
BI : les visualisations les plus populaires (et comment bien les utiliser)
Les modélisations mettent en lumière les données de manière visuelles. En voici douze parmi les plus populaires de la Data Viz, accompagnées de conseils pour choisir la bonne en fonction de l’information à illustrer et pour ne pas faire d’erreur dans les présentations.

La visualisation de données est un élément essentiel de la Business Intelligence (BI). Elle aide les utilisateurs métiers à mieux comprendre la signification des informations extraites des données brutes – soit par des experts (analystes, data scientists, etc.) soit par eux-mêmes, en « libre-service ».
Les bases de la « Data Viz » existent depuis des décennies. Mais les options et les pratiques ont changé au fil des ans. Pas toujours pour le meilleur. Bien souvent, les graphiques sont devenus trop denses et impénétrables aux non spécialistes (or la Data Visualization s’adresse le plus souvent aux métiers).
Actuellement, la visualisation connaît un double mouvement.
« On en revient au point où le besoin du client prime, c’est-à-dire que l’on revient à la clarté et à la simplicité des modélisations », se félicite Gary Davis, UX designer chez CloudCheckr. Car, souligne-t-il, les analystes et leurs représentations cherchent encore et toujours à résoudre le même objectif : communiquer au mieux les résultats qu’ils ont trouvés à une question métier.
Autre mouvement, les spécialistes de la BI et les data scientists utilisent de plus en plus des représentations « sur mesure ». Ce n’est pas incompatible avec les modélisations standards quand elles s’ajoutent à celles-ci. Et « cela peut aider à raconter une histoire d’une manière plus dynamique et plus compréhensible », constate Ramesh Hariharan, CTO de la société de conseils LatentView Analytics.
Mais, ajoute-t-il immédiatement, il faut faire très attention quand on utilise ces techniques « de pointe » et les capacités avancées d’interactions que proposent aujourd’hui les outils. Il ne faut pas tomber dans l’effet de mode ou dans une forme très « design », mais qui ne rend pas le fond plus « consommable ».
Gary Davis, Ramesh Hariharan et plusieurs autres experts de la BI évaluent ici quelques-unes des meilleures – et des pires – manières de faire de la data viz en explorant douze des techniques les plus populaires en entreprise.
Graphiques linéaires
Les graphiques linéaires (ou Line Charts) sont certainement les représentations les plus connues. Bien conçus, ils peuvent être analysés en un coup d’œil. « Rien ne vaut une bonne vieille courbe pour suivre des chiffres au fil du temps », rappelle Paolo Tamagnini, data scientist chez KNIME.
Les graphiques linéaires peuvent aussi montrer différentes mesures d’attributs (comme des catégories), sur des courbes colorées séparées, afin que les utilisateurs puissent les comparer rapidement.
En outre, rendre ces graphiques interactifs peut aider à naviguer parmi un grand nombre de courbes – ce qui pourrait être déroutant avec une visualisation statique.
Par exemple, les graphiques linéaires sont la technique de visualisation la plus utilisée pour comparer les conséquences des mesures de confinement, pays par pays, comme dans l’exemple interactif ci-dessous conçu par Paolo Tamagnini.
