Snowflake : la stratégie du « tout-en-un » fonctionne
Snowflake affiche désormais un large portfolio de fonctionnalités. Même si tout ce qu’il entend proposer n’est pas disponible, la « vision » convainc déjà les partenaires et les clients existants.
Lors de sa conférence annuelle à San Francisco, l’éditeur a fortement mis l’accent sur l’IA générative. Dans un même temps, le projet n’a pas changé. Depuis quelques années, Benoît Dageville, cofondateur et président du produit chez Snowflake, insiste sur le fait que la société fournit plus qu’un data warehouse, plus qu’un lakehouse, plus qu’une PaaS et donc un cloud. Non plus un « Data cloud », mais un « Data AI Cloud », ajoutent les communicants.
S’il a enchaîné les annonces pendant deux jours, ce n’est que le troisième jour que l’éditeur a présenté une vue d’ensemble de son portfolio.
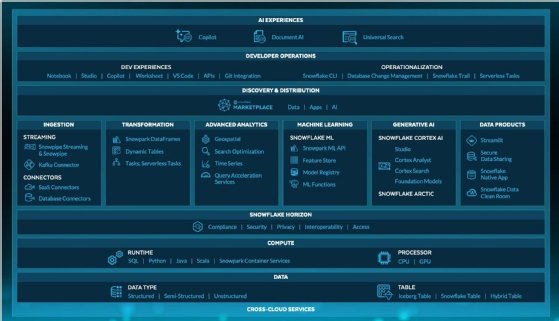
Données structurées et non structurées, prise en charge de quatre langages de programmation, disponibilité d’instances CPU et GPU, couche de gouvernance, ingestions, transformations, analytiques, machine learning, IA générative, partage de données et d’applications, outils pour gérer le tout en sus « d’expériences IA », et ce à travers plusieurs clouds… Sur le papier, Snowflake a tout ce qu’il faut.
L'infographie représente l'ensemble des fonctionnalités et composants de la plateforme Snowflake, mais ne précise pas qu'une bonne partie d'entre eux sont en disponibilité limité.
Sur le papier seulement. Dans les faits, encore beaucoup des fonctions annoncées il y a moins de deux ans sont en préversion publique et privée. Snowflake a misé pendant des années sur ses « fondations », des fondations qu’il continue d’étayer. Il a entamé la prise en charge du machine learning, du deep learning il y a deux ans. En revanche, l’arrivée de Shridar Ramaswamy à la tête de l’entreprise a sûrement permis d’accélérer la part de sa feuille de route consacrée à l’IA générative et de proposer de premiers composants en disponibilité générale, à peine un an après le rachat de sa compagnie Neeva.
IA : Snowflake doit encore faire ses preuves
Les interlocuteurs du MagIT observent, sans surprise, que c’est un sujet populaire. « L’engouement et l’intérêt pour l’adoption de l’IA générative ont accru l’intérêt pour l’IA de manière générale. Il s’agit presque d’une renaissance », juge Jennifer Belissent, principal Data Strategist, chez Snowflake.
« Le portefeuille IA de Snowflake est nouveau ».
Jennifer BelissentPrincipal Data Strategist, Snowflake
Cela ne veut pas dire que Snowflake et les clients sont prêts. « Le portefeuille IA de Snowflake est nouveau », admet l’ancienne analyste chez Forrester. « Il n’y a pas encore grande chose en disponibilité générale aujourd’hui. Nous continuons donc à travailler en étroite collaboration avec un petit groupe de clients qui peuvent tester les produits et nous assurer que nous lançons les meilleures solutions possibles », ajoute-t-elle.
Des expérimentations qui demandent également le concours des partenaires, rappelle Élise Delsol, directrice des partenariats de la région France chez Snowflake.
« Je rappelle que chez Snowflake, nous n’avons pas d’équipes de customer success [un choix délibéré, N.D.L.R.], donc le succès de nos clients, il passe aussi par la capacité de nos partenaires à pouvoir montrer ces nouveaux usages pour les clients existants et convaincre ceux qui ont besoin de mettre dans la main des utilisateurs des outils performants, leur permettant d’obtenir des indicateurs ».
En parallèle, il faut pouvoir améliorer l’accès aux données et leur qualité. « Je ne veux pas dire que les clients ne se souciaient pas de la qualité de données par le passé. Cependant, avec les réglementations en la matière et en matière d’IA, je pense que les gens vont y prêter beaucoup plus attention », considère Jennifer Belissent. « Investir dans la qualité des données est ennuyeux, mais c’est selon moi l’une des choses les plus importantes que nous puissions faire maintenant, parce que nous allons dépendre de plus en plus de l’IA ».
Des prérequis pour bien partager les données et les applications
C’est aussi l’un des éléments cruciaux dans ce qui fait une partie du succès de Snowflake auprès de ses clients les plus matures : le partage de données. « Historiquement, la stratégie de données des entreprises a été centrée sur la gouvernance et la sécurité, mais j’estime que cette notion de partage en interne et à l’externe est cruciale », insiste-t-elle.
