OKDP : le TOSIT fait la jonction entre Hadoop et la « Modern Data Stack »
TDP, l’alternative open source à Cloudera entre en production chez ses contributeurs qui développent également projet OKDP, sorte d’application de la philosophie Hadoop – la réunion d’outils et de frameworks open source sous la même bannière – à la très éclatée « Modern Data Stack ».
Actuellement, TDP repose « approximativement » sur HDP 3.1.5, la distribution Hadoop d’Hortonworks (elle aussi open source). Le projet est principalement soutenu par la Direction Générale des Finances Publiques (DGFIP), EDF, SNCF ou encore BPCE.
Ces deux dernières années, les travaux de la petite vingtaine de contributeurs ont essentiellement été consacrés à l’automatisation du déploiement des frameworks clés de l’écosystème Hadoop (HDFS, Apache Zookeeper, Hive, Spark, HBase, Phoenix, Knox, Ranger, Tez, Solr) et de quelques « extras » (Apache Kafka, Livy et Airflow). L’interface de déploiement se nomme TDP Manager, un outil motorisé par Ansible, remplaçant d’Ambari. La plateforme est pensée pour la production, dixit les membres du TOSIT.
La version 1.0 de TDP a été lancée en juin 2023. Depuis, une librairie Python a également été ouverte pour compléter les fonctionnalités d’Ansible. Il s’agit de gérer les dépendances et les relations entre les services et les composants, ainsi que de centraliser la configuration des systèmes suivant une définition unifiée des variables. D’autres efforts sont menés pour améliorer l’UI et l’observabilité de la plateforme (Prometheus, Grafana), en sus d’étendre la compatibilité avec les infrastructures cibles. TDP est désormais en version 1.1.
Outre l’évolution et la maintenance du projet, le TOSIT caresse l’ambition que TDP devienne un projet incubé au sein de la fondation Apache.
« Nous sommes en discussion avec la fondation depuis deux ans, et nous avons relancé ces échanges très récemment, cette semaine même », déclare Édouard Rousseaux, responsable technique Big Data chez EDF, lors de l’événement Data & AI Leaders Summit (ex Big Data World). « L’objectif est de concrétiser ce projet dans l’année à venir. Si tout se passe comme prévu, nous pourrions bientôt voir APACHE TDP reconnu en tant que Top-Level Project, ce qui, selon moi, serait une formidable opportunité pour lui donner plus de visibilité et de rayonnement à l’international ».
Pour l’heure, le projet est téléchargé une dizaine de fois par semaine.
TDP entre en production
Tous les membres du TOSIT n’ont pas passé le cap de la production. C’est le cas de la DGFIP qui avait prévu d’effectuer la transition d’Hortonworks vers TDP à la fin de l’année 2023, mais ce déploiement a été reporté en 2024 pour finalement être lancé en janvier 2025.
« Nous avons fait un appel d’offres pour le support de TDP. Nous en avons eu trois réponses et nous sommes en train de les étudier », affirme Aurélie Béguec, cheffe de projet Analyste à la DGFIP. « Il y aura des personnes pour vous accompagner et pour vous aider à le mettre en place [en production] ». Ce marché public de support est interministériel. D’autres administrations entrevoient l’adoption de tout ou partie des briques de TDP.
Pour la DGFIP, l’adoption de TDP a un impact financier important. Pour le moment, environ 160 de ces 700 à 800 applications sont vouées à s’appuyer sur le data lake open source.
En 2020, la DGFIP évaluait le déploiement d’un lac de données sur base Cloudera à plus de 12 millions d’euros (coûts directs et indirects inclus), entre 2020 et 2024. La plateforme Hortonworks 3.1.4 a été mise en production au début de l’année 2021.
« [Le passage à TDP] revêt un enjeu financier, mais aussi d’autonomie ».
Olivier MazainResponsable infrastructure des projets Big Data/IA/ML, DGFIP
« [Le passage à TDP] revêt un enjeu financier, mais aussi d’autonomie », complète Olivier Mazain, responsable en architecture/infrastructure des projets Big Data/IA/ML au sein de la DGFIP. « Nous sommes très portés sur l’open source à la DGFIP », affirme-t-il en prenant l’exemple de la migration de la majorité des bases de données Oracle vers PostgreSQL.
Comme l’OCDE, RTE, et SNCF Réseau, EDF a déjà adopté TDP en production. « Chez nous, Hadoop est utilisé pour propulser des applications critiques en production avec des SLA de 99,95 %. Nous avons déjà fait notre marché de support. Nous avons une société que je peux solliciter 24h/24 et sept jours sur sept en cas d’incident sur les environnements Hadoop-TDP en production », affirme Édouard Rousseaux. « Nous en sommes satisfaits ».
OKDP, une alternative à Databricks et Snowflake
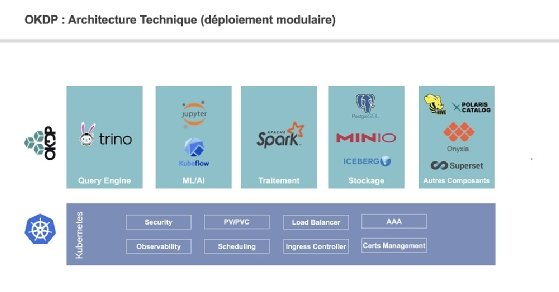
L'architecture modulaire d'Open Kubernetes Data Platform.