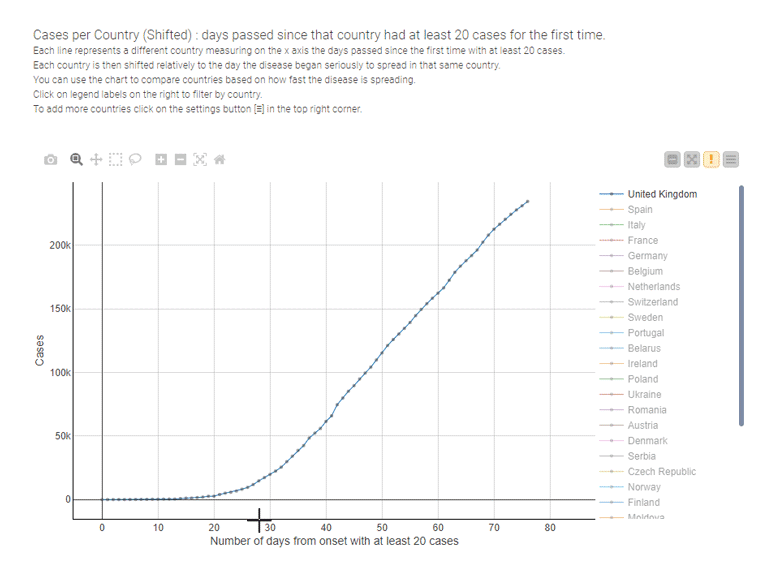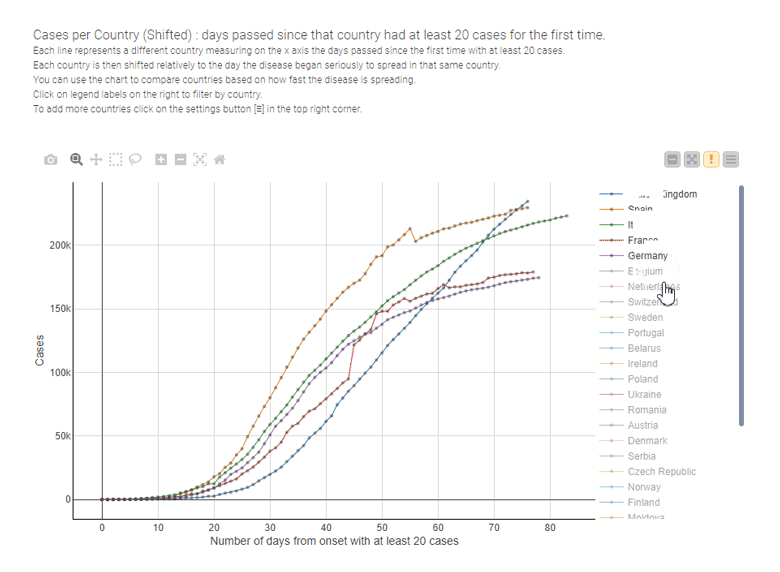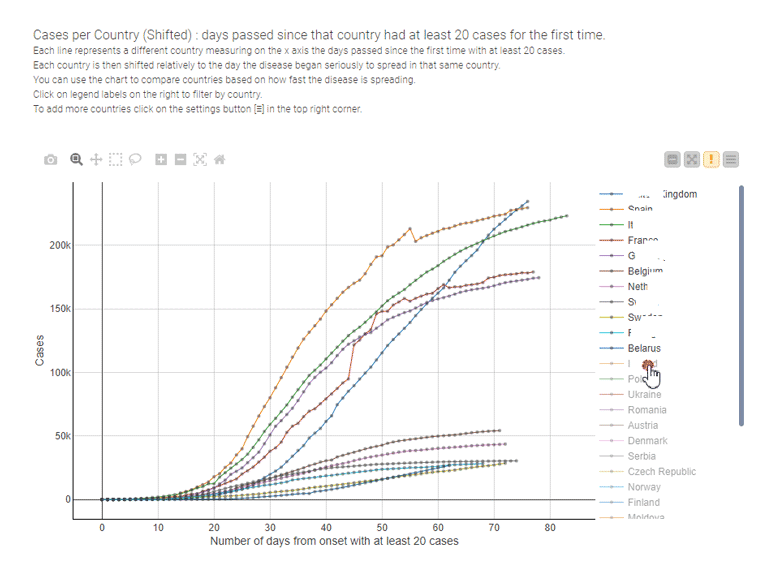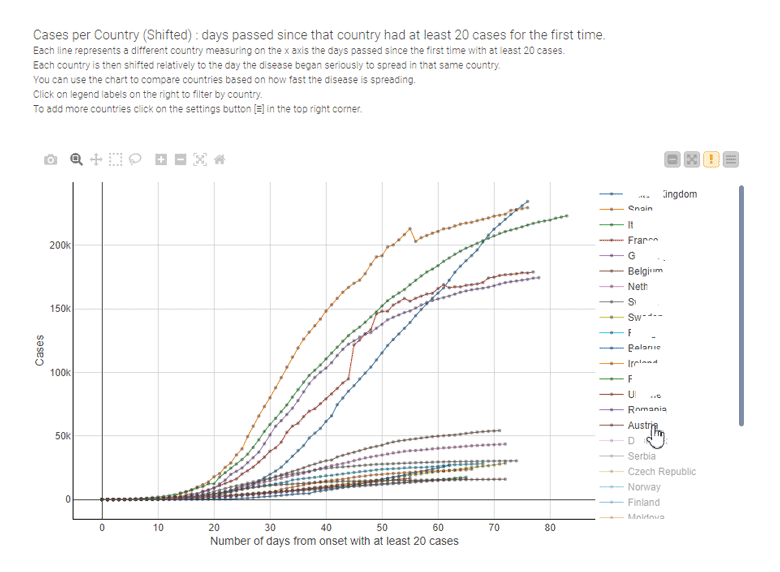
Graphiques en barres
Tout comme les courbes, les diagrammes à barres – ou à bâton (ou Bar Charts) – sont l’une des techniques de visualisation les plus simples et les plus connues. « Les yeux humains sont très doués pour comparer la longueur de barres que l’on a triées – ils ne le sont pas forcément pour comparer des angles, des dégradés de couleurs, ou des formes courbes » compare Paolo Tamagnini. « C’est pour ça que je continue à utiliser des diagrammes à barres chaque fois que je le peux ».
De fait, ce type de graphiques peut être compris par pratiquement tout le monde sans formation ni explication. Mais attention tout de même à la tentation de les rendre trop chargés.
Camemberts
Les diagrammes circulaires (ou « camemberts » en France) sont une autre technique très commune de data viz. Ils modélisent les pourcentages de chaque catégorie qui composent un tout sous la forme de parts de tartes – d’où son nom anglais de « Pie Chart » (par exemple la part de chaque gamme de produits dans un CA global).
Mais, s’ils sont très agréables à regarder, ils sont moins adaptés que les deux techniques précédentes pour faire des comparaisons entre les catégories.
Conséquence, ils peuvent être difficiles à interpréter. « Avec les diagrammes circulaires, les utilisateurs ont du mal à comparer avec précision la taille des parts de tarte », confirme Manjula Mahajan, directeur de la BI chez le spécialiste du stockage NetApp. « Mais ils restent utiles lorsque vous souhaitez faire passer une synthèse globale ou un message général ».