Fonctionnellement, Snowflake a fait en sorte le partage des données possible à partir d’un lien URL. Sur sa marketplace, il commence à accueillir les premières « Native Apps », qui, selon Benoît Dageville, « rassemblent des données et du code ». Malgré les premiers cas d’usage, cela reste encore un élément de la « vision » de l’éditeur.
Jennifer Belissent estime toutefois que cela pourrait devenir une nouvelle source de revenus pour des clients prêts à commercialiser sur cette plateforme des applications et des algorithmes. La possibilité de se procurer des modèles et des applications verticalisées sur étagère intéresse Sophie Gallay, directrice données et IT client chez le groupe Etam. « Nous n’avons pas encore eu le temps d’évaluer ce qui est disponible sur la marketplace, mais dans notre domaine d’activité, la distribution, je pense qu’il y a un bon nombre de processus standards qui peuvent être gérés avec des solutions sur étagère ».
« Il faut bien deux à trois ans pour instaurer le libre-service auprès des utilisateurs. Le Data Mesh, cela ne se fait pas en trois mois ».
Laurent LetourmyHead of Data, Devoteam
Selon, Laurent Letourmy, head of Data chez Devoteam, un partenaire intégrateur de Snowflake en France, ces notions de self-service en interne ou externe et d’approche Data Mesh nécessitent pour les clients de revoir leur manière de conduire des projets de données. « Il faut bien deux à trois ans pour instaurer le libre-service auprès des utilisateurs. Le Data Mesh, cela ne se fait pas en trois mois », prévient-il.
« J’explique à nos clients qu’il est dangereux de reproduire les pratiques de gestion de données d’hier, de recréer des monolithes dans le cloud. Quand l’on adopte des domaines de données, quand l’on arrête des modèles à trois couches – au passage, les notions de bronze, silver, gold ne sont autres que l’ODS, le data warehouse et le data mart –, quand l’on versionne ces domaines de données et que l’on a des approches distribuées à l’instar de la gestion d’API, là on devient agile à l’échelle », assure Laurent Latourmy. « Le cloud et Snowflake le permettent ».
Pour le moment, ces migrations ont généralement lieu sur un seul cloud. « Dans un premier temps, les clients investissent majoritairement sur un cloud parce qu’ils ont besoin de migrer leur SI et d’opérer une transformation numérique », note-t-il. « Mais il est évident que l’architecture de données de demain ne dépendra pas d’un seul cloud », poursuit le responsable. « Celui [l’éditeur de plateforme de données] qui gagnera, c’est celui qui sera multicloud par définition, qui n’enfermera pas ses clients et qui offrira une véritable interopérabilité ».
Une présence multicloud à renforcer
Ici, Laurent Latourmy fait référence au déploiement de Snowflake sur les infrastructures des trois géants du cloud et à la prise en charge du format de tables Apache Iceberg en disponibilité générale.
Or cette couverture n’est pas proportionnelle entre les hyperscalers. Actuellement, plus de 75 % des clients de Snowflake, à savoir plus de 7 500 sur 9 800 ont des instances sur AWS. Le reste est partagé entre Microsoft Azure, deux, et Google Cloud, trois.
« Créer une nouvelle région nous réclame beaucoup d’investissements. Nous avons démarré avec AWS, mais c’est beaucoup lié à la demande. Ce n’est pas uniforme dans toutes les régions ».
Benoît DagevilleCofondateur et directeur du produit, Snowflake
« Créer une nouvelle région nous réclame beaucoup d’investissements. Nous avons démarré avec AWS, mais c’est beaucoup lié à la demande. Ce n’est pas uniforme dans toutes les régions », indique Benoît Dageville lors d’un point avec la presse française. « En Europe, nous avons beaucoup de demandes pour Azure. Les relations avec Google sont un peu plus compliquées », lâche-t-il. « Peut-être » parce que BigQuery est un produit d’appel pour Google Cloud et parce que la manière dont GCP opère serait « un peu moins ouverte » que ses concurrents, présume le cofondateur de Snowflake.
La préférence historique de Snowflake et sa perception par les fournisseurs cloud – qui, pour rappel, tente de reproduire des écosystèmes à la Snowflake ou à la Databricks – a forcément des conséquences sur la disponibilité des fonctionnalités. « Nous sommes sur les trois clouds, mais toutes les fonctions ne sont pas disponibles sur tous les clouds ou dans toutes les régions à l’heure actuelle », signale Jennifer Belissent.
Reste que les clients de Snowflake, dont Etam, Eutelsat ou encore Harnois Énergies, rejoignent l’avis de Laurent Latourmy de Devoteam : le « data cloud » a déjà fait ses preuves et continue de susciter leur intérêt.