Grafana vs Kibana : le match des outils de visualisation IT
Découvrez comment Grafana et Kibana peuvent aider les administrateurs et SRE à visualiser les données critiques de leurs systèmes grâce à cet exemple de surveillance de la base de données PostgreSQL.

Grafana et Kibana sont deux outils de visualisation de données bien connus des équipes IT. Ils permettent de détecter des tendances dans le comportement des infrastructures et jouent un rôle crucial dans la stratégie de surveillance appliquée par une DSI.
Pour comparer les deux outils, rien de mieux qu’un exemple concret. Dans cet article, nous surveillons une base de données dont les logs et les métriques sont retranscrits visuellement par les deux briques open source. L’objectif, s’assurer que le SGBD fonctionne correctement malgré des problèmes comme la corruption de certains index.
Nous prendrons en compte également la compatibilité des outils avec différentes sources de données, les processus de configuration et de déploiement, ainsi que les diagrammes préprogrammés. Nous jugerons de la pertinence des composants de parsing qui doivent réduire la complexité d’analyse de données. Point important à noter, aucun de ces deux logiciels ne propose une visualisation en quelques clics, à l’instar de Tableau ou de Power BI. Elastic, le principal contributeur propose bien une version simplifiée de Kibana, mais celle-ci ne s’adresse pas vraiment aux responsables d’exploitation.
Les fonctionnalités de Grafana
Grafana aspire les données d’autres systèmes de monitoring et de différentes bases de données. Cet outil open source permet de consulter le code et de contribuer au projet maintenu par Grafana Labs.

Vous pouvez exécuter l’outil sur Grafana Cloud ou l’installer sur site. Hormis l’exemple relatif à ElasticSearch, les scénarios présentés ci-dessus ont été réalisés localement.
Les tableaux de bord de Grafana sont mis au point par un grand nombre de contributeurs. Plus ou moins faciles à utiliser, ils sont néanmoins incontournables, car il n’y a pas besoin de construire des interfaces visuelles de la tête au pied.
Ci-dessous figurent quelques échantillons de tableaux de bord issu de Grafana. Ici les données proviennent de l’agent de monitoring Prometheus.
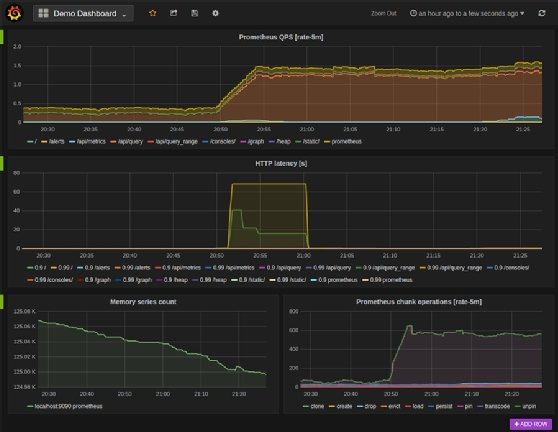
Dans ce deuxième exemple, nous retrouvons la présentation d’alertes.
Les sources de données supportées
Grafana peut tirer des données de différents outils et bases de données dont :
- AWS CloudWatch
- Azure Monitor
- ElasticSearch
- Google Cloud operations suite (ex StackDriver)
- Graphite
- InfluxDB
- Loki
- Microsoft SQL Server
- MySQL
- OpenTSDB
- PostgreSQL
- Prometheus
Exemple d’interprétation de données avec Grafana
Voyons comment l’outil de visualisation interprète les données d’une des sources mentionnées ci-dessus. Ici, nous observons les performances d’un serveur PostgreSQL. Comme avec n’importe quelle base de données, il convient d’identifier les requêtes bloquées, lentes, les problèmes de réplication et d’indexation, ainsi que d’analyser toutes les tables, d’éviter la surcharge de mémoire, les tailles de caches incorrectes, etc. Il faut simultanément prendre en compte les métriques du SGBD en lui-même et les ressources consommées, principalement la RAM et le CPU.