Graphiques à bulles
Les diagrammes à bulles (ou Bubble Charts) sont utilisés pour modéliser trois dimensions de données : les coordonnées x-y de chaque bulle et la taille de celles-ci. On peut y ajouter une quatrième dimension en associant une couleur à chaque bulle.
Avec un minimum d’explications, un diagramme à bulles peut fournir des informations utiles sur des ensembles de données relativement complexes, explique Chris Adams, vice-président de la gestion des produits chez SparkPost, éditeur d’une plate-forme analytique pour les emailings.
Chris Adams recommande toutefois que les étiquettes (labels) des différentes bulles soient clairement visibles et correctement dimensionnées de manière à ne pas se toucher. Enfin, elles doivent être suffisamment différentes pour transmettre rapidement des indicateurs sur les données qu’elles représentent.
Par exemple, dans la visualisation SparkPost ci-dessous, la taille des bulles indique la fréquence relative à laquelle les différents sentiments ont été utilisés dans le champ objet des campagnes de mailing d’une organisation.
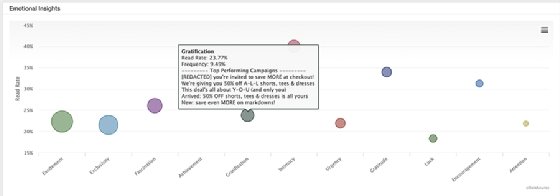
Cela dit, tout le monde n’apprécie pas les « Bubble Charts ». Pour Manjula Mahajan, ils ne sont pas toujours adaptés aux tableaux de bord BI, car ils demandent trop d’effort mental pour être compris « en raison de leur manque de clarté immédiate ».
Histogrammes
Un histogramme est un moyen efficace de visualiser la distribution des valeurs d’un ensemble de données.