En parallèle, le TOSIT mène depuis décembre 2023 un autre projet open source nommé Open Kubernetes Data Platform, ou OKDP.
« OKDP est complémentaire à TDP », indique Mohamed Mehdi Ben Aissa, architecte Data consultant à la DGFIP. « TDP s’appuie principalement sur des technologies Big Data qui fonctionnent très bien dans le cadre d’une architecture centralisée. En revanche, dès qu’il faut traiter un petit volume de données ou bien gérer des besoins plus avancés – par exemple pour le machine learning, le MLOps, l’interrogation interactive, etc. – là, nous avons besoin de quelque chose d’un peu différent ».
OKDP est plus adaptée aux patterns d’architecture décentralisée « de type Data Mesh, Data Fabric ou Lakehouse ». « Le projet rassemble des éléments plus adaptés à une architecture cloud native en mode multitenant », poursuit-il.
Il s’agit de rendre compatible cette plateforme avec le maximum de distributions Kubernetes possible, dont la version open source dite « vanilla », Rancher Kubernetes Engine (RKE), ainsi que les variantes de Nubo, Azure, AWS et Google Cloud (AKS, EKS, GKE).
OKDP réunira des frameworks bien connus, dont Trino, Jupyter, Kubeflow, Apache Spark, PostgreSQL, MinIO, Superset, en sus du projet Onyxia, un environnement de data science contribué par le TOSIT.
Le TOSIT a même prévu de prendre en charge le format de table ouvert Apache Iceberg en sus des métastores Apache Hive et Polaris Catalog (ouvert par Snowflake).
L’intégration d’autres technologies comme Dremio, Apache Kyuubi, MLFlow, Apache Flink, Kafka, mais aussi MongoDB, Cassandra, Flux et Airflow est envisagée.
« Comme avec TDP, l’idée [avec OKDP] est de proposer une solution modulaire capable de s’intégrer aux architectures existantes. Il s’agit encore de proposer des stacks prêtes à la production, sécurisées et hautement disponibles ».
Mohamed Mehdi Ben AissaArchitecte Data, DGFIP
« Comme avec TDP, l’idée est de proposer une solution modulaire capable de s’intégrer aux architectures existantes. Il s’agit encore de proposer des stacks prêtes à la production, sécurisées et hautement disponibles », affirme Mohamed Mehdi Ben Aissa. Le TOSIT entend fournir des flux GitHub Actions réutilisables ainsi que des méthodes déclaratives à base de Flux CD afin d’automatiser les déploiements et d’interconnecter les briques entre elles.
« Si vous avez des contraintes de sécurité, vous pourrez lancer ces flux à l’aide de la technologie Act », précise l’architecte Data chez la DGFIP. L’outil open source Act permet purement et simplement d’exécuter les GitHub Actions sur site.
Justement, en janvier 2024, les contributeurs au projet OKDP ont commencé par la création de pipelines Actions afin d'automatiser le build des environnements JupyterLab. En avril, ils se sont occupés d’intégrer Apache Spark en faisant en sorte que le moteur soit compatible avec les mécanismes d’authentification OIDC. Dernièrement, ils ont intégré le moteur de requêtes SQL distribuées Trino et l’outil de visualisation de données Superset. Une sandbox sera disponible dans quelques jours.
En 2025, il s’agira d’abord de prendre en charge Iceberg et Polaris, puis Kubeflow et MLFlow, l’observabilité d’OKDP, pour enfin proposer un API REST et un front-end d’accès à la plateforme.
En clair, le TOSIT veut se mettre techniquement à niveau des environnements de traitement de données proposés par Snowflake, Databricks ou Cloudera. Le choix de Trino semble évident puisque plusieurs membres du TOSIT ont été convaincus par sa distribution commerciale Starburst.
Derrière le projet, les contributeurs proviennent de la DGFIP qui espère profiter de la participation d’Orange et de BPCE. De manière plus générale, OKDP s’adresse en premier lieu aux data scientists et ingénieurs de données, mais l’association n’écarte pas l’idée de proposer des fonctionnalités pour les data analysts et les métiers.
Des discussions en cours avec OVHcloud
En revanche, le déploiement de TDP et d’OKDP ne paraît pas donné à toutes les organisations. « Il est impossible de faire de l’open source sans une réelle expertise. Cependant, une fois cette expertise acquise, déployer des solutions open source ne prendra pas plus de temps aujourd’hui que dans un cloud public », argumente Édouard Rousseaux.
« Si vous optez pour des solutions en SaaS ou dans le cloud public, vous êtes contraint de suivre la feuille de route et le cycle de mise à jour des éditeurs », poursuit-il. « L’open source vous offre une forme de liberté pour gérer ces évolutions ».
Pour autant, concernant TDP, les administrations pourront s’appuyer sur l’offre de support qui « arrivera très prochainement », selon Aurélie Béguec.
« Nous sommes aussi en contact avec OVHcloud pour [déployer] TDP, je pense qu’ils seront également très intéressés par OKDP », complète Olivier Mazain.
Article mis à jour avec les précisions d'Olivier Mazain et de Mohamed Mehdi Ben Aissa.