
sakkmesterke - Fotolia
NVidia dévoile sa nouvelle génération de GPU "Pascal"
Mardi, à l'occasion de sa GPU Technology Conference de San Jose, NVidia a officiellement annoncé le lancement du Tesla P100, un accélérateur conçu pour le monde du HPC et du machine learning. La carte s'appuie sur sa plus récente architecture GPU, nom de code "Pascal".

NVIDIA a dévoilé mardi sa dernière génération d’accélérateur graphique jusqu’alors connue sous le nom de code « Pascal » (en référence au mathématicien français du même nom). Baptisé Tesla P100, le dernier GPU de la firme est un tour de force technique qui combine de multiples innovations comme l’utilisation de la mémoire HBM2, un nouveau bus de communication ultra-performant baptisé Nvlink ou l’utilisation du dernier processus de gravure en 16nm FinFET de TSMC.
Selon la firme, le GPU Tesla GP100 est un tour de force avec près de 15,3 milliards de transistors soit plus de deux fois plus que les 7,1 milliards du GK110B de la génération antérieure (« Kepler »), qui motorise les actuelles Tesla K40.
Des performances trois fois supérieures à celles du Tesla K40 en double précision
D’un point de vue architecture, les diagrammes d’architecture publiés par Nvidia montrent que le GPU « Pascal » est bâti autour de six « Graphics Processing Clusters » eux-mêmes composés de 10 « streaming multiprocessors ». Chacun de ces SM dispose de 64 cœurs Cuda FP 32 bit (qui peuvent aussi fonctionner en mode 16 bit pour les applications de machine learning et de traitement de signal) et de 32 cœurs Cuda FP 64. Au total, 56 de ses 60 SM sont accessibles par les utilisateurs ce qui veut dire que chaque puce Tesla P100 dispose de 3 584 cœurs 32 bit et 1 792 cœurs 64 bit. Chacun de ces cœurs est cadencé à la fréquence nominale de 1,33 GHZ (contre 745 MHz pour les cœurs du Tesla K40) et peut accélérer jusqu’à 1,48 GHz (810 à 875 MHz pour le Tesla K40).
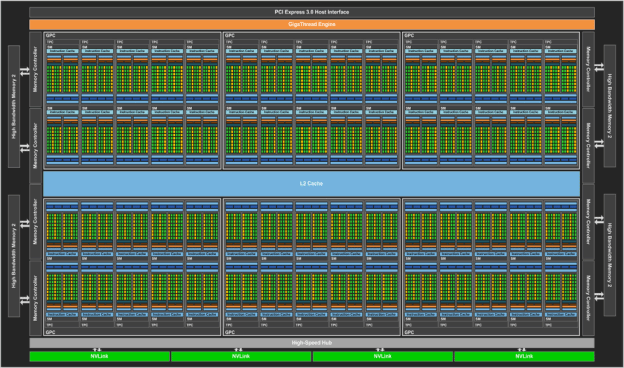 Architecture du Tesla P100
Architecture du Tesla P100
Tous ces cœurs accèdent aux 16 Go de mémoire ECC HBM2 (High bandwidth Memory) via l’entremise de 8 contrôleurs mémoire. Selon Nvidia, la largeur du bus mémoire est de 4 096 bit contre 384 bit précédemment, ce qui permet de doper de façon significative la bande passante mémoire (qui atteint 720 Go/s), tout en abaissant encore un peu plus la latence. À titre de comparaison, la bande passante mémoire d’un des derniers Xeon E5 v4 d’Intel est de 76,4 Go/s avec de la mémoire DDR-4 à 2400 MHz et celle d’un Xeon Phi haut de gamme est de 352 Go/s.
Et les résultats sont impressionnants : Le tesla P100 affiche une performance pic en double précision de 5,3 Teraflops (contre 1,7 Teraflops pour le Tesla K40). Cette performance, passe à 10,6 Teraflops en simple précision et à 21,2 Teraflops en demi-précision. À titre de comparaison, un Xeon Phi 7120X plafonne à 1,2 Teraflops de performance en double précision.
Cette performance a toutefois un prix en termes de consommation électrique puisque le Tesla P100 devrait consommer jusqu’à 300 W. C’est plus que les 235 W de l’actuel Tesla K40 mais similaire au Xeon Phi 7120X.
Le Nvidia DGX1 : un cluster in a box pour découvrir le Tesla P100
Selon Jen Hsun Huang, le CEO de Nvidia, la puce est aujourd’hui en production mais la quasi-totalité de cette production est aujourd’hui déjà allouée aux grands clusters HPC (comme les deux clusters à base de puces Power 8+ et de cartes Tesla P100 du département de l'énergie US) et aux grands fournisseurs de Cloud qui utilisent les GPU de la firme pour leurs besoins de Machine Learning. La carte ne devrait faire son apparition dans les serveurs des grands constructeurs qu’au premier trimestre 2017.
En attendant, l’une des façons de mettre la main sur la puce sera d’acquérir le cluster in a box DGX-1 que Huang a aussi présenté lors de son Keynote. Le DGX-1 est un système rackable 4U qui embarque deux puces Xeon E5-2698 v3 et 8 cartes Tesla P100 reliées par l’interface rapide NVLink du constructeur. La machine est présentée par Nvidia comme le système ultime pour les entreprises qui ont des besoins en matière de machine learning et recherche une infrastructure compacte et performance pour l’apprentissage de modèles de machine learning. La machine est livrée pré-installée avec Ubuntu et le SDK Deep Learning de Nvidia ainsi qu’avec un ensemble de frameworks de machine learning populaires. Notons au passage que Nvidia a mis à jour sa plate-forme CUDA en version 8 avec le lancement du Tesla P100 et que la firme a aussi adapté sa librairie de primitives pour les réseaux neuronaux CuDNN5 au GPU Pascal).
La machine DGX-1 sera proposée aux environs de 130 000 $ et sera disponible dès l'été. Il reste désormais à voir si elle sera compétitive avec les futures offres Intel couplant CPU et FPGA pour la cible d’applications visées par Nvidia.