Les moyennes sont souvent mal utilisées et peuvent être trompeuses, avertit Daniel Chalef, vice-président de la data science chez SparkPost. Par exemple, la moyenne de la valeur des contrats signés peut être faussée par plusieurs grosses affaires. Pour fournir des informations plus précises, un histogramme montrera le nombre de contrats dans différentes fourchettes de valeurs, comme dans l’exemple ci-dessous.
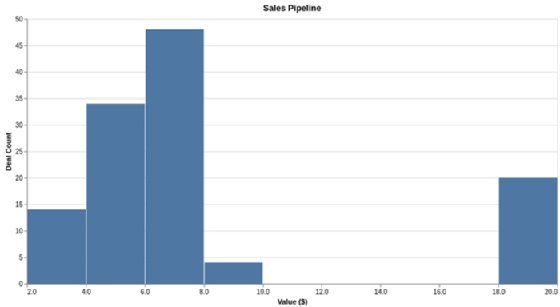
Les histogrammes ressemblent à des diagrammes à barres, mais ils sont spécifiquement conçus pour illustrer la distribution des données. Les plages numériques de même taille dans lesquelles les valeurs des données sont regroupées (en abscisses) sont appelées des « classes » (« bins » en anglais). Une classe peut ne pas avoir de barres si aucune donnée ne tombe dans cette plage. Dans l’exemple ci-dessus, aucun contrat d’une valeur de 10 000 à 18 000 $ n’a été signé.
L’un des points clefs des histogrammes est de s’assurer que les classes sont correctement dimensionnées pour transmettre des informations utiles et pertinentes.
Carte de chaleur
Comme leur nom l’indique, les cartes de chaleur (« heat map » en anglais) recourent à des codes couleurs pour modéliser l’intensité d’une valeur en deux dimensions. L’utilisation classique est de représenter la densité de circulation sur une carte (vert pour peu de voitures, rouge ou noir pour des bouchons).
Cette modélisation n’est cependant pas forcément liée à des cartes géographiques. Par exemple, comme le montre l’exemple ci-dessous, CloudCheckr utilise des cartes de chaleur pour visualiser l’utilisation des ressources cloud dans le temps pour que ses clients puissent voir les bons moments où arrêter ou réduire leurs serveurs et réduire leurs coûts. On pourrait presque parler de « calendrier de chaleur ».
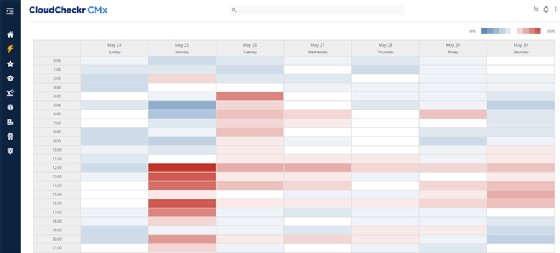
Mais tout comme pour les camemberts, les cartes de chaleur provoquent des avis très partagés. Joshua Moore, spécialiste de l’analytique chez NetApp, ne cache pas que cette visualisation est celle qu’il préfère le moins, du moins quand il s’agit de surveiller le fonctionnement de serveurs. Il y voit souvent des dizaines ou des centaines de KPI. Autre reproche, beaucoup de ces KPI apparaissent « en vert » – ce qui noierait le message avec des informations inutiles puisque ces KPI n’appellent aucune action.
Nuage de points (scatter plots)
Les nuages de points – ou diagrammes de dispersion – sont utiles pour modéliser la densité relative de deux dimensions d’un jeu de données. Bien conçus, ils permettent de quantifier et de corréler des ensembles complexes de données de manière facile à lire. « Souvent, ces diagrammes sont utilisés pour découvrir des tendances plus que pour visualiser les données en elles-mêmes », estime Chris Adams de SparkPost.
Par exemple, le nuage de points ci-dessous permet de corréler (ou non) le nombre de caractères dans l’objet des mails avec leurs taux d’ouverture et de lecture. Il peut aider les spécialistes du marketing digital à identifier les bonnes pratiques et à mieux planifier les futures campagnes.
