ne pas rester en force brute pour plus de spécialisation
« Tout dans le cloud, cela ne tiendra pas ».
François TerrierDirecteur des programmes du CEA List
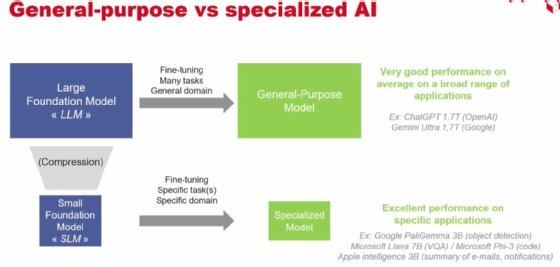
La production énergétique n’est pas le cœur des réflexions du CEA. Deux axes de travail sont explorés. Le premier consiste à « ne pas rester en force brute » sur l’IA, c’est-à-dire à privilégier la puissance et la consommation de ressources. Le chercheur et ses collègues préconisent au contraire de « s’orienter vers le fine tuning » au travers de la spécialisation et de l’adaptation des modèles.
Le deuxième chantier porte sur le rapprochement des processus de développement et des données. Il s’agit de faire en sorte qu’ils « soient au plus près des sources et des usages des données pour réduire les flux de communication ».
Sur la spécialisation, l’approche consiste à opter pour des SLM (« Small fondation models ») dédiés à un sous-domaine et à des tâches plutôt que pour de grands modèles de fondation. Il en ressort « des performances excellentes » pour des applications ciblées.
Le CEA a pu le confirmer en remportant un challenge organisé par la DGA. Trois approches distinctes étaient testées. La première consistait à recourir à un LLM généraliste et à optimiser le prompting pour de l’extraction d’informations dans des documents. Deux autres modèles ont été utilisés, un premier spécialisé de 13 milliards de paramètres, et un second, un SLM de 0,3 milliard fine-tuné avec un petit ensemble de données (complété par des données synthétiques).
Les modèles spécialisés offraient de bien meilleurs résultats sur la tâche confiée. « Lorsqu’on comprend bien le domaine, ce n’est pas forcément un travail énorme pour parvenir à des solutions très performantes et très bien adaptées », considère François Terrier.
La qualité des données : 75 % du travail pour une IA performante
L’optimisation des performances dépend aussi fortement de la qualité des données. Elle représenterait « 75 % du travail à faire pour développer une IA classique avec de bonnes performances », rappelle l’expert.
Dans ce domaine, les actions à mener sont nombreuses (identification des données, cleaning, annotation, enrichissement, etc.). L’amélioration peut s’obtenir par le biais de techniques multiples dont la déduplication, le low quality document filtering, la data mixture et le human in the loop.
L’annotation occupe une place importante dans le développement des IA. Mais elle prend beaucoup en temps. Pour la faciliter, le CEA a conçu un outil d’annotation (en open source), exploité pour ses propres recherches et dans le cadre de ses partenariats industriels : Pixano.
Pixano permet la « pré-annotation » des données (images, vidéos et lidar), une fonctionnalité qualifiée de « particulièrement précieuse » puisqu’elle dégage des gains de temps importants.
Pixano a ainsi été mis à contribution pour déterminer, dans des milliers d’heures de vidéo fournies par Valeo (équipementier automobile), les données pertinentes pour l’apprentissage.
Malgré tout, les chercheurs cherchent aussi à réduire « l’addiction aux données labellisées ».
Lutter contre l’addiction aux données labellisées
Plusieurs techniques existent pour cela, dont le « semi-supervised learning » qui repose sur une architecture à deux niveaux. D’un côté, un maître propose automatiquement une labellisation. De l’autre, un étudiant réutilise ces propositions dans une perspective de convergence et d’amélioration de la performance.
« La boucle des deux permet d’utiliser des données non labellisées », explique le représentant du CEA List. Les bénéfices en matière de coûts et de consommation ne sont pas anodins : 50 fois moins de données seraient nécessaires pour un apprentissage.
Pour agir sur les performances et la frugalité du cycle de développement de l’IA, l’institut de recherche recommande en outre des mécanismes d’optimisation de modèle, comme le pruning et la quantification. Ces techniques permettraient respectivement de réduire la taille (par un facteur 4) sans altérer les performances, et de faire baisser très significativement la consommation d’énergie.
La frugalité, une nécessité pour l’IA embarquée
Dans le domaine de l’IA embarquée (un centre d’intérêt majeur pour le CEA et ses partenaires), la frugalité constitue aussi un enjeu critique. L’institut a même développé sa propre plateforme de deep learning pour l’embarqué : aidge (hébergé par la fondation Eclipse).
« Cela nous permet de mettre des applications 10 fois plus grosses ou de consommer 1 000 fois moins. »
François TerrierDirecteur des programmes du CEA List
Pour François Terrier, la solution « permet la frugalité et l’efficacité » sur les étapes de modélisation, d’optimisation et de déploiement. Elle a été utilisée par des industriels comme Valeo, EDF ou ArcelorMittal pour de l’aide à la conduite, la navigation dans des bâtiments ou du contrôle qualité dans un laminoir.
Le CEA intervient enfin dans la conception d’accélérateurs hardware basse consommation, dont NeuroCorgi. À la clé, un gain énergétique de facteur 10 par rapport à l’état de l’art, c’est-à-dire les « solutions académiques et prospectives les plus avancées. » (sic)
L’économie atteindrait même un facteur 1000 en comparaison des outils commerciaux comme le Jetson Nano et le Raspberry Pi. « Cela nous permet de mettre des applications 10 fois plus grosses ou de consommer 1 000 fois moins » explicite le chercheur.
La conception et le déploiement d’IA frugales sont donc possibles en appliquant ces principes et ces choix technologiques.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM