
Comprendre les bases de l’architecture de Ceph
Ceph est en quelques années devenu la technologie qui compte dans le monde du stockage open source, en particulier du fait de son intégration avec OpenStack et de sa polyvalence. LeMagIT fait le point sur la technologie et les bases de son architecture.

Afin de réduire leurs coûts de stockage, mais aussi leur dépendance vis à vis des grands fournisseurs de systèmes de stockage traditionnels, de plus en plus d’entreprises sont tentées d’utiliser les solutions de software defined storage libres, notamment lorsqu’elles déploient des technologies de cloud comme OpenStack ou des technologies d’analyse Big Data comme Hadoop/Spark.
L’une des technologies de stockage open source les plus prometteuses et les plus populaires est Ceph, une technologie dont le principal sponsor, Inktank, a été racheté en avril 2014 par Red Hat. Ceph est un système de stockage distribué qui a la particularité de délivrer à la fois des services de stockage en mode bloc (par exemple pour le stockage de VM), des services de stockage en mode objet (compatibles S3 et Swift) et depuis peu des services en mode fichiers (via CephFS). Ceph est notamment devenu populaire dans le monde du stockage du fait de ses nombreux points d’intégration avec OpenStack qui en font la technologie de stockage la plus déployée avec le framework de cloud libre.
L’architecture de Ceph est une architecture distribuée et modulaire. Elle permet de mettre en œuvre des systèmes de stockage couvrant un large spectre de besoin. Selon le type de serveurs mis en œuvre, la nature du stockage utilisé et la performance des interfaces réseaux, il est possible de bâtir des configurations répondant à des contraintes différentes. On peut ainsi créer des clusters optimisés pour servir des workloads transactionnels requérant un nombre d’IOPS élevés (plusieurs centaines de milliers voire quelques millions d’IOPS).
La latence reste toutefois un problème notamment pour les usages en mode bloc, puisqu’elle est fréquemment de quelques dizaines de millisecondes avec des disques, et qu’il faut de conséquentes optimisations (comme celles réalisées par SanDisk sur son implémentation de Ceph avec son système de stockage 100% Flash InfiniFlash) pour passer sous la barre de la dizaine de millisecondes de latence.
À titre de comparaison, un système de stockage distribué en mode bloc comme ScaleIO affiche des latences sous la barre de la milliseconde avec des SSD – mais il n’offre ni mode objet, ni mode fichiers. Notons que les performance devraient s’améliorer significativement dans la prochaine version de Ceph (nom de code “ Kraken”) attendue à l’automne 2016. Cette version devrait marquer l’arrivée en version stable de la technologie BlueStore qui pourra remplacer les filesystems traditionnels comme ext ou xfs utilisés pour gérer les disques durs (ou OSD, voir plus bas) utilisés par Ceph.
Pour les plus aventureux, ou ceux disposant d’équipes systèmes maîtrisant Linux ainsi que les concepts essentiels d’un système de stockage, il est possible de déployer Ceph depuis la plupart des dépôts des grandes distributions Linux puis de le paramétrer selon ses désirs. Plusieurs éditeurs comme Red Hat et Suse proposent aussi des éditions de Ceph prépackagées accompagnées d’outils additionnels d’administration. Ces éditions permettent à une entreprise de bâtir son propre système de stockage à partir de serveurs standards tout en bénéficiant de la réassurance et du support d’un éditeur.
Ceph est déjà utilisé par des acteurs du monde hyperscale (plusieurs exaoctets chez Yahoo pour son “Yahoo Cloud Object Store”), des acteurs du monde du cloud comme CloudWatt, la division cloud public d’Orange Business Services, ou OVH et par de grands utilisateurs comme Deutsche Telekom en Allemagne, le CERN à Genève, l’Université de Nantes, Crédit Mutual Arkea, Thales, Ubisoft ou l’INRA en France. De grands industriels comme PSA s’intéressent aussi à la technologie, de même qu’Air France ou Airbus.
Un système de stockage polyvalent
Un système de stockage Ceph se présente sous la forme d’un cluster de nœuds serveurs (en général des machines standards x86 équipées de disques et/ou de SSD et interconnectées par un réseau rapide à 10 Gbit/s ou plus). Chaque nœud serveur fait tourner de multiples processus chargés de traiter les requêtes d’entrées/sorties, de distribuer les données, de répliquer les données, d’assurer leur intégrité (via un processus de scrubbing régulier) et de gérer les défaillances (et les reconstructions éventuelles de données qui s’ensuivent).