Pour cela, vous devez d’abord modifier la configuration de PostgreSQL : il faut activer la remontée de statistiques de performance. La commande suivante enclenche cette fonction.
sudo vim /etc/postgresql/9,5/main/postgresql.conf
Puis, collez les lignes de commande suivantes :
#------------------------------------------------------------------------------ # RUNTIME STATISTICS #------------------------------------------------------------------------------ # - Query/Index Statistics Collector - track_activities = on track_counts = on shared_preload_libraries = 'pg_stat_statements' track_activity_query_size = 2048 pg_stat_statements.track = all
Ouvrez le shell psql et exécutez cette requête :
CREATE EXTENSION pg_stat_statements;
Créer une source de données
Comme avec n’importe quel système de visualisation, la première étape est de connecter la source de données, comme l’illustre l’image ci-dessous. Nous devons d’abord créer une requête, puis le graphique associé.
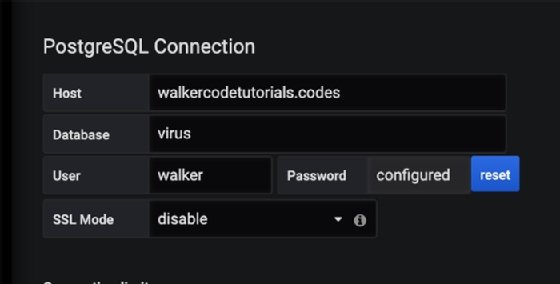
Grafana ne reconnaît pas automatiquement si une source de données provient du trafic réseau, d’un système d’exploitation, d’une base de données ou autre. Au lieu de générer une requête, c’est à vous d’attribuer les bonnes colonnes.
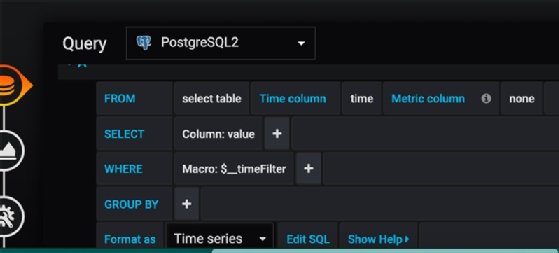
Dans l’image suivante figure un outil de construction de requêtes SQL dans lequel vous choisissez une table et des colonnes. Il doit y avoir une colonne dans la table nommée Time. Si vous n’avez pas cette colonne, vous devrez en ajouter une avec une requête ou une fonction. (Ceci diffère de Kibana, qui ajoute automatiquement un @timestamp à chaque entrée qu’il rassemble.) Créez une formule ou utilisez le bouton « Edit SQL » montré dans l’image ci-dessous pour en écrire une.
Grafana dispose d’un grand nombre de fonctions mathématiques, d’exploration d’historique et de statistiques, qui sont utilisées pour effectuer des calculs et créer des graphiques. Par exemple, vous pouvez tracer une moyenne glissante sur une frise chronologique. Cela permet de réduire l’impact des valeurs aberrantes qui peuvent masquer une tendance à la hausse ou à la baisse d’une mesure. Ces fonctions vous aident également à trouver les statistiques importantes pour le suivi des métriques, notamment les quartiles et la variance.
Ajouter une requête PostgreSQL
Avec PostgreSQL, nous écrivons une requête SQL pour ajouter une colonne Time :
PRE select stats_reset as time, tup_fetched , tup_returned tup_inserted , tup_updated, tup_deleted from pg_stat_database where stats_reset is not null;
Le menu déroulant de la table n’affiche pas la table pg_stat_database, qui est l’endroit où PostgreSQL rassemble certaines de ses données de performance. Vous devez utiliser l’éditeur SQL. Lorsque vous le faites, Grafana affiche un petit graphique qui présente les mesures qu’il a recueillies.
