Explicabilité des IA : quelles solutions mettre en œuvre ?
S’il est communément accepté que les algorithmes de type Machine Learning/Deep Learning fonctionnent comme des boîtes noires, la recherche avance quant à l’explicabilité des résultats délivrés par les IA. Des techniques et frameworks sont en train de s’imposer, mais ceux-ci ont aussi leurs limites.
En mars 2019, le très attendu rapport parlementaire sur l’intelligence artificielle dirigé par Cédric Villani était enfin révélé au public. Le mathématicien pointait notamment les enjeux éthiques de l’IA, soulignant la nécessité de soutenir la recherche sur l’explicabilité des modèles, avec une volonté « d’ouvrir la boîte noire de l’IA ».
Si le mathématicien souhaitait promouvoir la recherche dans cette voie, de nombreux scientifiques des données et entreprises se sont déjà heurtés à ce besoin d’expliquer les résultats de leurs algorithmes d’intelligence artificielle et des modèles établis avec eux. Les scientifiques des données devaient disposer d’outils explicites pour démontrer la pertinence de leurs modèles à leur direction et aux experts métiers.
Dès 2017, le DARPA américain lançait le
programme de recherche XAI
(eXplainable Artificial Intelligence) afin de disposer
de méthodes pour expliquer les résultats délivrés
par les réseaux de neurones.
Certains doivent se limiter à des algorithmes moins performants afin de pouvoir rester en conformité avec la réglementation, comme c’est le cas dans le secteur bancaire. Illustration de l’importance du sujet, en 2017, bien avant le rapport Villani, l’agence de recherche de l’armée américaine, la Darpa, lançait l’initiative XAI (eXplainable Artificial Intelligence), un programme de recherche visant à expliquer les décisions de modèles d’IA réputés comme étant des boîtes noires, les réseaux de neurones. Déjà, l’agence évoquait des implications de cette recherche dans les domaines militaire et sécuritaire, mais aussi dans la médecine, le transport, la finance, le droit.
Contourner le problème en privilégiant les algorithmes interprétables
Tous les algorithmes mis en œuvre par les scientifiques des données ne sont pas des boîtes noires. Certains sont directement interprétables, comme les régressions linéaires, régressions logistiques, les arbres de décision, les systèmes à base de règles de type RuleFit, des classifications basées sur les réseaux Bayesiens ou encore l'algorithme des k plus proches voisins (Knn). Ces modèles sont notamment privilégiés dans les secteurs fortement réglementés comme la finance, la banque, lorsqu’il s’agit de pouvoir démontrer au régulateur pourquoi telle ou telle décision a été prise. « L’avantage d’un modèle interprétable par nature est d’avoir des relations linéaires faciles à décrire » résumait Pietro Turati, consultant sénior, Eleven Strategy Consultants, lors de la conférence AI Paris 2019. « Une variable influe positivement ou négativement sur le résultat, ou le résultat est la succession de règles logiques faciles à expliquer à des experts métiers. Attention, il faut néanmoins y apporter un point d’attention car si c’est facile sur le principe, quand on a des milliers de règles métiers, c’est difficile de les synthétiser pour les expliquer aux experts ».
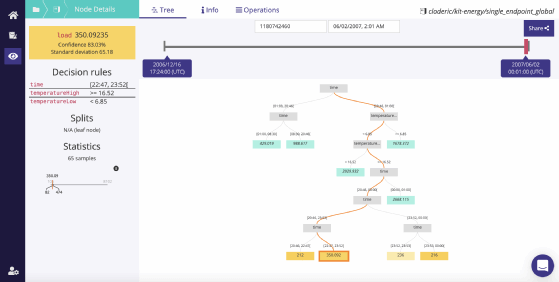
« En nous appuyant sur des arbres de décision, nous avons la garantie de pouvoir expliquer les résultats produits par nos modèles. »
Clodéric MarsDirecteur technique Craft AI
La startup française Craft AI qui s’est positionnée avec une offre d’IA as a Service a fait le choix de limiter son offre à ces modèles explicables. Clodéric Mars, son directeur technique explique ce choix très structurant : « nous avons fait le choix de ne recourir qu’à des modèles complètement explicables. En nous appuyant sur des arbres de décision, nous avons la garantie de pouvoir expliquer les résultats produits par nos modèles. Nous avons fait ce choix car nous ne voulions pas avoir de dichotomie entre le modèle réellement exécuté et le modèle expliqué».