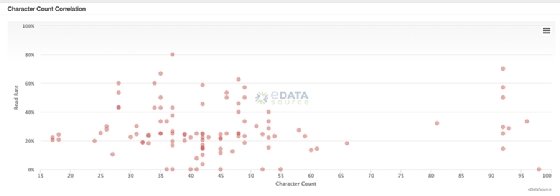
Paolo Tamagnini de KNIME aime utiliser ces diagrammes de dispersion pour montrer les relations entre des points de données de même nature – dans ce cas, ils seraient plus faciles à lire et à interpréter que les diagrammes à barres.
Mais, ajoute-t-il, les nuages de points atteignent leurs limites lorsque l’on essaye de modéliser plus de deux dimensions. De plus, un trop grand nombre de points dans un nuage peut rendre cette visualisation difficile à déchiffrer.
Certains outils comme Numpy offrent pourtant des moyens de contourner ce problème en offrant une représentation en trois dimensions. Cela permet d’observer les nuages de points sous de nouveaux angles et ainsi mieux comprendre les données représentées en comparaison avec un diagramme de dispersion « à plat ».
t-SNE
La technique t – Distributed Stochastic Neighbor Embedding (ou t-SNE) utilise un algorithme de machine learning pour modéliser des données qui ont beaucoup de dimensions sous la forme de points à deux, ou trois dimensions, dans un diagramme de dispersion. On parle de « réduction de dimension ».
Elle utilise des couleurs, des formes ou d’autres éléments visuels pour représenter la troisième dimension. t-SNE a été imaginé pour répondre à certaines limites des visualisations en nuages de points.
Les data scientists se servent de l’algorithme t-SNE pour transformer les relations dans les données brutes afin qu’elles soient plus faciles à visualiser. « L’adoption de techniques de transformation des données, comme celle-ci, est la conséquence directe de l’augmentation de la data literacy et de l’expertise en data science dans le domaine de la visualisation des données », analyse Paolo Tamagnini.
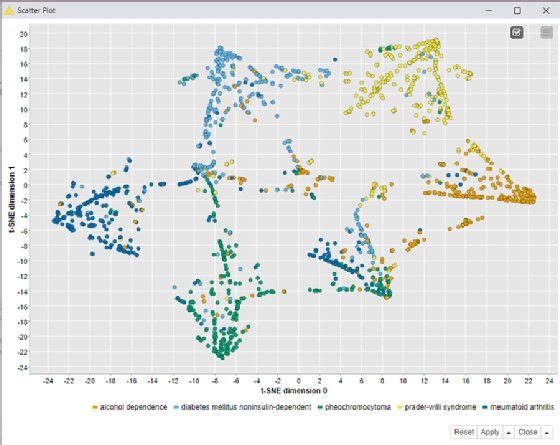
Diagramme de Sankey
Les diagrammes de Sankey représentent des flux de données et de processus par des lignes et des flèches de différentes largeurs – largeurs qui illustrent l’ampleur de chaque flux. Pour Daniel Chalef de SparkPost, c’est un « magnifique outil pour illustrer les flux dans un réseau ».
Un diagramme de Sankey peut être visuellement impressionnant, avertit néanmoins Patrick Miller, spécialiste de la data viz au sein de la société de conseils West Monroe Partners. Mais c’est une technique de visualisation flexible qui peut fonctionner même avec des différences massives dans les données sous-jacentes, ajoute-t-il.
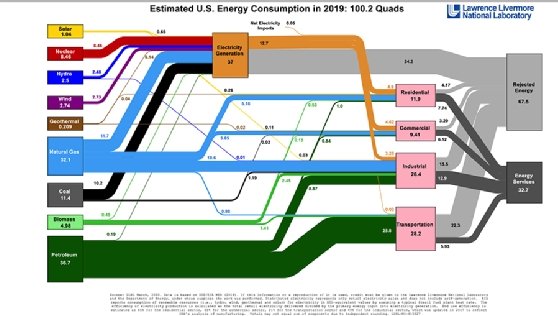
« Un diagramme de Sankey n’est pas facile à comprendre. Il faut l’expliquer à l’utilisateur pour qu’il en tire des informations », souligne Patrick Miller. Il recommande donc d’inclure un texte d’aide dans la visualisation ou dans le tableau de bord auquel il est intégré : idéalement une fenêtre contextuelle qui s’affichera lorsqu’on survolera le diagramme avec la souris (« hover-over »).