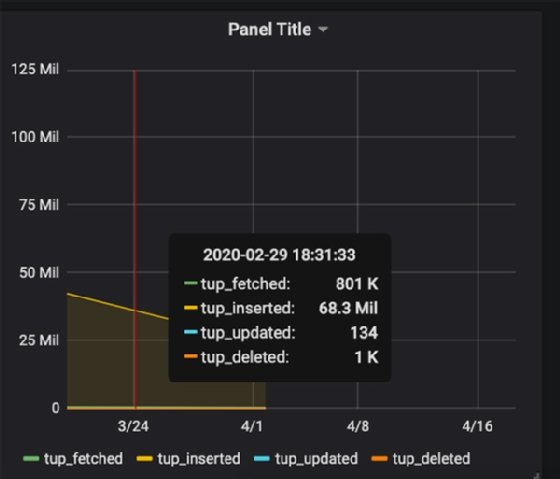
À vous maintenant de bâtir le graphique final.
Visualiser des données ElasticSearch dans Grafana
Voici un rapide exemple pour comprendre comment Grafana interagit avec les données en provenance d’ElasticSearch.
Il faut créer une source de données et sélectionner un index en provenance de l’outil de monitoring.
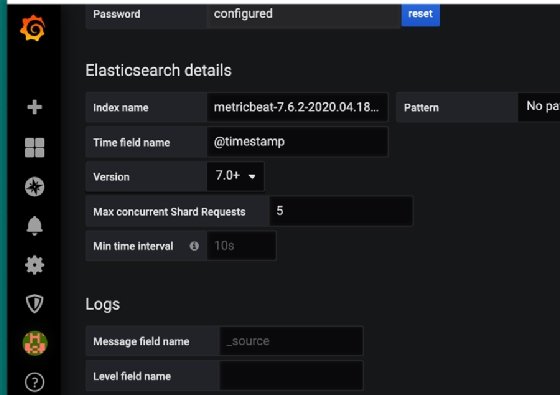
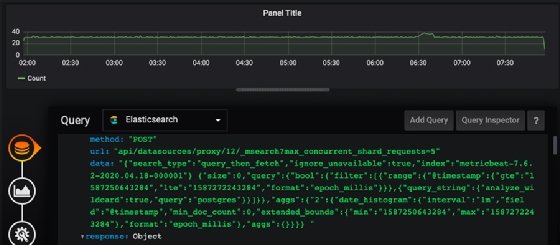
Sans créer un graphique, vous pouvez observer le résultat de cette requête de type heartbeat appliqué à PostgreSQL.
Les plug-ins et la tarification de Grafana
Grafana dispose d’un grand nombre de templates de graphique, nommé plug-ins qu’il faut installer à l’aide du CLI inclus :
grafana-cli plugins install grafana-piechart-panel
Ils sont différents des tableaux de bord complets proposés par les contributeurs. Ces plug-ins correspondent à des types de graphiques et non des outils de visualisation préprogrammés pour s’adapter à certaines sources de données. Pour la version de standard de Grafana dans le cloud, il faut débourser 49 dollars par mois pour dix utilisateurs, 3 000 séries (une série correspond à un graphique) et 100 Go de stockage de logs. Chaque utilisateur supplémentaire coûte 5 dollars par mois. Le prix initial de rétention de logs à long terme (deux ans) à 16 dollars pour 1 000 séries par mois. Au-dessus de 100 Go de logs, il faut payer 50 centimes de dollars par gigaoctet supplémentaire par mois.
Kibana, la couche de visualisation associée à ElasticSearch
Kibana n’est pas un produit standalone. C’est la couche de visualisation associée à ElasticSearch, une base de données conçue pour stocker des documents JSON associés à un moteur de recherche distribué. Kibana, c’est le K dans ELK, la suite Elasticsearch – Logstach – Kibana. Lui aussi est compatible avec un grand nombre de sources de données.
Elasticsearch fournit un middleware de transfert de données appelé Beats pour analyser les logs de ces produits ou se connecter à ceux-ci. Ceux-ci divisent les champs à l’aide d’expressions régulières afin qu’ils puissent être étiquetés et chargés dans Kibana et Elasticsearch. Cela évite aux utilisateurs d’avoir à écrire eux-mêmes ces parseurs.
Il existe différents agents Beats, notamment Filebeat (applications qui produisent des logs), Metricbeat (applications auxquelles Elasticsearch peut se connecter directement) et Packetbeat (trafic réseau). Metricbeat rassemble une longue liste de plus de 3 000 métriques.