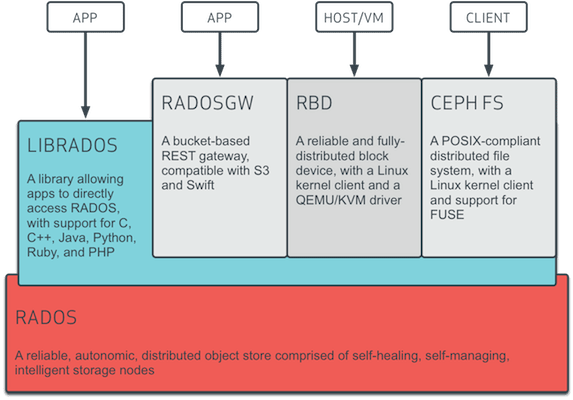 Les différents modes d'accès à Ceph (Source : Red Hat)
Les différents modes d'accès à Ceph (Source : Red Hat)
- Un mode natif à Ceph via la librairie LIBRADOS. Des librairies sont proposées pour la plupart des langages de programmation communs comme C, C++, Java, Python, Ruby ou PHP.
- Un mode de stockage objet : via la passerelle RADOSGW, Ceph propose un mécanisme de stockage objet de type “bucket” accessible via des API compatibles avec Amazon S3 et OpenStack Swift.
- Un mode de stockage en mode bloc : via le pilote noyau RBD, un hôte Linux peut monter un volume Ceph et l’utiliser comme un disque local. Des intégrations sont aussi fournies avec KVM/QEMU pour fournir du stockage en mode bloc à des machines virtuelles.
- Un stockage en mode fichier : via CephFS, Ceph propose depuis peu un accès en mode fichiers compatible POSIX et intégré avec OpenStack Manila. CephFS est considéré comme stable depuis la version actuelle de Ceph (nom de code “Jewel”). La mise en œuvre de CephFS nécessite l’installation de serveurs de métadonnées spécifiques en plus des serveurs habituellement déployés pour un cluster Ceph. Certaines fonctions restent expérimentales comme la mise en œuvre de plusieurs systèmes de fichiers sur un même cluster ou les snapshots.
Une architecture modulaire et distribuée
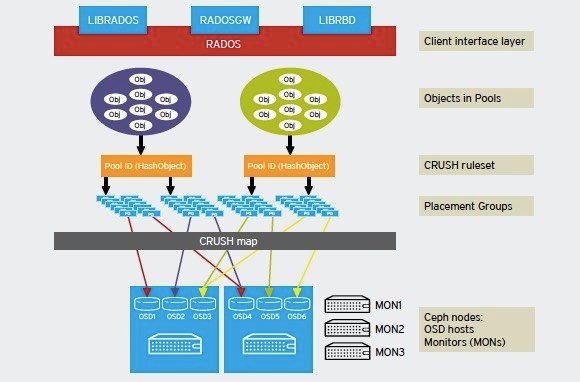 Architecture de Ceph (Source : Red Hat)
Architecture de Ceph (Source : Red Hat)
Comme le montre le schéma ci-dessus, l’architecture de Ceph est modulaire. Elle repose sur plusieurs concepts propres au système de stockage open-source :
- Les pools Ceph : Un cluster Ceph stocke les données sous forme d’objets stockés dans des partitions logiques baptisées “pools”. À chaque pool Ceph correspond un ensemble de propriétés définissant les règles de réplications (le nombre de copie pour chaque donnée inscrite) ou le nombre de groupes de placement (placement groups) dans le pool. Les pools peuvent être répliqués ou protégés par l’utilisation de code à effacement (erasure coding). Dans un pool répliqué, le système stocke autant de copies que spécifié de chaque donnée (le coût de stockage augmente linéairement avec le nombre de copies spécifié). Par exemple, si l’on a spécifié trois copies et que le cluster dispose de trois nœuds, la triple réplication permet de survivre à deux pannes de nœuds ou à la panne de deux disques. Dans un pool Ceph avec erasure coding, chaque objet écrit sur le cluster est découpé en n segments (avec n=k+m, ou k est le nombre de segments de données et m le nombre de segments contenant des données de parité). Il est possible de spécifier le domaine de faille (par exemple un rack) de telle sorte que par exemple, dans un schéma ou n=3+2, les données seront réparties sur des disques situés dans cinq racks différents . À l’extrême, les données peuvent ainsi survivre à deux pannes complètes de rack. Il est à noter que Ceph propose aussi un mécanisme de snapshot de pool.