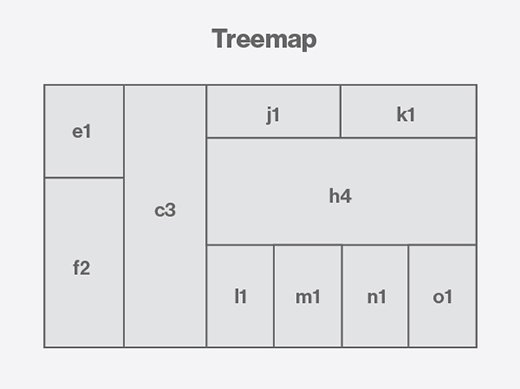
Treemap (carte à cases)
Une carte à case (ou Treemap) affiche des données hiérarchisées en recourant à des blocs imbriqués, de tailles différentes en fonction des valeurs de données qu’ils représentent. Ces blocs sont regroupés dans d’autres blocs pour modéliser la composition de grands ensembles de données.
Par exemple, les administrateurs IT utilisent souvent des cartes à cases (ou cartes proportionnelles) pour suivre l’utilisation de l’espace disque, de la mémoire ou des ressources CPU des systèmes.
Les « cases » (blocs ou rectangles) peuvent aider à identifier des tendances dans les données. Mais les différences de taille (qui sont souvent peu visibles à l’œil), et l’ordre des rectangles (qui modifie la perception de l’ensemble) sont des limites qu’il faut prendre en compte quand on utilise cette visualisation.
Circle Packing
Ce diagramme est une variante de Treemap. Elle utilise des cercles à la place des rectangles.
Pour See Ho Ting, directeur principal du génie logiciel pour les produits réseau Ruckus de CommScope, ces diagrammes sont très utiles pour avoir une vue d’ensemble d’un réseau et illustrer la gravité des problèmes de performance dans différentes sous-parties.
En traçant des cercles de différentes tailles à l’intérieur de plus grands cercles, il est plus facile d’afficher les données du réseau sur trois couches de profondeur – le réseau global, les contrôleurs individuels et les différentes zones à l’intérieur de chaque contrôleur. « Cela permet d’avoir une vue d’ensemble de la santé d’un réseau avec à la fois un balayage rapide de la situation pour les utilisateurs, et une visibilité plus approfondie des problèmes si on le souhaite », illustre See Ho Ting.
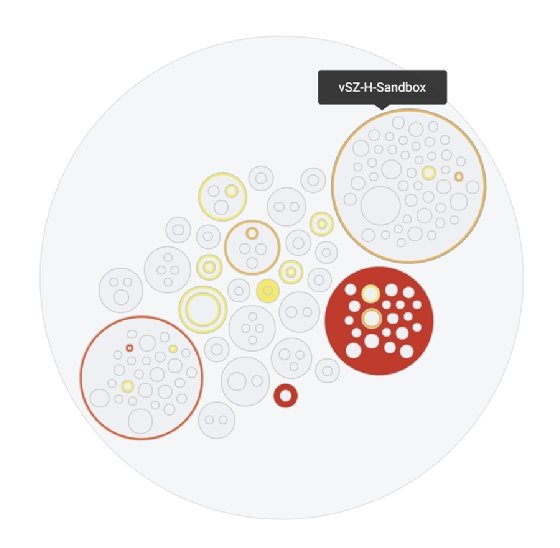
Diagramme de réseau
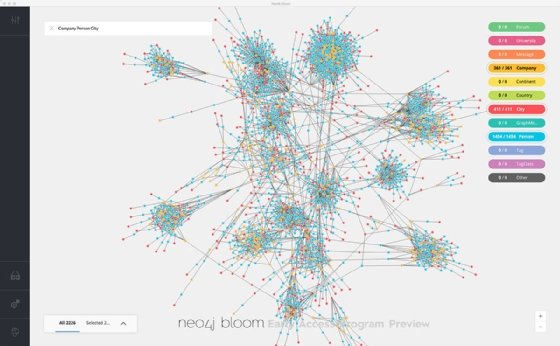
Un diagramme de réseau représente la façon dont des éléments sont connectés en montrant les nœuds et les lignes de liaison entre eux.