Surveiller PostgreSQL avec Kibana
Pour illustrer les différences entre Kibana et Grafana, nous souhaitons reproduire ce que nous avons fait avec PostgreSQL. Le moyen le plus rapide pour commencer à utiliser ELK, c’est de passer par la version d’essai de 14 jours proposé par Elastic. Celle-ci est disponible via GCP, AWS ou Microsoft Azure. Ensuite, nous installons l’agent Metricbeat sur notre serveur local pour rassembler les métriques et les transmettre à Kibana. (Vous pouvez utiliser un conteneur Docker ou lancer l’apt-get install Metricbeat après avoir ajouté Elastic à votre dépôt de code source.)
Ensuite, il faut ouvrir le fichier de configuration Metricbeat en utilisant cette commande :
sudo vim /etc/metricbeat/metricbeat.yml
Nous pouvons entrer nos identifiants dans le fichier.
cloud.id : tech_target:XXXXXXX # The cloud.auth setting overwrites the 'output.elasticsearch.username' and # 'output.elasticsearch.password' settings. The format is '<user>:<pass>'. cloud.auth : elastic:XXX
Puis, nous exécutons la commande suivante pour créer le fichier de configuration PostgreSQL pour Metricbeat :
sudo metricbeat modules enable postgresql
Nous exécutons ce fichier pour pousser le tableau de bord PostgreSQL dans Kibana :
sudo metricbeat setup
Maintenant, nous lançons Metricbeat en premier plan. Si cela ne fonctionne pas, il faut vérifier la présence d’erreurs et les corriger.
sudo metricbeat -e
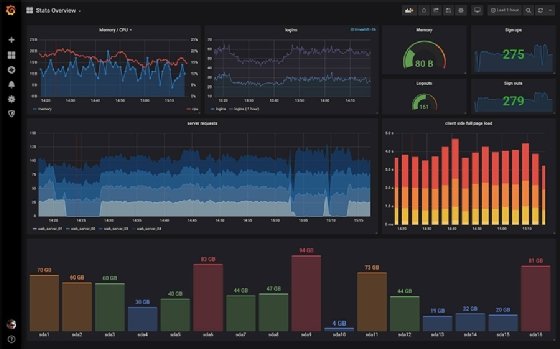
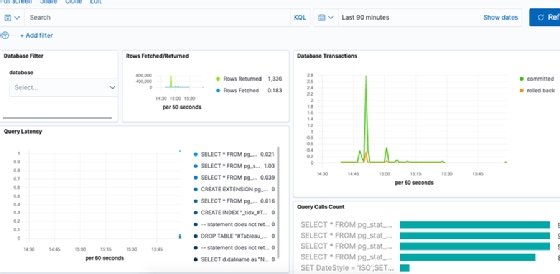
Nous exécutons quelques requêtes dans PostgreSQL pour générer du trafic. Puis, nous cliquons sur l’écran « Dashboard » dans Kibana pour y trouver le tableau de bord associé à notre base de données.
Le tableau de bord dispose de plusieurs sections. Dans l’image ci-dessous figurent les transactions, la latence des requêtes et d’autres métriques.
Les plug-ins de Kibana et la tarification
Il existe toute une série de plug-ins tiers pour Kibana, dont beaucoup répondent à un cas d’usage très spécifique. Par exemple, il existe des plug-ins de visualisation de données qui prennent en charge les graphiques et les diagrammes en 3D.
Le prix d’Elastic Cloud, qui comprend les versions hébergées d’Elasticsearch et de Kibana, commence à 16 dollars par mois pour une installation en vue d’un seul utilisateur. Les prix augmentent en fonction de la taille des serveurs et du stockage.
Pour approfondir sur Administration de systèmes
-
![]()
Moteur de recherche : Manticore Search se veut plus rapide qu’ElasticSearch
Par: Stéphane Larcher
-
![]()
Elasticsearch et Kibana « à nouveau open source »
Par: Gaétan Raoul
-
![]()
Elastic 8.0 : toujours plus d’IA dans Elasticsearch
Par: Sean Kerner
-
![]()
DbaaS : Aiven entend faire mieux que les services de GCP, Azure et AWS
Par: Gaétan Raoul