L’expert souligne que les algorithmes d’apprentissage par arbre de décision existent depuis longtemps et qu’il en existe de multiples implémentations. C’est notamment le cas dans Scikit-learn, une librairie Python open source, développée par Inria et très populaire auprès des scientifiques des données. Cependant, ces implémentations, et plus généralement la recherche autour de l’apprentissage par arbres de décision, n’ont pas évolué depuis longtemps.
« Ces domaines de l’IA sont moins actifs que l’apprentissage profond appliqué à la reconnaissance d’image, par exemple », déplore Clodéric Mars. « Depuis 4 ans qu’existe Craft AI, nous avons réalisé un gros effort de R&D, notamment afin d’améliorer les algorithmes de base d’arbres de décision et augmenter leurs performances dans le cas d’usage qui nous intéresse, celui des séries temporelles. C’est un effort qui se poursuit et s’intensifie aujourd'hui. Nous avons fait le choix de publier un certain nombre de nos résultats et le sens de notre offre d’IA explicable "As a Service" est d’industrialiser et de rendre ces algorithmes accessibles aux entreprises ».
L’éditeur travaille sur cette problématique de l’IA explicable dans le cadre du pôle Systematic, mais aussi en tant que membre fondateur d'Impact IA, une initiative lancée par Microsoft et quelques grands groupes comme Axa, et s’intéresse à l’éthique de l’IA. « Dans ce cadre, l’explicabilité est un facilitateur, car elle permet de valider qu’une IA respecte des règles éthiques, que celle-ci n’est pas affligée d’un biais quelconque ».
Craft AI privilégie les arbres de décision afin de proposer des modèles d’IA explicables aux clients de ses API d’intelligence artificielle.
Des modèles qui expliquent des modèles…
L’éventail des algorithmes interprétables “by design” est toutefois limité. Beaucoup d’entreprises cherchent à obtenir de meilleures performances en optant pour des algorithmes plus complexes, les fameuses boîtes noires. Il existe plusieurs techniques afin d’augmenter l’interprétabilité des modèles produits avec ces algorithmes. « Une autre approche consiste à ajouter une surcouche d’explicabilité à des systèmes », explique Nicolas Maudet, professeur au LIP6 (Laboratoire de recherche en informatique) à Sorbonne Université, et co-animateur d'un groupe de travail sur l'explicabilité au sein du GDR IA, le groupement de recherche de l’Institut des Sciences de l’Information et de leurs Interactions (INS2I) du CNRS. « Cette surcouche va délivrer à l’utilisateur des éléments qui lui permettront de comprendre le résultat délivré par le modèle, en identifiant par exemple des variables importantes. LIME est un outil qui est très populaire actuellement dans cette optique, l’idée étant d’expliquer un résultat en approximant par une fonction "simple" la fonction de décision du système (qui est elle arbitraire et à laquelle on n'a pas forcément accès) au voisinage du résultat. Il s’agit d’une approximation, mais qui permet de délivrer des éléments de compréhension quant au résultat délivré par le modèle ».
Plusieurs techniques ont émergé afin d’expliquer les résultats produits par les modèles complexes. Pietro Turati distingue deux approches : « une première approche se base sur l’illustration avec des méthodes telles que le Partial Dependance plot (PDP), l’Individual Conditional Expectation (ICE), des méthodes qui délivrent une explication visuelle au comportement du modèle. D’autres approches qui cherchent à montrer l’impact des différentes variables comme c’est le cas des approches par substitution (Surrogate) telles que LIME ou les valeurs de Shapley ».