« Les diagrammes de réseau aident à modéliser les données qui seraient les plus difficiles à saisir sans visualisation », estime Ramesh Hariharan de LatentView. Les exemples d’applications sont nombreux : les réseaux d’amis et la force de leurs relations, la transmission de données entre systèmes et appareils, les réseaux financiers, la propagation de maladies, le transport et la circulation des personnes, les activités criminelles, etc.
L’un des défis de la conception d’un diagramme de réseau est de déterminer ce qu’il faut montrer… et ce qu’il faut occulter. « Souvent, le diagramme de réseau se présente à la base comme un tas de boue sans motif évident », plaisante Ramesh Hariharan.
Les analystes devront donc d’abord montrer la vue d’ensemble du réseau et, dans un deuxième temps, permettre de creuser (drill down) dans les relations et les données pour avoir plus de détails au fur et à mesure que l’on zoome sur une partie du diagramme, conseille-t-il. Sinon, cette visualisation sera parfaitement indigeste.
Mélanger les visualisations
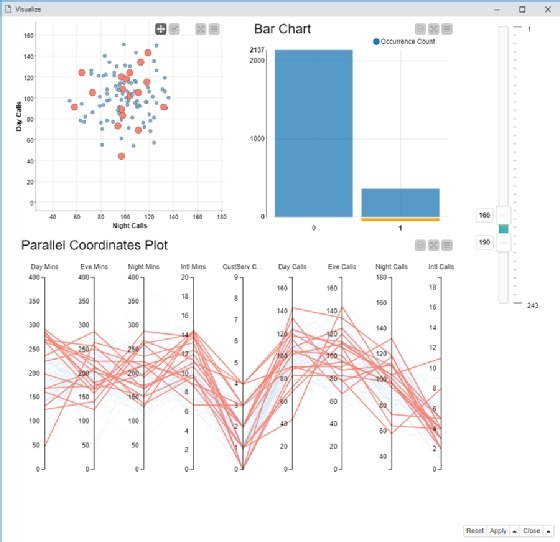
« Chaque technique de visualisation est, en elle-même, terriblement efficace. Mais les combiner, c’est encore mieux », conseille Paolo Tamagnini de KNIME.
Par exemple, combiner un diagramme à barres et un nuage de points (avec un graphique de coordonnées parallèles) – comme dans le tableau de bord ci-dessous – fournit une vue plus détaillée et interactive des données sous-jacentes et donc – ici – de mieux prédire la perte de clientèle (le churn).
La combinaison de trois visualisations permet de sélectionner tous les clients qui ont changé de fournisseur en cliquant sur la colonne associée dans le diagramme en barres. Les données sur le groupe de clients sélectionné sont automatiquement affichées dans les deux autres graphiques pour que les analystes puissent comparer les attributs et voir s’il y a une corrélation entre eux et le taux d’attrition des clients.
C’est une application type du « mantra » du pionnier des interfaces et de la visualisation, le professeur Ben Shneiderman : « d’abord une vue d’ensemble, ensuite des filtres et des zooms, et plus de détails à la demande après ». Imaginé en 1996, ce mantra peut (et doit) encore s’appliquer à ces douze visualisations, quelle qu’elle soit.
Pour approfondir sur Big Data et Data lake
-
![]()
Confluence transforme les contenus en infographies
Par: Philippe Ducellier
-
![]()
Cartographie réseau : 8 outils pour optimiser l’infrastructure
Par: Kinza Yasar
-
![]()
Qu'est-ce que l'architecture des données ? Un plan directeur pour la gestion des données
Par: Craig Stedman
-
![]()
Power BI évolue sous l’influence de Fabric et de Copilot
Par: Gaétan Raoul