- Les Ceph OSD : Physiquement, les données sont stockées sur des disques ou SSD formatés avec un système de fichiers comme ext ou XFS (l’usage d’ext4 est recommandé) et que Ceph baptise Ceph OSD (Ceph Object Storage Device). À chaque OSD correspond un démon chargé de stocker les données, de les répliquer ou de les redistribuer en cas de défaillance d’un équipement. Chaque démon OSD fournit aussi des informations de monitoring et de santé aux moniteurs Ceph. Un cluster Ceph doit à minima disposer de deux démons OSD (3 sont recommandés) pour démarrer. Il est à noter que Red Hat préconise de réserver l’usage de serveurs de stockage denses avec 60 ou 80 disques, comme les serveurs Apollo d’HP, pour des clusters de plusieurs Pétaoctets afin d’éviter des domaines de faille trop grand. La préconisation est qu’un serveur unique ne devrait jamais contenir plus de 10 à 15% de la capacité totale d’un cluster, afin de minimiser les risques de perte de données. De même, aucun serveur ne devrait fonctionner à plus de 80% de sa capacité disque, afin d’offrir assez d’espace pour la redistribution des données des nœuds défaillants. Notons par défaut Ceph journalise les opérations de chaque OSD sur le disque de l’OSD lui même. Il est toutefois possible d’optimiser les performances en dédiant un disque à la journalisation des opérations effectuées sur les l’ensemble des OSD d’un serveur. Il est recommandé pour des performances optimales que ce disque de journalisation soit un SSD.
- Groupes de placement. Un groupe de placement est un conteneur logique utilisé par Ceph pour segmenter la distribution des objets entre OSD. Les groupes de placements sont en fait des fragments de pools assignés à des OSD spécifiques. L’idée est en particulier de créer un niveau d’indirection supplémentaire afin de faciliter l’équilibrage des données dans les clusters, mais aussi de faciliter les reconstructions de données en cas de panne d’un composant. Lors de la création d’un pool, il est impératif de fournir le nombre de groupes de placement que l’on souhaite mettre en œuvre. L’algorithme de distribution de données de Ceph, baptisé Crush, utilise en effet cette valeur pour distribuer les données.
- Crush ruleset. L’algorithme CRUSH est le mécanisme mis en œuvre par Ceph pour calculer l’emplacement de chaque donnée écrite sur le cluster. Cette méthode algorithmique permet aux clients Ceph de communiquer directement avec les OSD évitant ainsi l’utilisation d’un service centralisé pouvant être source d’un point de faille unique ou de problèmes de performances.
- Les moniteurs (Mons) Chaque cluster Ceph nécessite la mise en œuvre de moniteurs installés sur des serveurs indépendants. Ces moniteurs sont utilisés par les clients Ceph pour obtenir la carte la plus à jour du cluster. Les moniteurs s’appuient sur une version modifiée du protocole Paxos pour établir entre eux un consensus sur la cartographie du cluster. Cette utilisation de Paxos suppose idéalement l’utilisation d’un nombre impair de moniteurs afin de faciliter l’établissement du quorum. Il est théoriquement possible de faire fonctionner un cluster cep avec un unique moniteur mais l’idéal est un minimum de trois moniteurs pour éviter un point de faille unique.
Comprendre le chemin de données dans Ceph
Selon Red Hat, une opération typique de lecture ou d’écriture de données avec Ceph se déroule de la façon suivante :
1. le client Ceph installé sur l’hôte contacte un moniteur Ceph pour obtenir une version à jour de la carte du cluster.
2. Les données sont converties en objets (contenant un identifiant d’objet et de pool).
3. L’algorithme Crush détermine le groupe ou placer les données et l’OSD primaire.
4. Le client contacte l’OSD primaire pour stocker/récupérer les données.
5. L’OSD primaire effectue une recherche Crush pour déterminer le groupe de placement et l’OSD secondaires.
6. Dans un pool répliqué, l’OSD primaire copie l’objet vers l’OSD secondaire.
7. Dans un pool avec erasure coding, l’OSD primaire découpe l’objet en segments, génère les segments contenant les calculs de parité et distribue l’ensemble de ces segments vers les OSD secondaires toute en écrivant un segment en local.
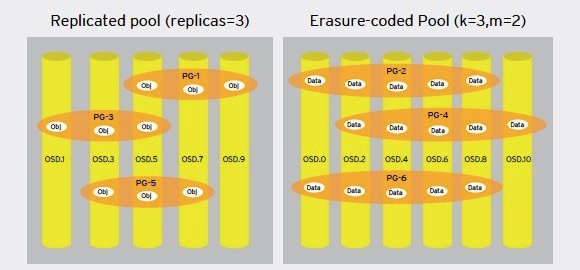 Exemple de liens entre pools, groupes de placement et OSD dans des pools répliqués et utilisant l’erasure coding. Il est à noter le mode bloc n’est supporté que sur les pools répliqués et pas sur les pools avec erasure coding (Source : Red Hat)
Exemple de liens entre pools, groupes de placement et OSD dans des pools répliqués et utilisant l’erasure coding. Il est à noter le mode bloc n’est supporté que sur les pools répliqués et pas sur les pools avec erasure coding (Source : Red Hat)