Une autre classe de méthode s’appuie sur des exemples afin d’expliquer les résultats du modèle. C’est le cas de la technique de Counterfactual Explanation ou de l’Adversarial Example. L’objectif est de chercher à faire comprendre au scientifique des données ou à un expert ce que le modèle a accompli au moyen de quelques exemples. Si toutes ces approches seront utiles aux experts en sciences des données, les méthodes basées sur les exemples sont particulièrement adaptées à la communication entre ces spécialistes et des tiers, estime Pietro Turati : « face aux experts métiers, nous optons pour le Partial Dependency Plot, le modèle de Shapley, le LIME. Pour communiquer avec les clients, nous privilégions le Counterfactual Explanation ». Une limite de ces approches « par l’exemple » reste que les données doivent être facilement compréhensibles par l’expert ou le client, ce qui est loin d’être toujours le cas.
Interprétabilité globale contre interprétabilité locale, 2 usages différents
En effet, s’il existe de multiples méthodes pour interpréter les résultats générés par un modèle d’intelligence artificielle, les experts distinguent deux types d’interprétabilité, selon qu’elle vise à expliquer le comportement de la totalité du modèle, c’est l’interprétabilité globale, à distinguer de l’interprétabilité locale, qui explique un résultat précis. L’interprétabilité globale va permettre de mettre en évidence le poids de chaque variable dans le modèle, et éventuellement de mettre en évidence des relations indirectes entre variables qu’il n’est pas simple de détecter. C’est un moyen précieux pour le scientifique des données d’évaluer la pertinence de ce que le modèle est en train d’apprendre.
L’interprétabilité locale se concentre au niveau d’une seule personne ou d’un seul dossier : on analyse le comportement du modèle sur cette échelle très réduite. C’est une approche particulièrement intéressante en termes d’interaction avec un client ou pour analyser des cas particuliers. Ainsi avec l’approche Counterfactual Explanation, on va chercher l’exemple le plus proche possible du cas étudié mais produisant une réponse différente. Ainsi, l’expert ou le client lui-même va pouvoir identifier quelles sont les différences entre son dossier et un autre. La démarche est très accessible. Un autre avantage de cette approche est de ne pas avoir à trop dévoiler le modèle lui-même.
Avec la méthode Partial Dependency Plot, le scientifique des données va pouvoir montrer quel est le comportement moyen d’une variable sur le modèle, comme mettre en évidence comment le patrimoine immobilier de l’emprunteur va faire baisser le risque pour la banque, par exemple. Cela peut parfois souligner un comportement auquel on ne s’attend pas et aussi enrichir fortement la discussion avec les experts.
Autre approche, la valeur de Shapley, dont l’objectif est de donner l’idée de la position d’une personne par rapport à la totalité de la population. « On évalue un risque moyen et on distingue la contribution de chaque variable par rapport à la population dans sa globalité. Cela permet d’expliquer facilement au client pourquoi son prêt a été refusé ».
Une autre méthode s’avère intéressante dans le dialogue avec un client, c’est la méthode LIME (ou Local Surrogate). Celle-ci s’applique autant à du texte, qu’à des images et des données tabulaires, et présente l’atout d’être agnostique vis-à-vis du modèle d’apprentissage automatique lui-même. Elle consiste à faire une approximation linéaire du modèle localement, ce qui permet de mettre en évidence quelles variables peuvent être ajustées pour obtenir un meilleur résultat.
De multiples implémentations sont déjà disponibles, mais…
Il existe aujourd’hui des implémentations de toutes ces méthodes facilement accessibles à tous les scientifiques des données. LIME dispose ainsi de plusieurs implémentations en Python et R et les éditeurs reprennent à leur compte ces approches. Lors du SAS Forum 2019, Randy Guard, Chief Marketing Officer de SAS confiait à la rédaction de LeMagIT : « nous voulons délivrer à nos clients des réponses dans le domaine du Machine Learning et notamment de l’interprétabilité afin de pouvoir comprendre ce que les modèles délivrent. Des standards sont en train d’émerger tels que ICE, LIME, DPD, des modèles standards qui permettent de comprendre ce que les modèles de Machine Learning délivrent et nous fournissons de tels modèles aux entreprises ».
De nombreux autres éditeurs ont emboité le pas de SAS, notamment Microsoft qui a publié sur Github la librairie Machine Learning Interpretability Explainability créée en Python pour son SDK Azure Machine Learning. Celui-ci propose une large gamme de méthodes d’explicabilité dont l’approche LIME, l’algorithme d’estimation de valeur SHAP, en tout une dizaine de méthodes prêtes à l’emploi. Autre illustration, IBM qui a lancé un package “Trust and Transparency for AI” sur IBM Cloud en 2018, un ensemble d’outil permettant d’analyser les résultats délivrés par IBM Watson mais aussi Tensorflow, SparkML, AWS SageMaker, and AzureML, qu’il s’agisse de mettre en avant le poids de chaque variable dans une décision ou mettre en évidence les biais d’un modèle.
IBM propose des outils graphiques permettant d’expliquer les résultats produits par des modèles d’intelligence artificielle, un moyen pour les scientifiques de données de dialoguer avec les experts métiers.
Si les éditeurs et les consultants poussent en faveur de ces approches pour débloquer les verrous qui les freinent dans la mise en œuvre de modèles très performants, le recours à des méthodes d’explicabilité présente quelques conséquences pour les entreprises. D’une part, celles-ci vont devoir tenir compte du surcoût induit par ces surcouches, notamment lorsque de très gros volumes de données sont en jeu. Pietro Turati le souligne : « en termes de coûts opérationnels, il faut tenir compte du fait que ces méthodes sont basées sur des simulations. Et, si jusqu’à présent on ne devait exécuter le modèle qu’une fois pour obtenir une réponse, il faut faire tourner 5 fois le même modèle pour pouvoir délivrer une explication. C’est un surcoût qu’il convient de prévoir ».
Plus grave, les méthodes d’explicabilité de type LIME ou SHAP bénéficient déjà de nombreuses implémentations mais font l’objet de critiques sévères des experts. Ainsi, Clodéric Mars de Craft AI souligne que « les algorithmes d’explicabilité a posteriori, comme LIME ou SHAP n’offrent aucune garantie que les explications délivrées correspondent au fonctionnement du modèle lui-même ». De son côté, Nicolas Maudet estime que la pertinence de ces approches reste très dépendante de l’application et de son cadre d’utilisation : « dans certains cas, ce genre d’explication est tout à fait acceptable, mais c'est loin d'être systématique. En effet, dans la mesure où celles-ci ne sont pas totalement fidèles à la manière dont le système a effectivement pris sa décision, elles peuvent être trompeuses, et elles ne permettent pas forcément de corriger la décision, ou de modifier le système. Pire, fournir de telles explications peut parfois être contre-productif, dans la mesure où cela crée une confiance indue dans le système et peut dédouaner de fournir des garanties plus strictes ».
Un récent article paru dans Nature Machine Intelligence critique violemment cette approche. Son auteur, Cynthia Rudin, une chercheuse de la Duke University, milite pour ne pas utiliser d’algorithmes de type boîte noire pour toute décision critique et s'abstenir de le faire sans avoir montré au préalable qu'un modèle interprétable existant ne pourrait pas donner des résultats comparables. Selon elle, il est donc important que toute la recherche ne se focalise pas sur ce type d'approches.
Si les chercheurs restent encore partagés sur l’usage d’algorithmes boîtes noires en soulignant les biais introduits par les algorithmes d’interprétabilité, c’est bien le cas d’usage qui doit dicter le choix du modèle. Opter pour une boîte noire pour obtenir plus de performances pour la fonction de recommandation d’achat d’un site web ou un meilleur ciblage publicitaire reste concevable ; le seul risque étant de ne pas obtenir une performance optimale.
Mais dès lors que le modèle doit piloter un process industriel critique, diagnostiquer une maladie ou tout simplement qu’il va falloir expliquer le modèle à un client ou à un régulateur, il sera nécessaire d’arbitrer entre le recours à un modèle explicable by-design ou celui de techniques d’explicabilité potentiellement discutables.


 Dès 2017, le DARPA américain lançait le
Dès 2017, le DARPA américain lançait le